Cognite API (v1)
Download OpenAPI specification:Download
This is the reference documentation for the Cognite API with an overview of all the available methods.
Select the Download button to download our OpenAPI specification to get started.
To import your data into Postman, select Import, and the Import modal opens. You can import items by dragging or dropping files or folders. You can choose how to import your API and manage the import settings in View Import Settings.
In the Import Settings, set the Folder organization to Tags, select Enable optional parameters to turn off the settings, and select Always inherit authentication to turn on the settings. Select Import.
Set the Authorization to Oauth2.0. By default, the settings are for Open Industrial Data. Navigate to Cognite Hub to understand how to get the credentials for use in Postman.
For more information, see Getting Started with Postman.
Most resource types can be paginated, indicated by the field nextCursor in the response.
By passing the value of nextCursor as the cursor you will get the next page of limit results.
Note that all parameters except cursor has to stay the same.
As general guidance, Parallel Retrieval is a technique that should be used when due to query complexity, retrieval of data in a single request is significantly slower than it would otherwise be for a simple request. Parallel retrieval does not act as a speed multiplier on optimally running queries. By parallelizing such requests, data retrieval performance can be tuned to meet the client application needs.
CDF supports parallel retrieval through the partition parameter, which has the format m/n where n is the amount of partitions you would like to split the entire data set into.
If you want to download the entire data set by splitting it into 10 partitions, do the following in parallel with m running from 1 to 10:
- Make a request to
/eventswithpartition=m/10. - Paginate through the response by following the cursor as explained above. Note that the
partitionparameter needs to be passed to all subqueries.
Processing of parallel retrieval requests is subject to concurrency quota availability. The request returns the 429 response upon exceeding concurrency limits. See the Request throttling chapter below.
To prevent unexpected problems and to maximize read throughput, you should at most use 10 partitions.
Some CDF resources will automatically enforce a maximum of 10 partitions.
For more specific and detailed information, please read the partition attribute documentation for the CDF resource you're using.
Cognite Data Fusion (CDF) returns the HTTP 429 (too many requests) response status code when project capacity exceeds the limit.
The throttling can happen:
- If a user or a project sends too many (more than allocated) concurrent requests.
- If a user or a project sends a too high (more than allocated) rate of requests in a given amount of time.
Cognite recommends using a retry strategy based on truncated exponential backoff to handle sessions with HTTP response codes 429.
Cognite recommends using a reasonable number (up to 10) of Parallel retrieval partitions.
Following these strategies lets you slow down the request frequency to maximize productivity without having to re-submit/retry failing requests.
See more here.
This API uses calendar versioning, and version names follow the YYYYMMDD format.
You can find the versions currently available by using the version selector at the top of this page.
To use a specific API version, you can pass the cdf-version: $version header along with your requests to the API.
The beta versions provide a preview of what the stable version will look like in the future. Beta versions contain functionality that is reasonably mature, and highly likely to become a part of the stable API.
Beta versions are indicated by a -beta suffix after the version name. For example, the beta version header for the
2023-01-01 version is then cdf-version: 20230101-beta.
Alpha versions contain functionality that is new and experimental, and not guaranteed to ever become a part of the stable API. This functionality presents no guarantee of service, so its use is subject to caution.
Alpha versions are indicated by an -alpha suffix after the version name. For example, the alpha version header for
the 2023-01-01 version is then cdf-version: 20230101-alpha.
Agents API
Added
- Added support for interactive message types in the Agent API, enabling bidirectional communication between agents and clients. Agents can now request clients to execute actions, and clients can respond with action messages containing the results.
Cognite Functions
Removed
- Python 3.9 (py39) is no longer supported as a runtime argument for Cognite functions.
Data Modeling API
Added
- Added
statefield to constraints returned from the service, describing whether the constraint is validated or failed. - Added
statefield to indexes returned from the service, describing whether the index is successfully built, or if building failed. - Added fields
maxListSizeandmaxTextSizeto theconstraintStatefield in properties returned from the service, describing whether the associated property-level constraints are valdiated or failed.
Agent APIs (beta)
Deprecated
agentIdin the/ai/agents/chatendpoint has been deprecated in favor ofagentExternalId.agentIdwill be retired from 2025-11-29.
Removed
- Gemini 1.5 Pro and Gemini 1.5 Flash have been retired as model options.
Time Series API
Changed
- Increased the maximum length of string data points from 255 characters to 1023 bytes (UTF-8 encoded).
Data Modeling API
Added
- Added field
constraintStateto properties returned from the service, describing the state of any property-level constraints. Currently includes the fieldnullabilitywhich tracks the state of any non-null constraint.
Default runtime in Cognite functions
Changed
- Default Python runtime in Cognite functions has been updated from Python 3.11 (py311) to Python 3.12 (py312).
Data Modeling API
Added
- Added a
debugparameter to the/models/instances/query,/models/instances/sync, and/models/instances/listendpoints. - The feature returns
noticesproviding insights into query execution, which can be used for performance analysis and optimization.
Data sets API
Fixed
- Add length constraints on
nameanddescriptionfields for the/updateendpoint to disallow empty strings.
3D API
Added
- Added 3D API endpoints to create and delete point cloud volume contextualization connections to CogniteAsset instances. These endpoints are only available in DataModelOnly projects. Currently available in beta.
POST /3d/contextualization/pointcloudPOST /3d/contextualization/pointcloud/delete
Agent APIs (beta)
Added
- New OpenAI models:
azure/o3,azure/o4-mini,azure/gpt-4.1,azure/gpt-4.1-nano,azure/gpt-4.1-mini,azure/gpt-5,azure/gpt-5-mini,azure/gpt-5-nano - New Gemini models:
gcp/gemini-2.5-pro,gcp/gemini-2.5-flash - New AWS models:
aws/claude-4-sonnet,aws/claude-4-opus,aws/claude-4.1-opus
Note: Availability of models may differ between the chosen cloud provider and region of the CDF cluster.
Improved
- Various improvements to the Agent APIs after feedback from the initial alpha release. The Agent APIs (
/ai/agents) to programmatically build and interact with Atlas agents are now in beta state.
Simulator integration API
Changed
- Introduced limits for number of simulator nodes and edges in a simulator model revision flowsheet, as well as number of properties per node. (Alpha feature)
- Support multiple flowsheets in a simulator model revision data. (Alpha feature)
IAM (Identity and access management)
Added
- The following endpoints (all under https://auth.cognite.com) are added:
/api/v1/orgs/{org}/principals/{principal}/sessions: List login sessions for a user principal in an organization./api/v1/orgs/{org}/principals/{principal}/sessions/revoke: Revoke one or more login sessions for a user principal in an organization.
3D API
Added
- Added support in the create 3D asset mappings endpoint for creating asset mappings for 3D CAD
nodeIdand CogniteAssetassetInstanceIdpairs. This creates connections between instances in data modelling and 3D CAD nodes. Only available in Hybrid and DMSFirst CDF projects. - Added support in the list 3D asset mappings endpoint for listing
assetInstanceIdbased mappings, enabled with thegetDmsInstances=trueparameter.
Data Modeling API
Added
- Added
modeto table expressions in the/syncendpoint, to select between sync modes:onePhase(default, current behavior): All instances are returned while following the cursortwoPhase: Existing instances are returned first, then new instances are returned by following the cursornoBackfill: Existing instances are not returned, only new instances are yielded by following the cursor.
- Added
backfillSortto table expressions in the/syncendpoint, to optionally specify how to sort existing instances withsyncMode: twoPhase.
IAM (Identity and access management)
Added
- Added
attributesto group creation in the POST/api/v1/projects/:project/groupsendpoint to set attributes for groups.
Data Modeling API
Added
- Add
allowExpiredCursorsAndAcceptMissedDeletesflag to the/syncendpoint.
Agent APIs
Fixed
- Removed the duplicate
/api/v1/projects/{projectName}prefix from all agents endpoints.
Documents AI API
Fixed
- Removed the duplicate
/api/v1/projects/{projectName}prefix from all documents AI endpoints.
Simulator integration API
Changed
- Introduced request body size limits for the simulator integration API endpoints.
POST /simulators/routines/revisionsto create simulator routines revisions: 50KBPOST /simulators/runto run a simulation: 50KB- In addition, the simulator connector won't be able to send more than 100KB of data in a single run. See the Simulator integration API documentation for more details.
Simulator integration API
Changed
- The API now accepts empty strings for simulation values (inputs and outputs). Previous restriction on "STRING" values to have a minimum length of 1 character has been removed.
3D API
Added
- The 3D API now supports filtering nodes within a boundingbox in dm-only projects.
- The following endpoint is now available:
POST /3d/nodes/listto filter nodes within an area definition.
- The following endpoint is now available:
3D Api
Added
- The 3D Jobs API is extended to include the job result and job result rejections endpoints.
- The following endpoints are now available:
POST /3d/job/results/listto list the results of a jobPOST /3d/job/result/rejectionsto add or remove job result rejectionsPOST /3d/job/result/rejections/listto list job result rejections
- The following endpoints are now available:
3D Api
Added
- The 3D Jobs API is now available in DM-Only Projects
- The following endpoints are now available:
POST /3d/jobsto create a 3d jobPOST /3d/jobs/listto list jobsPOST /3d/jobs/deleteto delete jobs
- The following endpoints are now available:
Entity Matching
Changed
- Enforcement of request limits.
POST /context/entitymatching/byidscan retrieve max 1000 models per request.POST /context/entitymatching/updatecan update max 1000 models per request.POST /context/entitymatching/deletecan delete max 1000 models per request.
Agent APIs
Added
- The Agent APIs is now available in Alpha.
- The following endpoints are now available:
POST /ai/agentsto create or update one or more agentsGET /ai/agentsto list all agentsPOST /ai/agents/idsto retrieve one or more agents by externalIdPOST /ai/agents/deleteto delete one or more agents by externalIdPOST /ai/agents/chatto send messages new messages and receive an answer to a specific agent
- The following endpoints are now available:
2025-03-25
Documents AI
Added
- A new field for specifying the language that the answer should be in, added to Documents Summarize endpoint (
/ai/tools/documents/summarize).
Documents API
Added
- Added ability to filter on the
spaceandexternalIdproperties of aninstanceIdobject.
Time Series API
Added
- New aggregates
maxDatapointandminDatapoint, that gives back both the value and the timestamp of the maximum/minimum data point.
PostgreSQL Gateway API
Added
- The PostgreSQL Gateway API is now in General Availability (GA).
- The following endpoints are now available:
POST /postgresgatewayto create postgres users.POST /postgresgateway/deleteto delete postgres users.POST /postgresgateway/listto filter postgres users.GET /postgresgatewayto list postgres users.POST /postgresgateway/byidsto retrieve postgres users by their username.POST /postgresgateway/updateto update postgres users.POST /postgresgateway/tables/{username}to create postgres foreign tables.POST /postgresgateway/tables/{username}/deleteto delete postgres foreign tables.GET /postgresgateway/tables/{username}to list postgres foreign tables.POST /postgresgateway/tables/{username}/byidsto retrieve postgres foreign tables by name.
- The following endpoints are now available:
Principals API
Added
- The Principals API is now generally available.
Deprecated
- The User profiles API is deprecated in favor of the Principals API, which offers a superset of the functionality. The User profiles API will be removed in a future release.
SAP Writeback API
Added
- SAP writeback API reaches General Availability (GA).
- The following endpoints are now available:
GET /writeback/sap/instancesto list SAP instance destinationsPOST /writeback/sap/instancesto create SAP instance destinationsPOST /writeback/sap/instances/deleteto delete SAP instance destinationsPOST /writeback/sap/instances/byidsto retrieve SAP instance destinations by externalIdGET /writeback/sap/endpointsto list SAP endpoint destinationsPOST /writeback/sap/endpointsto create SAP endpoint destinationsPOST /writeback/sap/endpoints/deleteto delete SAP endpoint destinationsPOST /writeback/sap/endpoints/byidsto retrieve SAP instance destinations by externalIdPOST /writeback/sap/endpoints/verifyto verify connectivity between CDF and the SAP endpoint destinationGET /writeback/sap/mappingsto list schema mappingsPOST /writeback/sap/mappingsto create schema mappingsPOST /writeback/sap/mappings/deleteto delete schema mappingsPOST /writeback/sap/mappings/byidsto retrieve schema mappings destinations by externalIdGET /writeback/sap/requeststo list writeback requestsPOST /writeback/sap/requeststo create writeback requests. Maximum concurrent limit of 50 requests per CDF project.POST /writeback/sap/requests/byidsto retrieve writeback requests by externalId
- The following endpoints are now available:
Hosted Extractors API
Added
RESTandEventHubsources and jobs are now in GA.
Simulator integration API
Added
- Simulator integration API reaches General Availability (GA).
- The following endpoints are now available:
POST /simulators/*to access the simulators API and list simulators enabled for the projectPOST /simulators/integrations/*to list simulator connectors and their statePOST /simulators/models/*to create/list/remove simulator models and their revisionsPOST /simulators/routines/*to create/list/remove simulator routines and their revisionsPOST /simulators/runs/*to create/schedule simulation runsPOST /simulators/logs/*to access simulator logs
- The following endpoints are now available:
Documents AI APIs
Added
- Documents AI APIs (
/ai/tools/documents/askand/ai/tools/documents/summarize) reaches General Availability (GA).
User profiles
Added
- Organization principals: get calling principal's profile
Deprecated
GET /api/v1/{projectName}/profiles/meis deprecated in favor of the new endpoint.
Organizations and Projects
Updated
GET /api/v1/orgs/{org}/projects?includeAdminProperties=truenow includesstateanddeletionTime
Hosted Extractors API
Added
- Stabilized the API for
Sources,Mappings,DestinationsandJobs, for MQTT and Kafka extractors. - Promote Rest and EventHub extractors to public beta.
- Support data models in hosted extractors.
AWS Cognito support
Added
- Support creating organization with AWS Cognito as IdP.
POST /api/v1/orgs/{orgId}/orgscan be called to create organization with AWS Cognito as IdP.
Organizations and Projects
Added
- Allow non-admin users to list all projects in an organization.
GET /api/v1/orgs/{orgId}/projectscan be called by all users of an organization.
- Include
apiUrlwhen listing projects in an organization.GET /api/v1/orgs/{orgId}/projectswill includeapiUrlfor each project.
Time Series API
Added
- Introduced support for time series managed by Data modeling in data point subscriptions.
GET subscriptions/memberscan contain members withinstanceId.POST subscriptionscan be used to create subscriptions with an defined set of instance ids.POST subscriptions/updatecan be used to add/remove/set the instance id time series members.
Contextualization / Vision
Added
- Support for Vision endpoints referencing files by data modeling instance IDs, as an alternative to ID and external ID.
Simulator integration API
Added
- The simulator integration API endpoints have now been promoted to public beta. The following is just a brief list of endpoints. Go to the Cognite API reference documentation (beta) to view all endpoints and their functionalities.
POST /simulators/*to access the simulators API and list simulators enabled for the projectPOST /simulators/integrations/*to list simulator connectors and their statePOST /simulators/models/*to create/list/remove simulator models and their revisionsPOST /simulators/routines/*to create/list/remove simulator routines and their revisionsPOST /simulators/runs/*to create/schedule simulation runsPOST /simulators/logs/*to access simulator logs
Contextualization / Engineering diagrams
Added
- Support for detecting tags in diagrams referencing files by data modelling instance ids as an alternative to id and externalId.
Files API
Added
- Add support for
ignoreUnknownIdsto thefiles/deleteendpoint.
SAP Writeback
Added
- SAP Writeback API (Beta)
Time Series API
Added
- Introduces support for Time Series managed by Data modeling.
/timeseries/*endpoints will return data modeling instance Id in time series objects where applicable.POST /timeseries/updatecan be used to update properties of data modeling time series, but only fields that are not managed by data modeling.POST /timeseries/byidscan be used to retrieve time series by instance Id.POST /timeseries/listandPOST /timeseries/aggregatesupport advanced filters withinstanceId.spaceandinstanceId.externalIdfields. (No changes to regular filters)POST /timeseries/data/*can be used with instance Id to ingest/delete/query data points.POST /timeseries/synthetic/querycan lookup by instance Id.
Subscriptions API
Added
- Subscription filters support advanced filters with
instanceId.spaceandinstanceId.externalIdfields. - List subscription members will show time series instance Ids, if available.
Files API
Added
- Introduces support for Files managed by Data modeling, which means following endpoints will allow specifying instance Id
POST /files/uploadlinkto get upload links for filesPOST /files/multiuploadlinkto get multipart upload link for filesPOST /files/completemultipartuploadto complete a multipart file uploadPOST /files/downloadlinkto get download links for filesGET /files/iconto get an image representation of a filePOST /files/byidsto retrieve metadata information about multiple specific filesPOST /files/updateto updates the information for the files
Data Workflows
Added
- subworkflow task: add support for referencing other workflow versions to run as part of a workflow
Data Workflows
Added
- Introduces the trigger resource for Data Workflows, which adds support for scheduling the execution of workflows and the management thereof.
POST /workflows/triggersto create a UNIX cron trigger for a workflowGET /workflows/triggersto list all triggersPOST /workflows/triggers/deleteto delete a triggerGET /workflows/triggers/{triggerExternalId}/historywhich keeps a ledger of when the trigger fired and if it successfully started a workflow or not.
Organizations and Projects
Added
- Selected endpoints are promoted from beta to v1 (all under https://auth.cognite.com; note that the routes are
different from the beta routes, and that some request and response signatures have changed):
GET /api/v1/orgs/{orgId}to get organization infoPOST /api/v1/orgs/{orgId}/orgsto create an organizationPOST /api/v1/orgs/{orgId}/deleteto delete an organizationGET /api/v1/orgs/{orgId}/orgsto list the child organizations of an organizationPOST /api/v1/orgs/{orgId}/projectsto create a project in an organizationGET /api/v1/orgs/{orgId}/projectsto list the projects in an organization
Deprecated
- The six beta endpoints that have been published as new V1 endpoints (just above) are deprecated and will be removed in a future release.
Data Modeling
Added
- Support for creating properties of type
direct_relation[], allowing direct relations to point to multiple nodes. - /containers/inspect endpoint to retrieve information about which views map a container.
- /instances/inspect endpoint to retrieve information about which containers an instance has data in.
Organizations and Projects
Added
- Projects API (Beta): Allow for parametrization of the initial admin group when creating a project.
Time Series
Added
- Time zone aware aggregate queries. Align aggregates with a given time zone. Also works with half-hour offsets like Asia/Kolkata (UTC+5:30). Takes DST transitions into account.
- New
month(mo) granularity. - Also applies to synthetic time series.
Organizations and Projects
Added
- Organizations API (Beta): create, list, and delete CDF organizations
- Organizations API (Alpha): update CDF organizations
- Projects API (Beta): create and list projects in CDF organizations
User profiles
Added
- Organization user profiles (Beta): list users in CDF organizations
Projects
Removed
- Removed the previous Projects API from public documentation, as those endpoints are available to Cognite and resellers only.
Time series
Added
- Beta support for time zone aware aggregate queries. Align aggregates with a given time zone. Also works with half-hour offsets like Asia/Kolkata (UTC+5:30). Takes DST transitions into account.
- Beta support for new
month(mo) granularity. - Also applies to synthetic time series.
Groups
Added
- Introduce the option to manage members of a group through CDF instead of through external groups in the identity provider. This is done through the new
membersfield on the group object. Members can either be explicitly enumerated or one declare a group to include all users accounts. The latter is useful if one wants all existing users and new users who joins a project to automatically receive certain capabilities.
Engineering diagrams (beta)
Added
- Beta endpoint for retrieving ocr data for a file per page. Currently, only files that have been run through diagram/detect will give any results. This may be up for change in the future. The endpoint replaces a previous playground endpoint which is no longer documented.
Default runtime in Cognite functions
Changed
- Default Python runtime in Cognite functions has been updated from Python 3.8 (py38) to Python 3.11 (py311) in response to the upcoming end of community support for Python 3.8 in October 14, 2024.
Files
Updated
- Files API rate and concurrency limits have been documented. -- Service layer request rate and concurrency limits added -- CRUD endpoints request rate, concurrency and items rate limits added -- Analytic endpoints request rate, concurrency rate limits added
Assets
Updated
- Assets API rate and concurrency limits have been documented. -- Service layer request rate and concurrency limits added -- CRUD endpoints request rate, concurrency and items rate limits added -- Analytic endpoints request rate, concurrency and items rate limits added
Data Modeling
Added
Conversion between unit types for returned values during filter and query operations.
- Trigger conversion by setting the
targetUnitbyexternalIdorunitSystemNameparameters for the data source in a query. - When using filters with unit conversion, the unit for filter value is determined by the corresponding property in the
sourceobject. When querying data in centimeters by settingtargetUniton a property in thesource, the filter value for that property will also be considered to be in centimeters. typing-type.uniton a property in atypingobject is now always the same as the unit for the returned data.- Added
typingto following endpoints:- query
- sync
- aggregate
- search
Time series
Added
- Data point subscriptions reaches General Availability (GA).
- Use the new Data point subscriptions feature to configure a subscription to listen to changes in one or more time series (in ingestion order). The feature is intended to be used where data points consumers need to keep up to date with changes to one or more time series without the need to read the entire time series again.
Hosted Extractors
Changed
hostin kafka sources has been replaced withbootstrapBrokers, which is an array of objects withhostandport.
Synthetic time series
Added
- Support for unit conversion by setting
targetUnitortargetUnitSystemon time series or aggregates with a compatibleunitExternalIdfield.
Sessions
Added
- Support for creating one-shot sessions by setting the
oneshotTokenExchangeflag. One-shot sessions are short-lived sessions that are not refreshed and do not require support for token exchange from the identity provider.
Data Modeling
Added
- Support for a
bySpaceflag on btree indexes and uniqueness constraints.
Data Modeling
Added
- Units catalog support for container properties: You can now specify a unit from CDF units catalog on
float32andfloat64properties in containers.
Time series
Changed
- Data point subscriptions list data (beta) now supports long polling through the
pollTimeoutSecondsparameter. The request will be kept active for the specified number of seconds, or until new data is available, whichever comes first.
Time series
Added
- Units catalog support to time series. This comes in addition to the existing free-text unit field.
- Create timeseries with a unitExternalId.
- Update timeseries to add/remove unitExternalId.
- Filter and aggregate time series by unitExternalId or unitQuantity (eg. "volume" or "temperature"). Both using regular filters and advanced filters.
- Added unit conversion support to retrieve data points/aggregates and retrieve latest. Specify a targetUnit or targetUnitSystem to convert the data points or aggregates to a different unit, or to the default unit of a given unit system.
Hosted extractors
Changed
- Hosted extractors API (Beta)
- Updates hosted extractor schema with tls certificate details hence users can now provide CA and authentication certificates for connection to MQTT brokers.
- Now includes schema requirements for connection to Kafka brokers i.e. connection to and extraction from Kafka brokers to Cognie Data fusion is not possible.
Units Catalog
Added
- Added the Units Catalog API. The Units Catalog is a collection of units of measurement and their conversion factors. The Units Catalog is used within Cognite Data Fusion to easily convert between different units and unit systems when retrieving Time Series and Data Models.
Documents
Added
- Added support for sorting in the
/documents/listendpoint. It works exactly the same as the sorting in/documents/searchexcept that you can not sort on search relevance.
Engineering diagrams
Changed
- Optional token mechanism for accessing detected results of engineering diagrams without read all access to assets. See diagram/detect for details.
Files
Added
- Added multipart upload endpoints for the files API. This enables upload of files larger than 5 GiB, in a uniform way for all CDF cloud environments.
Optionally use parallel part upload, for greater upload speed.
See the documentation for the new endpoints at:
- Upload multipart file and
- Complete multipart upload endpoints.
Events
Added
- New and old but previously undocumented API rate and concurrency limits have been documented.
Overrides have been specified for existing customers, so that the new limits would not affect them.
- Service layer request rate and concurrency limits added.
- CRUD endpoints request rate and concurrency and items rate limits added
Entity matching
Added
- Entity matching pipelines are now in v1. We resuscitated the old playground API and made some changes. We will keep the new v1 API in beta for the foreseeable future.
Vision (Contextualization)
Added
- New computer vision models (beta) are available in Vision extract service, including digital, dial and level gauge readers, valve state detection (open/closed) and model to segment objects in images.
Hosted extractors
Added
- Hosted extractors API (Beta)
- Use the new Hosted extractors feature to create simple streaming extractors running inside CDF, streaming data from sources available on the internet directly into CDF. Currently supports Azure Event Hub and MQTT. Support is planned for Kafka and REST APIs.
3D
Changed
- If the 3d model processing is ongoing or has failed, the 3d api nodes endpoints will now return error code 400 with the response body "Revision processing is not yet complete" or "Revision processing failed" respectively. The previous behavior was to return an empty or partial items list in these cases. Before calling any 3d api nodes endpoints, clients should check that the model revision has "status":"Done".
Transformations
Changed
- Fixed wrong description for fields in "transformations/update" and "/transformations/schedules/update"
Functions
Changed
- Remove Functions runtime "py37".
2023-08-22
Time series
Added
- Data point subscriptions (Beta)
- Use the new Data point subscriptions feature to configure a subscription to listen to changes in one or more time series (in ingestion order). The feature is intended to be used where data points consumers need to keep up to date with changes to one or more time series without the need to read the entire time series again. (Beta)
Time series
Added
- Advanced query language support reaches General Availability (GA).
- Advanced search, filtering, and sorting capabilities in the Filter time series endpoint.
- Advanced aggregation capabilities in the Aggregate time series endpoint.
Sequences
Added
- Advanced query language support reaches General Availability (GA).
- Advanced search, filtering, and sorting capabilities in the Filter sequences endpoint.
- Advanced aggregation capabilities in the Aggregate sequences endpoint.
Assets
Added
- Advanced query language support reaches General Availability (GA).
- Advanced search, filtering, and sorting capabilities in the Filter assets endpoint.
- Advanced aggregation capabilities in the Aggregate assets endpoint.
Events
Added
- Advanced query language support reaches General Availability (GA).
- Advanced search, filtering, and sorting capabilities in the Filter events endpoint.
- Advanced aggregation capabilities in the Aggregate events endpoint.
Documents
Added
- Advanced query language support reaches General Availability (GA).
- Advanced aggregation capabilities in the Aggregate documents endpoint.
IAM (Identity and access management)
Changed
Identity providers (IdP) are required to be compatible with the OpenID Connect Discovery 1.0 standard, and compliance will now be enforced by the Projects API.
- The
oidcConfiguration.jwksUrlandoidcConfiguration.tokenUrlcan be entirely omitted when updating the OIDC configuration for a project. - The
oidcConfiguration.jwksUrlandoidcConfiguration.tokenUrlare preserved for backwards compatibility of the API. However, if these are specified as part of the request body, the value must match excatly the values that are specified in the OpenID provider configuration document for the configured issuer (can be found athttps://{issuer-url}/.well-known/openid-configuration). If the values does not match, the API will return an error message.
- The
The
oidcConfiguration.skewMshas been deprecated but remains part of the API for backwards compatibility. It can be omitted from the request. If included, it must always be set to0.The
oidcConfiguration.isGroupCallbackEnabledhas been deprecated but remains part of the API for backwards compatibility. It can be omitted from the request.- For projects configured to use Azure Active Directory as the identity provider, if this value is specified in the request, it must always be set to
true.
- For projects configured to use Azure Active Directory as the identity provider, if this value is specified in the request, it must always be set to
Data Modeling
Added
- Added support for an
autoCreateDirectRelationsoption on the endpoint for ingesting instances. This option lets the user specify whether to create missing target nodes of direct relations.
Removed
- Removed support for the deprecated per-item
sourcesfield on the/instances/byidsendpoint.
Time series
Added
- Added advanced query language support (Beta).
- Advanced search, filtering, and sorting capabilities in the Filter time series endpoint.
- Advanced aggregation capabilities in the Aggregate time series endpoint.
Sequences
Added
- Added advanced query language support (Beta).
- Advanced search, filtering, and sorting capabilities in the Filter sequences endpoint.
- Advanced aggregation capabilities in the Aggregate sequences endpoint.
Transformations
Removed
- Removing support for authentication via API keys when creating or updating transformations.
Annotations
Added
- Added
image.InstanceLinkanddiagrams.InstanceLinkannotation types to allow you to link from objects discovered in images and engineering diagrams to data model instances.
All resources
Added
- Added information about Requests throttling.
Changed
- Updated the Parallel retrieval documentation.
- Aligned endpoint naming within Assets, Data sets, Events, and Files.
Assets
Added
- Added advanced query language support (Beta).
- Advanced search, filtering, and sorting capabilities in the Filter assets endpoint.
- Advanced aggregation capabilities in the Aggregate assets endpoint.
Events
Added
- Added advanced query language support (Beta).
- Advanced search, filtering, and sorting capabilities in the Filter events endpoint.
- Advanced aggregation capabilities in the Aggregate events endpoint.
Documents
Added
- Added advanced query language support (Beta).
- Advanced aggregation capabilities in the Aggregate documents endpoint.
Sessions
Fixed
Fixed the API documentation for the request body of the POST /projects/{project}/sessions/byids endpoint. The documentation incorrectly stated the request body schema as specifying the list of session IDs to retrieve, in the form
{"items": [42]}- it should in fact be{"items": [{"id": 42}]}. The documentation has been updated to reflect this.Fixed the API documentation for the response body of the POST /projects/{project}/sessions/byids endpoint. The documentation incorrectly stated
nextCursorandpreviousCursorfields as being returned from the response, which was not the case, and these fields have now been removed from the API documentation.
Transformations
Change
- Transformations support new target types for view-centric data model instances.
Added
- Added target types
nodesandedges.
Documents
Change
- Renamed "approximateCardinality" aggregate to "cardinalityValues" to unify the search spec in Cognite.
- "uniqueProperties" aggregate no longer supports pagination. It returns unique properties (up to 10000) in the specified path. The results are sorted by frequency.
Added
- Added "allUniqueProperties" aggregate that returns all unique properties. The response contains a cursor that can be used to fetch all pages of data.
Seismic
Added
- Batch downloading of seismics as a ZIP archive is now an experimental v1 endpoint. A user requires the experimental ACL to use this endpoint, and any other ACLs and scopes to read the downloadable seismics.
Fixed
- The documentation for downloading seismics as SEG-Y files is part of v1. The API documentation didn't reflect that the endpoint had been promoted to version 1.
Documents
Added
- Added
highlightfield in thesearchendpoint to indicate whether matches in search results should be highlighted.
Authentication
Removed
We've removed authentication via CDF service accounts and API keys, and user sign-in via /login.
3D
Added
- Added support for storing translation and scale for model revision.
Documents
Added
- Added the search leaf filter, to allow filtering by searching through specified properties.
Documents
Added
- Added the uniqueProperties aggregation, which can be used to find all the metadata keys in use.
Documents
Added
- Added inAssetSubtree filter to filter documents that have a related asset in a subtree rooted at any of the specified IDs.
Time series
Changed
- Timestamps of data points may now be as large as 4102444799999 (23:59:59.999, December 31, 2099). The previous limit was the year 2050.
Transformations
Added
- Added capability to run a transformation with Nonce credentials provided through the Run endpoint.
IAM (Identity and access management)
Added
- Added the POST /projects/{project}/sessions/byids endpoint.
Time series
Changed
- Updated datapoints timestamp range from 1971 - 2050 to 1900 - 2050. Affected endpoints:
Transformations
Added
- Added authentication using nonce for transformation's exisiting endpoints.
IAM (Identity and access management)
Added
- Added the POST /projects/{project}/sessions/revoke endpoint.
Documents
Added
- Added the
POST /documents/aggregateendpoint. The endpoint allows you to count documents optionally grouped by a property and also to retrieve all unique values of a property.
Documents
Added
- Added the
POST /documents/listendpoint. The endpoint allows you to iterate through all the documents in a project. - Added the
POST /documents/{documentId}/contentendpoint. The endpoint lets you download the entire extracted plain text of a document.
Documents
Added
- Added the GET /documents/{documentId}/preview/image/pages/{pageNumber} endpoint.
- Added the GET /documents/{documentId}/preview/pdf endpoint.
- Added the GET /documents/{documentId}/preview/pdf/temporarylink endpoint.
Sequences
Changed
- Changed sequences column limits. Old limit of maximum total 200 columns limits is updated to maximum 400 total columns, maximum 400 numeric columns and maximum 200 string columns.
Time series
Changed
- Marked
isStepparameter to be editable (i.e. removed description stating it is not updatable) in POST /timeseries/create.
Added
- Added
isStepparameter to theTimeSeriesPatchobject used in POST /timeseries/update
Time series
Added
- Added optional
ignoreUnknownIdsparameter to POST /sequences/delete. Setting this to true will prevent the operation from failing if one or more of the given sequences do not exist; instead, those given sequences that do exist will be deleted.
Transformations
Added
- New Transformations APIs to v1 to create,retrieve,list and delete transformations
- New Transformation Jobs APIs to v1 to retrieve and list transformation jobs or job metrics
- New Transformation Schedule APIs to v1 to manage schedules of transformations
- New Transformation Notifications APIs to v1 to manage notifications from transformation job
Contextualization
Added
- Added diagram detect endpoint to v1 to detect annotations in engineering diagrams
- Added diagram detect results endpoint to v1 to get the results from an engineering diagram detect job
- Added diagram convert endpoint to v1 to create interactive engineering diagrams in SVG format with highlighted annotations
- Added diagram convert results endpoint to v1 to get the results for a job converting engineering diagrams to SVGs
Raw
Changed
- To align with Microsoft Azure clusters, table and database names are now sensitive to trailing spaces also in Google Cloud Platform clusters.
Extraction Pipelines
Added
- New Extraction Pipelines resource to document extractors and monitor the status of data ingestion to make sure reliable and trustworthy data are flowing into the CDF data sets.
- API endpoints for creating, managing, and deleting extraction pipelines. Capture common attributes around extractors such as owners, contacts, schedule, destination RAW databases, and data set. Document structured metadata in the form of key-value attributes as well unstructured
documentationattribute that supports Markdown (rendered as Markdown in Fusion). - Extraction Pipelines Runs are CDF objects to store statuses related to an extraction pipeline. The supported statuses are:
success,failureandseen. They enable extractor developers to report status and error message after ingesting data. As well enables for reporting heartbeat throughseenstatus by the extractor to easily identify issues related to crushed applications and scheduling issues.
Sequences
Added
- Added
partitionparameter to the GET /sequences endpoint to support parallel retrieval. - POST /sequences/list now supports parallel retrieval.
Time series
Added
- Added
partitionparameter to the GET /timeseries endpoint to support parallel retrieval.
IAM (Identity and access management)
Added
Added sessions to v1. Sessions let you securely delegate access to CDF resources for CDF services (such as Functions) by an external principal and for an extended time.
3D
Added
- Added filter3dNodes endpoint to allow for more advanced filtering on node metadata
Sequences
Added
- Added syntax for updating columns of existing sequences. Can
removecolumns,modifyexisting columns, andaddnew columns as well.
Time series
Changed granularity limits on hour aggreagates
You can now ask for a granularity of up to 100000 hours (previously 48 hours), both in normal aggregates and in synthetic time series.
IAM (Identity and access management)
Added
- Added a projects list endpoint to v1
- Added a token inspection endpoint to v1
Authentication
Deprecated
We are deprecating authentication via CDF service accounts and API keys, and user sign-in via /login, in favor of registering applications and services with your IdP (identity provider) and using OpenID Connect and the IdP framework to manage CDF access securely.
The legacy authentication flow is available for customers using Cognite Data Fusion (CDF) on GCP until further notice. We strongly encourage customers to adopt the new authentication flows as soon as possible.
The following API endpoints are deprecated:
/api/v1/projects/*/apikeys/api/v1/projects/*/serviceaccounts/login/logout/api/v1/projects/*/groups/serviceaccounts*
*only the sub-resources for listing, adding, and removing members of groups.
CDF API 0.5, 0.6 reached their end-of-life after its initial deprecation announcement in Summer 2019.
3D
Added
- Added
partitionparameter to the List 3D Nodes endpoint for supporting parallel requests. - Added
sortByNodeIdparameter to the List 3D Nodes endpoint, improving request latency in most cases if set totrue.
Entity matching
Fixed
- Fixed a bug in the documentation for Entity matching. The (job)
statusshall be capitalized string.
Files
Added
- New field
fileTypeinsidederivedFieldsto refer to a pre-defined subset of MIME types. - New filter
fileTypeinsidederivedFieldsto find files with a pre-defined subset of MIME types.
Files
Added
- New field
geoLocationto refer to the geographic location of the file. - New filter
geoLocationto find files matching a certain geographic location.
To learn how to leverage new geoLocation features, follow our guide.
Files
Added
- New field
directoryreferring to the directory in the source containing the file. - New filter
directoryPrefixallows you to find Files matching a certain directory prefix.
Files
Added
- New field
labelsallows you to attach labels to Files upon creation or updating. - New filter
labelsallows you to find Files that have been annotated with specific labels.
IAM (Identity and access management)
Added
- New project field
applicationDomains. If this field is set, users only sign in to the project through applications hosted on a whitelisted domain. Read more.
Events
Added
- New aggregation
uniqueValuesallows you to find different types, subtypes of events in your project.
Labels
Added
- New data organization resource: labels. Manage terms that you can use to annotate and group assets.
Assets
Added
- New filter
labelsallows you to find resources that have been annotated with specific labels.
Time series
Added
- Combine various input time series, constants and operators with on-the-fly synthetic time series.
Events
Added
- New filtering capabilities to find open events
endTime=null. - New filtering capabilities to find all events intersecting a timespan using activeAtTime.
General
Added
- New data organization resource: data sets. Document and track data lineage, ensure data integrity, and allow 3rd parties to write their insights securely back to your Cognite Data Fusion (CDF) project.
- New attribute
datasetIdintroduced in assets, files, events, time series and sequences. - New filter
dataSetIdsallows you to narrow down results to resources containingdatasetIdby a list of ids or externalIds of a data set. Supported by assets, files, events, time series and sequences. - We have added a new aggregation endpoint for time series. With this endpoint, you can find out how many results in a tenant meet the criteria of a filter. We will expand this feature to add more aggregates than
count.
Groups
Added
- Introduced a new capability:
datasetsAclfor managing access to data set resources. - New scope
datasetScopefor assets, files, events, time series and sequences ACLs. Allows you to scope down access to resources contained within a specified set of data sets.
3D
Fixed
- We fixed a bug in the documentation of 3D model revisions. Applications should anticipate that 3D nodes may not have a bounding box.
Assets
Added
- We have added a new aggregation endpoint for assets. With this endpoint, you can find out how many assets in a tenant meet the criteria of a filter. We will expand this feature to add more aggregates than
count.
Events
Added
- We have added a new aggregation endpoint for events. With this endpoint, you can find out how many events in a tenant meet the criteria of a filter. We will expand this feature to add more aggregates than
count.
Assets
Added
- We have added new aggregation properties:
depthandpath. You can use the properties in the filter and retrieve endpoints.
Assets
Added
- Added the property
parentExternalIdwhich is returned for all assets which have a parent with a definedexternalId.
General
Added
- Added
assetSubtreeIdsas a parameter to filter, search, and list endpoints for all core resources.assetSubtreeIdsallows you to specify assets that are subtree roots, and then only retrieve resources that are related to assets within those subtrees.
Assets
Added
- Asset search now has a
search.queryparameter. This uses an improved search algorithm that tries a wider range of variations of the input terms and gives much better relevancy ranking than the existingsearch.nameandsearch.descriptionfields.
Time Series
Changed
- The
search.queryparameter for time series search now uses an improved search algorithm that tries a wider range of variations of the input terms, and gives much better relevancy ranking.
Files
Added
- Added support for updating the
mimeTypefor existing files in files/update requests.
Time Series
Added
Time series expanded their filtering capabilities with new
Filter time seriesendpoint, allowing for additional filtering by:- Name
- Unit
- Type of time series: string or step series
- Metadata objects
- ExternalId prefix filtering
- Create and last updated time ranges
Endpoint in addition support pagination and partitioning. Check out detailed API documentation here.
Sequences
Added
- Introducing the new sequences core resource type that lets you store numerically indexed multi-column rows of data. Connect your sequences to physical assets and to their source systems through
externalIdand metadata support. Read more here.
3D
Added
- Added endpoint to get multiple nodes for a 3D model by their IDs.
- Added endpoint to get asset mappings for multiple node IDs or asset IDs.
Files
Added
- Added support for filter on
rootAssetIdsin files GET /files (using query parameter) and POST /files/list (in request body).
Assets and Events
Added
- Added support for
partitionin/assetsand/eventsto support parallel retrieval. See guide for usage here
3D
Added
- Added the query parameter
intersectsBoundingBoxto the list asset mappings endpoint. The parameter filters asset mappings to the assets where the bounding box intersects (or is contained within) the specified bounding box.
Files
Added
- Added support for sourceCreatedTime and sourceModifiedTime fields in files v1 endpoints.
Assets
Added
- Allow the parent asset ID to be updated. The root asset ID must be preserved, and you can not convert a non-root asset to a root asset or vice versa.
- Support for ignoreUnknownIds when deleting assets.
3D
Added
- Properties field for 3D nodes, extracted from uploaded 3D files.
- Ability to filter nodes with a specific set of properties.
Files
Changed
- Allow lookup of names with length up to 256 characters (was 50) for GET /files and POST /files/search operations.
- Allow creating and retrieving files with mimeType length up to 256 characters (was 64).
Time series
Added
- Added query parameter
rootAssetIdsto list time series endpoint. Returns time series that are linked to an asset that has one of the root assets as an ancestor.
List of changes for initial API v1 release in comparison to previous version - API 0.5
General
Added
- Support for
externalIdadded across resource types.externalIdlets you define a unique ID for a data object. Learn more: External IDs externalIdPrefixadded as a parameter to the list events, assets and files operations.- Richer filtering on the list assets, files and events operations.
- Search, list and filter operations for assets, events and files now support filtering on source and metadata field values.
Changed
- Core resources standardize on HTTP methods and URI naming for common operations such as search, partial updates, delete, list and filter
- API responses are no longer wrapped in a top level
dataobject. - Standardized pagination across resources through
limit,cursorandnextCursorparameters. - The
limitparameter no longer implicitly rounds down requested page size to maximum page size. - Standardized error responses and codes across all resources. Errors across CDF can be parsed into a single model.
- Overall improvements to reference documentation. Including documented input constraints, required fields, individual attribute descriptions.
Removed
- The
sourceIdfield has been removed from resources. UseexternalIdinstead ofsourceId+sourceto define unique IDs for data objects. - Sorting is removed from the search operations for files, assets, events and time series. Results are sorted by relevance.
offsetandpreviousCursorparameters are no longer supported for pagination across resources.- Fetching an asset subtree is no longer supported by files, assets, events and time series.
Assets
Added
- Ability to select only root assets though new
rootfilter. - Added the
rootIdfield to specify the top element in an asset hierarchy. - Added the ability to filter by the root asset ID. This allows you to scope queries for one or many asset hierarchies.
- List Assets allows for filtering assets belonging to set of root assets, specified by list of asset internal ids. New query parameter:
rootIds. - Filter and Search Assets allows or filtering assets belonging to a set of root assets, specified by combination of internal and external asset identifiers. New body attribute:
rootIds.
Changed
- Updating a single asset is no longer supported through a separate endpoint. Use the update multiple endpoint instead.
- Delete assets by default removes only leaf assets (assets without children). New parameter 'recursive' allows for enabling recursive removal of the entire subtree of the asset pointed by ID (API 0.5 behaviour).
Removed
- Overwriting assets is no longer supported.
- Filtering assets by their complete description is no longer supported.
- Locating assets fuzzily by name has been removed. Instead, search for assets on the
nameproperty. - When searching assets, querying over both name and description in the same query is no longer supported.
- The experimental query parameter
boostNamehas been removed from the search for assets operation. - Removed the
pathanddepthfields.
Events
Added
- Events can now be filtered on asset ID in combination with other filters.
- New filter
rootAssetIdsallows for narrowing down events belonging only to list or specified root assets. Supported by Filter and Search API
Removed
- Events can no longer be filtered by empty description.
- The 'dir' parameter has been removed from the search events operation.
Files
Added
- Filtering files by
assetIdsin list files operations now support multiple assets in the same request.
Changed
- Download file content has changed from HTTP GET to HTTP POST method.
- We have renamed the
fileTypefield tomimeType. The field now requires a MIME formatted string (e.g.text/plain). - We have renamed the
uploadedAtfield touploadedTime. - Resumable is now the default behavior for file uploads.
- Update metadata for single files is no longer supported by a separate operation. Instead, use the update multiple operation.
Removed
- Replace files metadata endpoint has been removed.
- Directory has been removed as a property of files.
- Updating the
nameormimeTypeof a file through the update multiple files operation is no longer supported. - Query parameter for specifying the sort direction has been removed from list all files operations.
Raw
Changed
- Raw has changed structure to become resource-oriented. The URL structure has changed.
- Recursively delete of tables and rows when deleting a database is now the default behavior without a control parameter.
Time series
Added
- Support for adding datapoints by
idandexternalIdof time series. Adding datapoints to time series bynamehas been removed. - Add ability to update the new
externalIdattribute for time series. - Allow to set
externalIdduring creation of time series.ExternalIdrequires uniqueness across time series. - Consolidate multiple APIs to allow adding datapoints into a single endpoint. Allows datapoints to be added to multiple time series at the same time.
- Retrieve data points by using
idandexternalIdof the time series. - Time series created through API v1 are not discoverable by API 0.3, 0.4, 0.5 and 0.6 by default. Introduce the option to enable this compatibility by setting new attribute -
legacyNameon time series creation. Value is required to be unique.
Changed
- Get latest datapoints has been reworked. Introduces support for
idandexternalIdlookup as well retrieval for multiple time series within the same request. - Time series name is no longer limited by uniqueness. Note that time series (meta objects) created by API v1 will not be discoverable by older API versions.
- Delete time series endpoint has been redesigned to allow deletion of multiple time series by
idandexternalId. - Delete single and multiple datapoints endpoint has been redesigned and consolidated into a single endpoint. New delete allows selection of multiple time series and time ranges by
idandexternalId. Selecting bynameis no longer available. - Update multiple time series restructured to support lookup by
externalId. - Retrieve time series by ID endpoint restructured adding the ability to get time series by
externalId. - Set limit for data point value to min -1E100, max 1E100.
Removed
- Experimental feature for performing calculations across multiple time series (synthetic time series), function and alias attributes are no longer available.
- The experimental query parameter
boostNamehas been removed from search operation. - Short names for aggregate functions are no longer supported.
- Ability to remove time series by
namehave been removed as names are no longer unique identifiers. - Select multiple time series and time ranges by
nameis no longer available. - The ability to update
isStringandisStepattributes is removed. The attributes are not intended to be modified after creation of time series. - The endpoint for updating single time series is removed. Use the update multiple time series endpoint instead.
- Remove ability to overwrite time series object by
id. Use the update multiple time series endpoint instead. - The ability to retrieve time series matching by
namehas been removed. UseexternalIdinstead. - The ability to retrieve by
idfrom a single time series has been removed. Use retrieve multiple datapoints for multiple time series instead. - The ability to retrieve time-aligned datapoints through "dataframe" API has been removed. Similar functionality is available through our supported SDKs.
- The ability to add datapoints to time series by
namehas been removed. - The ability to look up by time series
namehas been removed.
IAM (Identity and access management)
Added
- The login status endpoint includes the ID of the API key making the request (new attribute:
apiKeyId), if the request used an API key.
Changed
- The user resource type has been replaced with service accounts. Users from previous API versions are equivalent to service accounts.
- Adding, listing and removing users from a group has been replaced by equivalent operations for service accounts.
- Retrieve project returns a single object instead of a list.
- API keys endpoints for list/create rename
userIdattribute toserviceAccountId.
Removed
- List and create groups no longer use the
permissionsandsourceattributes.
3D
Added
- New 3D API lets you upload and process 3D models. Supported format: FBX.
- Ability to create and maintain multiple revisions for the 3D models.
- API for mapping relationships between 3D model nodes and asset hierarchy.
An organization is used to group CDF projects and facilitate their management.
An organization holds users, projects, and perhaps other organizations. The organization ID is what the users enter when logging into Cognite apps, such as Cognite Data Fusion. The organization has one IdP configuration, which is used for both interactive login and service account authentication against all projects in the organization.
External identity providers (IdP)
CDF supports interfacing with external IdPs to manage users and groups. The following vendors are supported:
- Microsoft Entra ID (formerly known as Azure AD or Azure Active Directory)
- Auth0
- Keycloak
Users
If a user can log into the external IdP configured for the organization, then they have access to the CDF organization. Which of the organization's projects they have access to, and what they may do inside those projects, is determined by the access settings within each project.
After a user has logged into the organization for the first time, they will be visible in the organization's user list. Users can see each other, which enables them to collaborate on projects.
Organization hierarchy
An organization can have child organizations. The ownership relationship is materialized through the parentId
field of the organization resource.
Projects
An organization holds CDF projects. The users that are logged into the organization can see all the projects in the organization, but what they can actually do within each project is controlled by the project's access control lists (ACLs) and other access control settings.
Allowed clusters
An organization has a list of clusters on which it can hold projects. This is the allowedClusters field on the
resource.
Organization admins
An organization can have admins, which are identified principals that can perform an extended set of modifications on the organization, such as creating projects, changing who the admins are, and so on.
Admins are identified by the adminGroupId field on the organization resource, which is the ID of a group that is
managed in the external IdP.
The different organization API endpoints have different access rules, which are documented under each endpoint. The general rule is that admins of a given organization have control over most aspects of the organization itself and full control of any sub-organizations.
Authentication for this API
Organizations are global, which means that they are not tied to specific projects or clusters.
API requests against organizations are directed to auth.cognite.com, instead of a specific cluster and projects
as for other resources.
Only OAuth tokens issued by https://auth.cognite.com (such as the ones issued when logging into Fusion) are accepted
by the organizations API.
It is also possible to obtain a token by initiating a login flow against the authorization server directly. See the "Authorizations" sections for more information.
Allow/forbid admins of an organization to create projects
Allow or forbid admins of an organization to create CDF projects anywhere in the subtree of the organization.
Access control
Requires the caller to be an admin in any of the organization's ancestors.
Example: Assume an organization hierarchy like: org-a -> org-b -> org-c.
To change the access rights for org-c, which means calling 'PUT /orgs/org-c/adminsCanCreateProjectsInSubtree',
the caller must be an admin in org-a, or org-b. Being an admin in org-c does not grant access.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
Request Body schema: application/jsonrequired
A request to allow or forbid admins to create projects
Whether admins of the organization are allowed to create CDF projects in the subtree of the organization.
Responses
Request samples
- Payload
trueAllow/forbid admins of an organization to create sub-organizations
Allow or forbid admins of an organization to create organizations anywhere in the subtree of the organization.
Access control
Requires the caller to be an admin in any of the organization's ancestors.
Example: Assume an organization hierarchy like: org-a -> org-b -> org-c.
To change the access rights for org-c, which means calling 'PUT /orgs/org-c/adminsCanCreateOrgsInSubtree', the
caller must be an admin in org-a, or org-b. Being an admin in org-c does not grant access.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
Request Body schema: application/jsonrequired
A request to allow or forbid admins to create sub-organizations
Whether admins of the organization are allowed to create organizations in the subtree of the organization.
Responses
Request samples
- Payload
trueCreate an organization Deprecated
Create a child organization under the specified organization.
Access control
Requires the caller to be an admin in the parent organization (i.e. the one on the path), or any of its ancestors.
In addition, the flag adminsCanCreateOrgsInSubtree must be set to true in that organization.
Example: Assume an organization hierarchy like: org-a -> org-b -> org-c.
To create a new organization under org-c, which means calling 'POST /api/admin/orgs/org-c/orgs', the caller must be an
admin in org-a, org-b, or org-c.
Also, adminsCanCreateOrgsInSubtree must be true in that same organization.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
Request Body schema: application/jsonrequired
A request to create an organization.
| id required | string [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ The ID of the new organization |
required | AzureAdIdp (object) or Auth0Idp (object) or KeycloakIdp (object) or SAuthIdp (object) or AWSCognitoIdP (object) or OktaIdP (object) (IdentityProvider) |
| migrationStatus | string (MigrationStatus) Value: "EXCLUSIVE_LOGIN" This attribute will be removed in a future version, and it is recommended to not send it in requests and to ignore it in responses. If it is present, the single valid value is equivalent to the attribute being null or absent. |
| adminGroupId | string [ 3 .. 64 ] characters Default: null The ID of a group managed by the external identity provider |
| adminsCanCreateOrgsInSubtree | boolean Default: false Whether admins of the new organization are allowed to create organizations in the subtree of the organization. |
| adminsCanCreateProjectsInSubtree | boolean Default: false Whether admins of the new organization are allowed to create CDF projects in the subtree of the organization. |
| allowedClusters | Array of strings (ClusterName) [^[a-z0-9-]{1,32}$] Default: [] The clusters on which the admins of the organization will be able to create projects.
This must be a (non-strict) subset of the |
Responses
Request samples
- Payload
{- "id": "my-org",
- "migrationStatus": "EXCLUSIVE_LOGIN",
- "adminGroupId": "my-external-group",
- "adminsCanCreateOrgsInSubtree": false,
- "adminsCanCreateProjectsInSubtree": false,
- "allowedClusters": [
- "westeurope-1",
- "asia-northeast1-1"
]
}Response samples
- 201
{- "id": "my-org",
- "parentId": "my-org",
- "migrationStatus": "EXCLUSIVE_LOGIN",
- "adminGroupId": "my-external-group",
- "isDeleted": false,
- "adminsCanCreateOrgsInSubtree": false,
- "adminsCanCreateProjectsInSubtree": false,
- "allowedClusters": [
- "westeurope-1",
- "asia-northeast1-1"
], - "profilesEnabled": true
}Create an organization
Create a child organization under the specified organization.
Access control
Requires the caller to be an admin in the parent organization (i.e. the one on the path), or any of its ancestors.
In addition, the flag adminsCanCreateOrgsInSubtree must be set to true in that organization.
Example: Assume an organization hierarchy like: org-a -> org-b -> org-c.
To create a new organization under org-c, which means calling 'POST /api/v1/orgs/org-c/orgs', the caller must be an
admin in at least one of org-a, org-b, or org-c, and adminsCanCreateOrgsInSubtree must be true in that same organization.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
Request Body schema: application/jsonrequired
A request to create an organization.
required | Array of objects (OrganizationRequestItem) = 1 items |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": "my-org",
- "migrationStatus": "EXCLUSIVE_LOGIN",
- "adminGroupId": "my-external-group",
- "adminsCanCreateOrgsInSubtree": false,
- "adminsCanCreateProjectsInSubtree": false,
- "allowedClusters": [
- "westeurope-1",
- "asia-northeast1-1"
]
}
]
}Response samples
- 201
{- "items": [
- {
- "id": "my-org",
- "parentId": "my-org",
- "migrationStatus": "EXCLUSIVE_LOGIN",
- "adminGroupId": "my-external-group",
- "isDeleted": false,
- "adminsCanCreateOrgsInSubtree": false,
- "adminsCanCreateProjectsInSubtree": false,
- "allowedClusters": [
- "westeurope-1",
- "asia-northeast1-1"
], - "profilesEnabled": true
}
]
}Delete an organization Deprecated
Delete an organization. Users will be locked out of the organization immediately. This also applies to the caller.
The organization cannot contain sub-organizations or projects at the time of deletion.
This is a soft-delete, so Cognite Support can restore the organization in case of accidents.
Access control
Requires the caller to be an admin in the organization, or any of its ancestors.
Example: Assume an organization hierarchy like: org-a -> org-b -> org-c.
To delete org-c, which means calling 'DELETE /api/admin/orgs/org-c', the caller must be an admin in org-a, org-b or
org-c.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
Responses
Delete an organization
Delete an organization. Users will be locked out of the organization immediately. This also applies to the caller.
The organization cannot contain sub-organizations or projects at the time of deletion.
This is a soft-delete, so Cognite Support can restore the organization in case of accidents.
Access control
Requires the caller to be an admin in the organization, or any of its ancestors.
Example: Assume an organization hierarchy like: org-a -> org-b -> org-c.
To delete org-c, which means calling 'POST /api/v1/orgs/org-c/delete', the caller must be an admin in org-a, org-b or
org-c.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
Responses
Response samples
- 200
{ }List child organizations Deprecated
List all child organizations under the specified parent organization.
Access control
Requires the caller to be an admin in the parent organization (i.e. the one on the path), or any of its ancestors.
Example: Assume an organization hierarchy like: org-a -> org-b -> org-c.
To list child organizations under org-b, which means calling 'GET /api/admin/orgs/org-b/orgs', the caller must be an
admin in org-a or org-b.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
Responses
Response samples
- 200
[- {
- "id": "my-org",
- "parentId": "my-org",
- "migrationStatus": "EXCLUSIVE_LOGIN",
- "adminGroupId": "my-external-group",
- "isDeleted": false,
- "adminsCanCreateOrgsInSubtree": false,
- "adminsCanCreateProjectsInSubtree": false,
- "allowedClusters": [
- "westeurope-1",
- "asia-northeast1-1"
], - "profilesEnabled": true
}
]List child organizations
List all child organizations under the specified parent organization.
Access control
Requires the caller to be an admin in the parent organization (i.e. the one on the path), or any of its ancestors.
Example: Assume an organization hierarchy like: org-a -> org-b -> org-c.
To list child organizations under org-b, which means calling 'GET /api/v1/orgs/org-b/orgs', the caller must be an
admin in org-a or org-b.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
Responses
Response samples
- 200
{- "items": [
- {
- "id": "my-org",
- "parentId": "my-org",
- "migrationStatus": "EXCLUSIVE_LOGIN",
- "adminGroupId": "my-external-group",
- "isDeleted": false,
- "adminsCanCreateOrgsInSubtree": false,
- "adminsCanCreateProjectsInSubtree": false,
- "allowedClusters": [
- "westeurope-1",
- "asia-northeast1-1"
], - "profilesEnabled": true
}
], - "nextCursor": "string"
}Retrieve an organization Deprecated
Retrieve an organization by its ID. Contact persons are also included.
Access control
Requires the caller to be an admin in the organization, or any of its ancestors.
Example: Assume an organization hierarchy like: org-a -> org-b -> org-c.
To retrieve org-c, which means calling 'GET /api/admin/orgs/org-c', the caller must be an admin in org-a, org-b or
org-c.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
Responses
Response samples
- 200
{- "id": "my-org",
- "parentId": "my-org",
- "migrationStatus": "EXCLUSIVE_LOGIN",
- "adminGroupId": "my-external-group",
- "isDeleted": false,
- "adminsCanCreateOrgsInSubtree": false,
- "adminsCanCreateProjectsInSubtree": false,
- "allowedClusters": [
- "westeurope-1",
- "asia-northeast1-1"
], - "profilesEnabled": true,
- "contactPersons": [
- {
- "id": 0,
- "email": "user@example.com",
- "name": "string",
- "phone": "string",
- "note": "string"
}
]
}Retrieve an organization
Retrieve an organization by its ID.
Access control
Requires the caller to be an admin in the organization, or any of its ancestors.
Example: Assume an organization hierarchy like: org-a -> org-b -> org-c.
To retrieve org-c, which means calling 'GET /api/v1/orgs/org-c', the caller must be an admin in org-a, org-b or
org-c.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
Responses
Response samples
- 200
{- "id": "my-org",
- "parentId": "my-org",
- "migrationStatus": "EXCLUSIVE_LOGIN",
- "adminGroupId": "my-external-group",
- "isDeleted": false,
- "adminsCanCreateOrgsInSubtree": false,
- "adminsCanCreateProjectsInSubtree": false,
- "allowedClusters": [
- "westeurope-1",
- "asia-northeast1-1"
], - "profilesEnabled": true,
- "contactPersons": [
- {
- "id": 0,
- "email": "user@example.com",
- "name": "string",
- "phone": "string",
- "note": "string"
}
]
}Update the admin group ID for an organization
Update the ID of the externally managed group that contains the organization's admins. Note that if the caller is not a member of the new group, they will lose admin access to the organization immediately.
Access control
Requires the caller to be an admin in the organization, or any of its ancestors.
Example: Assume an organization hierarchy like: org-a -> org-b -> org-c.
To update the admin group ID for org-c, which means calling 'PUT /orgs/org-c/adminGroupId', the caller must be
an admin in org-a, org-b or org-c.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
Request Body schema: text/plainrequired
A request to update the admin group ID of an organization
The ID of a group managed by the external identity provider
Responses
Update the allowed clusters for an organization
Change the clusters on which the admins of the organization will be able to create projects.
The new set must be a (non-strict) subset of the allowedClusters set of the parent organization.
This operation overwrites the currently allowed set of clusters, so make sure to include any clusters you want to keep in the request.
When projects exist
If there are projects in the organization that are not on the new allowed clusters, the operation will fail.
Example: Assume an organization org with allowed cluster [westeurope-1], and one project proj on that
cluster. If the caller tries to remove westeurope-1 from the allowed clusters, the operation will fail,
since proj is on a cluster that would not be allowed anymore.
Cascading removals
When removing a cluster from an organization, it will also be removed from all descendant organizations. This cascading behavior does not apply when adding a cluster.
Example: Assume an organization hierarchy like: org-a -> org-b -> org-c.
The initially allowed clusters are:
org-a: [westeurope-1, asia-northeast1-1]org-b: [westeurope-1, asia-northeast1-1]org-c: [westeurope-1]
Assume a caller changes the allowed clusters for org-a to [asia-northeast1-1]. The new allowed clusters will be:
org-a: [asia-northeast1-1]org-b: [asia-northeast1-1]org-c: []
Access control
Requires the caller to be an admin in any of the organization's ancestors.
Example: Assume an organization hierarchy like: org-a -> org-b -> org-c.
To change the allowed clusters for org-c, which means calling 'PUT /orgs/org-c/allowedClusters', the caller
must be an admin in org-a, or org-b. Being an admin in org-c does not grant access.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
Request Body schema: application/jsonrequired
A request to change the allowed clusters for an organization
| clusters required | Array of strings (ClusterName) [^[a-z0-9-]{1,32}$] |
Responses
Request samples
- Payload
{- "clusters": [
- "westeurope-1"
]
}Response samples
- 200
{- "clusters": [
- "westeurope-1"
]
}Update the IdP configuration for an organization
Update the IdP configuration for an organization. All currently authenticated principals will be logged out immediately, and all tokens will be invalidated, including the caller's.
Warning: If you are performing this operation on your "home" organization (the one for which your token is issued), the IdP update will be done, but the admin group ID will typically not point to a valid group in the new IdP. We recommend that you reach out to Cognite Support if you want to update the IdP of your own organization.
Access control
Requires the caller to be an admin in the organization, or any of its ancestors.
Example: Assume an organization hierarchy like: org-a -> org-b -> org-c.
To update the IdP configuration for org-c, which means calling 'PUT /orgs/org-c/idp', the caller must be an
admin in org-a, org-b or org-c.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
Request Body schema: application/jsonrequired
A request to update the IdP configuration of an organization
| idpVendor required | string Value: "AZURE_AD" |
| issuer required | string <url> The issuer for the external IdP. For Azure AD, it conforms to the example URL and contains the tenant ID. |
Responses
Request samples
- Payload
{- "idpVendor": "AZURE_AD",
}Projects are used to isolate data in CDF from each other. All objects in CDF belong to a single project, and objects in different projects are generally isolated from each other.
(Internal) List projects in an organization
List all projects in the specified organization.
This endpoint is internal and should not be used by external clients. The endpoint is in the v0 API version, and it is not guaranteed to be stable.
Access control
Requires the caller to be authenticated against the queried organization.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
query Parameters
| includeDataModelingStatus | boolean Default: false Whether to include the data modeling status of the projects in the response. |
Responses
Response samples
- 200
{- "items": [
- {
- "name": "publicdata",
- "dataModelingStatus": "DATA_MODELING_ONLY"
}
], - "nextCursor": "string"
}Create a project
Creates new projects given project details. This functionality is currently only available for Cognite and re-sellers of Cognite Data Fusion. Please contact Cognite Support for more information.
Authorizations:
Request Body schema: application/jsonrequired
List of new project specifications
required | Array of objects (NewProjectSpec) |
Responses
Request samples
- Payload
{- "items": [
- {
- "name": "Open Industrial Data",
- "urlName": "publicdata",
- "adminSourceGroupId": "b7c9a5a4-99c2-4785-bed3-5e6ad9a78603",
- "oidcConfiguration": {
- "jwksUrl": "string",
- "tokenUrl": "string",
- "issuer": "string",
- "audience": "string",
- "skewMs": 0,
- "accessClaims": [
- {
- "claimName": "string"
}
], - "scopeClaims": [
- {
- "claimName": "string"
}
], - "logClaims": [
- {
- "claimName": "string"
}
], - "isGroupCallbackEnabled": false,
- "identityProviderScope": "string"
}, - "userProfilesConfiguration": {
- "enabled": true
}, - "parentProjectUrlName": "administrative-project",
- "leafProject": true,
- "reservedPrefix": "test"
}
]
}Response samples
- 201
{- "name": "Open Industrial Data",
- "urlName": "publicdata",
- "oidcConfiguration": {
- "jwksUrl": "string",
- "tokenUrl": "string",
- "issuer": "string",
- "audience": "string",
- "skewMs": 0,
- "accessClaims": [
- {
- "claimName": "string"
}
], - "scopeClaims": [
- {
- "claimName": "string"
}
], - "logClaims": [
- {
- "claimName": "string"
}
], - "isGroupCallbackEnabled": false,
- "identityProviderScope": "string"
}, - "userProfilesConfiguration": {
- "enabled": true
}, - "cogIdpBetaOptIn": true
}Create a project Deprecated
Create a project in the specified organization, in the given cluster. The project is immediately available for login in Cognite applications, for example through Cognite Data Fusion.
Cluster placement
The chosen cluster must be one of the allowed clusters for the organization.
The project cannot be moved to a different cluster after creation, so make sure to choose the correct one with respect to data locality requirements.
Project OIDC configuration
The OIDC configuration will be copied from the immediate parent organization.
The caller can, and should, set an initial admin group ID for the project. That group is managed by the external
identity provider, as for the organization.
If that group is not set, the project will inherit the admin group ID of the organization it's created in.
See the projectAdminGroupId field in the request body for more details on this behavior.
Access control
Requires the caller to be an admin in the organization, or any of its ancestors.
In addition, the flag adminsCanCreateProjectsInSubtree must be set to true in that organization.
Example: Assume an organization hierarchy like: org-a -> org-b -> org-c.
To create a project in org-c, which means calling 'POST /api/admin/orgs/org-c/projects', the caller must be an admin in
org-a, org-b or org-c.
Also, adminsCanCreateProjectsInSubtree must be true in that same organization.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
Request Body schema: application/jsonrequired
A request to create a new project
| name required | string (ProjectUrlName) [ 3 .. 32 ] characters The URL name of the project. This is used as part of the request path in API calls. Valid URL names contains between 3 and 32 characters, and may only contain English letters, digits and hyphens, must contain at least one letter and may not start or end with a hyphen. |
| clusterName required | string (ClusterName) [ 1 .. 32 ] characters ^[a-z0-9-]{1,32}$ A CDF cluster name |
| projectAdminGroupId | string [ 3 .. 64 ] characters The ID of the externally-managed group that contains the project's admins.
|
Responses
Request samples
- Payload
{- "name": "publicdata",
- "clusterName": "westeurope-1",
- "projectAdminGroupId": "my-external-group"
}Response samples
- 201
{- "name": "publicdata",
- "clusterName": "westeurope-1",
- "projectAdminGroupId": "my-external-group"
}Create a project
Create a project in the specified organization, in the given cluster. The project is immediately available for login in Cognite applications, for example through Cognite Data Fusion.
Cluster placement
The chosen cluster must be one of the allowed clusters for the organization.
The project cannot be moved to a different cluster after creation, so make sure to choose the correct one with respect to data locality requirements.
Project OIDC configuration
The OIDC configuration will be copied from the immediate parent organization.
The caller can, and should, set an initial admin group ID for the project. That group is managed by the external
identity provider, as for the organization.
If that group is not set, the project will inherit the admin group ID of the organization it's created in.
See the projectAdminGroupId field in the request body for more details on this behavior.
Access control
Requires the caller to be an admin in the organization, or any of its ancestors.
In addition, the flag adminsCanCreateProjectsInSubtree must be set to true in that organization.
Example: Assume an organization hierarchy like: org-a -> org-b -> org-c.
To create a project in org-c, which means calling 'POST /api/v1/orgs/org-c/projects', the caller must be an admin in
org-a, org-b or org-c.
Also, adminsCanCreateProjectsInSubtree must be true in that same organization.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
Request Body schema: application/jsonrequired
A request to create a new project
required | Array of objects (ProjectCreateRequest) = 1 items |
Responses
Request samples
- Payload
{- "items": [
- {
- "name": "publicdata",
- "clusterName": "westeurope-1",
- "projectAdminGroupId": "my-external-group"
}
]
}Response samples
- 201
{- "items": [
- {
- "name": "publicdata",
- "clusterName": "westeurope-1",
- "projectAdminGroupId": "my-external-group"
}
]
}Delete a project
Deletes the project that matches the provided project named specified by the project path parameter.
Alpha: Project deletion is available only when the cdf-version header with the value alpha is provided.
Authorizations:
Responses
Response samples
- 200
{ }List projects
The list of all projects that the user has the 'list projects' capability in. The user may not have access to any resources in the listed projects, even if they have access to list the project itself.
Authorizations:
query Parameters
| all | boolean If set to |
| withInternalId | boolean If set to |
| withParentProject | boolean If set to If the |
| withState | boolean If set to |
| includeDeleted | boolean If set to |
| isDeleted | boolean If set to |
| withDataModelingStatus | boolean If set to |
Responses
Response samples
- 200
{- "items": [
- {
- "id": 0,
- "parentProjectId": 0,
- "urlName": "publicdata",
- "parentProjectUrlName": "publicdata",
- "leafProject": true,
- "isDeleted": true,
- "deletedTime": 1638795554528,
- "dataModelingStatus": "DATA_MODELING_ONLY"
}
]
}List projects in an organization Deprecated
List all projects in the specified organization.
Access control
Requires the caller to be an admin in the organization, or any of its ancestors.
Example: Assume an organization hierarchy like: org-a -> org-b -> org-c.
To list projects in org-c, which means calling 'GET /api/admin/orgs/org-c/projects', the caller must be an admin in
org-a, org-b or org-c.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
Responses
Response samples
- 200
{- "nextCursor": "string"
}List projects in an organization
List all projects in the specified organization.
Access control
If includeAdminProperties is true, it requires the caller to be an admin in the organization, or any of its ancestors.
Otherwise, it requires the caller to be a member of the organization.
Example: Assume an organization hierarchy like: org-a -> org-b -> org-c.
To list projects in org-c, which means calling 'GET /api/v1/orgs/org-c/projects?includeAdminProperties',
the caller must be an admin in org-a, org-b or org-c.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
query Parameters
| includeAdminProperties | boolean Default: false Whether to include admin properties of the projects in the response. |
Responses
Response samples
- 200
{- "nextCursor": "string"
}Retrieve a project
Retrieves information about a project given the project URL name.
Authorizations:
path Parameters
| project required | string Example: publicdata The CDF project name, equal to the project variable in the server URL. |
Responses
Request samples
- JavaScript SDK
const projectInfo = await client.projects.retrieve('publicdata');
Response samples
- 200
{- "name": "Open Industrial Data",
- "urlName": "publicdata",
- "oidcConfiguration": {
- "jwksUrl": "string",
- "tokenUrl": "string",
- "issuer": "string",
- "audience": "string",
- "skewMs": 0,
- "accessClaims": [
- {
- "claimName": "string"
}
], - "scopeClaims": [
- {
- "claimName": "string"
}
], - "logClaims": [
- {
- "claimName": "string"
}
], - "isGroupCallbackEnabled": false,
- "identityProviderScope": "string"
}, - "userProfilesConfiguration": {
- "enabled": true
}, - "cogIdpBetaOptIn": true
}Update a project
Updates the project configuration.
Warning: Updating a project will invalidate active sessions within that project.
Authorizations:
Request Body schema: application/json
Object with updated project configuration.
required | object (ProjectUpdateObjectDTO) Contains the instructions on how to update the project. |
Responses
Request samples
- Payload
- JavaScript SDK
{- "update": {
- "name": {
- "set": "string"
}, - "parentProjectId": {
- "set": 1
}, - "oidcConfiguration": {
- "modify": {
- "jwksUrl": {
- "set": "string"
}, - "tokenUrl": {
- "set": "string"
}, - "issuer": {
- "set": "string"
}, - "audience": {
- "set": "string"
}, - "skewMs": {
- "set": 0
}, - "accessClaims": {
- "set": [
- {
- "claimName": "string"
}
]
}, - "scopeClaims": {
- "set": [
- {
- "claimName": "string"
}
]
}, - "logClaims": {
- "set": [
- {
- "claimName": "string"
}
]
}, - "isGroupCallbackEnabled": {
- "set": true
}, - "identityProviderScope": {
- "set": "string"
}
}
}, - "isOidcEnabled": {
- "set": true
}, - "leafProject": {
- "set": true
}, - "userProfilesConfiguration": {
- "modify": {
- "enabled": true
}
}, - "reservedPrefix": {
- "set": "test"
}, - "cogIdpBetaOptIn": {
- "set": true
}, - "dataModelingStatus": {
- "set": "DATA_MODELING_ONLY"
}
}
}Response samples
- 200
{- "name": "Open Industrial Data",
- "urlName": "publicdata",
- "oidcConfiguration": {
- "jwksUrl": "string",
- "tokenUrl": "string",
- "issuer": "string",
- "audience": "string",
- "skewMs": 0,
- "accessClaims": [
- {
- "claimName": "string"
}
], - "scopeClaims": [
- {
- "claimName": "string"
}
], - "logClaims": [
- {
- "claimName": "string"
}
], - "isGroupCallbackEnabled": false,
- "identityProviderScope": "string"
}, - "userProfilesConfiguration": {
- "enabled": true
}, - "cogIdpBetaOptIn": true
}Principal is an umbrella term for user accounts and service accounts. Both entities can be uniquely identified, authenticated, and authorized in CDF. Principals are unique within an organization, and therefore also within a project in the organization. Principals can access data and create and run processes (transformations, Functions) in a CDF project.
- A user account is associated with a person who wants to interact with CDF. Each user account has a user profile containing a unique user ID.
- A service account is associated with an application or process that wants to interact with CDF, such as an extractor or Cognite Functions, rather than a person.
Requests to the Principals API are directed to auth.cognite.com, like for organizations.
Only OAuth tokens issued by https://auth.cognite.com (such as the ones issued when logging into Fusion) are accepted
by the Principals API.
It is also possible to obtain a token by initiating a login flow against the authorization server directly. See the "Authorizations" sections for more information.
The Principals API lets you query user accounts in an organization, and retrieve profiles.
Get the current caller's information
Retrieves the information of the principal issuing the request.
This endpoint is useful for clients to verify their own identity. All authenticated principals can call this endpoint.
Authorizations:
Responses
Response samples
- 200
{- "id": "5yAFQRAATb7vtWGp4gvbJD3wE7VS81CGuQ7EZT",
- "type": "SERVICE_ACCOUNT",
- "externalId": "my.known.id",
- "name": "My service account",
- "description": "This is a service account used by data pipeline A-xxx",
- "createdBy": {
- "orgId": "my-org",
- "userId": "-user-string-id-aBc123"
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "pictureUrl": "string"
}List login sessions
List login sessions for a user principal in an organization.
Note that a login session is what a user gets after logging into Fusion, InField, or another Cognite application. It is distinct from the concept of the "sessions" that can be used for background work like Transformations or Functions; however, each such background session is backed by a login session.
This endpoint does not work for service account principals, which do not have login sessions.
Access control
Requires the caller to be an admin of the target organization (it is not sufficient to be an admin of an ancestor organization).
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
| principal required | string (PrincipalId) Example: 5yAFQRAATb7vtWGp4gvbJD3wE7VS81CGuQ7EZT ID of a principal |
query Parameters
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| limit | integer [ 1 .. 1000 ] The maximum number of items to return. |
Responses
Response samples
- 200
- 400
- 403
- 404
{- "items": [
- {
- "id": "aea91e72-a984-4a4c-ba06-a7f54e650825",
- "createdTime": 0,
- "status": "ACTIVE",
- "deactivatedTime": 0
}
], - "nextCursor": {
- "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo"
}
}List principals
List principals in an organization.
All principal types are supported.
Access control
Requires the caller to be logged into the target organization, or to be an admin in any of its the ancestor organizations.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
query Parameters
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| limit | integer [ 1 .. 100 ] |
| types | string (PrincipalType) Enum: "SERVICE_ACCOUNT" "USER" Example: types=USER,SERVICE_ACCOUNT Filter by principal types. If not specified, all principal types will be included. You can filter by multiple types by providing a comma-separated list, or by repeating the parameter. |
Responses
Response samples
- 200
{- "items": [
- {
- "id": "5yAFQRAATb7vtWGp4gvbJD3wE7VS81CGuQ7EZT",
- "type": "SERVICE_ACCOUNT",
- "externalId": "my.known.id",
- "name": "string",
- "description": "This is a service account used by data pipeline A-xxx",
- "createdBy": {
- "orgId": "my-org",
- "userId": "-user-string-id-aBc123"
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "pictureUrl": "string"
}
], - "nextCursor": {
- "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo"
}
}Retrieve principals by reference
Retrieve principals in an organization by ID or external ID.
Service accounts can be retrieved by ID or external ID. Users can be retrieved by ID.
Access control
Requires the caller to be logged into the target organization, or to be an admin in any of its the ancestor organizations.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
Request Body schema: application/jsonrequired
A request to retrieve principals by reference.
For now, only service accounts can have an external ID.
required | Array of ReferenceById (object) or ReferenceByExternalId (object) (ReferenceByIdOrExternalId) [ 1 .. 100 ] items |
| ignoreUnknownIds | boolean Default: false If If |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": "5yAFQRAATb7vtWGp4gvbJD3wE7VS81CGuQ7EZT"
}
], - "ignoreUnknownIds": false
}Response samples
- 200
{- "items": [
- {
- "id": "5yAFQRAATb7vtWGp4gvbJD3wE7VS81CGuQ7EZT",
- "type": "SERVICE_ACCOUNT",
- "externalId": "my.known.id",
- "name": "string",
- "description": "This is a service account used by data pipeline A-xxx",
- "createdBy": {
- "orgId": "my-org",
- "userId": "-user-string-id-aBc123"
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "pictureUrl": "string"
}
]
}Revoke login sessions
Revoke one or more login sessions for a user principal in an organization.
Note that a login session is what a user gets after logging into Fusion, InField, or another Cognite application. It is distinct from the concept of the "sessions" that can be used for background work like Transformations or Functions; however, each such background session is backed by a login session.
Upon successful completion of a login flow, the user receives an access token and a refresh token, which are both associated with the newly established login session. (Note that the user may have multiple concurrent login sessions.) The user may use the access token to send requests to the Cognite API, and the refresh token to obtain a new access token before the current one expires. Refreshing will also produce a new refresh token and invalidate the previous one. Every access token and refresh token in this "chain" is associated with the same login session.
Revoking a login session will set its status to REVOKED (which will be reflected in
/api/v1/orgs/{org}/principals/{principal}/sessions), which within a short amount of time will prevent the user
from accessing the Cognite systems via that login session. Specifically:
- Requests to the Cognite API that use any access token that is associated with this session will be rejected.
- Requests to refresh the login session will be rejected.
- Background jobs that were started from this login session will stop working. Note that this might take up to one hour to take effect.
Note that the user may still have other active login sessions, which will remain active. If you want to
completely prevent a user from accessing Cognite systems, you should remove them from your organization's
external identity provider (e.g. your Entra ID tenant), which will prevent them from logging in again, and then
call /api/v1/orgs/{org}/principals/{principal}/sessions to list all their current login sessions and then pass
all their ids to this endpoint (in batches, if there are more than 10) to revoke them.
Also note that because the REVOKED status is "stronger" than the LOGGED_OUT status (background sessions
remain active in the latter status but not in the former), it is possible to revoke a login session that is
LOGGED_OUT (which will stop any associated background sessions). Currently, REVOKED has the same
consequences as EXPIRED, but revocation might be expanded in the future to become even stronger, so it is also
possible to revoke a login session that is EXPIRED. Revoking a login session that is already REVOKED will
succeed but will have no effect (in particular, the deactivatedTime of the login session will not change).
This endpoint is atomic: if revocation of any of the given login sessions fails, none of the login sessions will be revoked. In other words, any other status code than 204 means that no login sessions were revoked.
This endpoint does not work for service account principals, which do not have login sessions.
Access control
Requires the caller to be an admin of the target organization (it is not sufficient to be an admin of an ancestor organization).
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
| principal required | string (PrincipalId) Example: 5yAFQRAATb7vtWGp4gvbJD3wE7VS81CGuQ7EZT ID of a principal |
Request Body schema: application/jsonrequired
A request to revoke login sessions for a user principal.
required | Array of objects [ 1 .. 10 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": "aea91e72-a984-4a4c-ba06-a7f54e650825"
}
]
}Response samples
- 400
- 403
- 404
{- "code": 0,
- "message": "string"
}Groups are used to give principals the capabilities to access CDF resources. One principal can be a member in multiple groups and one group can have multiple members. Note that having more than 20 groups per principal is not supported and may result in login issues.
Groups can either be managed through the external identity provider for the project or managed by CDF.
- Group Membership Managed Externally: Groups membership is managed by the external identity provider. It is not possible edit or see the members of these groups in CDF.
- Group Membership Managed within CDF: Lets you see and edit group membership in CDF instead of relying on the external identity provider.
Create groups
Creates one or more named groups, each with a set of capabilities. All users with any group membership in a CDF project automatically get the userProfilesAcl:READ capability and can search for other users. If not assigned automatically, user profiles must be enabled for the project. To enable user profiles, contact support.
Authorizations:
Request Body schema: application/jsonrequired
List of groups to create.
required | Array of managedExternally (object) or managedInCDF (object) (GroupSpec) |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
{- "items": [
- {
- "name": "Production Engineers",
- "capabilities": [
- {
- "agentsAcl": {
- "actions": [
- "READ"
], - "scope": {
- "all": { }
}
}, - "projectUrlNames": {
- "urlNames": [
- "publicdata"
]
}
}
], - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "attributes": {
- "token": {
- "appIds": [
- "string"
]
}
}, - "sourceId": "b7c9a5a4-99c2-4785-bed3-5e6ad9a78603"
}
]
}Response samples
- 201
- 400
{- "items": [
- {
- "name": "Production Engineers",
- "capabilities": [
- {
- "agentsAcl": {
- "actions": [
- "READ"
], - "scope": {
- "all": { }
}
}, - "projectUrlNames": {
- "urlNames": [
- "publicdata"
]
}
}
], - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "attributes": {
- "token": {
- "appIds": [
- "string"
]
}
}, - "sourceId": "b7c9a5a4-99c2-4785-bed3-5e6ad9a78603",
- "id": 0,
- "isDeleted": false,
- "deletedTime": 0
}
]
}Delete groups
Deletes the groups with the given IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of group IDs to delete
| items required | Array of integers <int64> non-empty unique [ items <int64 > ] |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
{- "items": [
- 23872937137,
- 1238712837,
- 128371973
]
}Response samples
- 200
{ }List groups
Retrieves a list of groups the asking principal a member of. Principals with groups:list capability can optionally ask for all groups in a project.
Authorizations:
query Parameters
| all | boolean Default: false Whether to get all groups, only available with the groups:list acl. |
Responses
Request samples
- JavaScript SDK
- Python SDK
const groups = await client.groups.list({ all: true });
Response samples
- 200
{- "items": [
- {
- "name": "Production Engineers",
- "capabilities": [
- {
- "agentsAcl": {
- "actions": [
- "READ"
], - "scope": {
- "all": { }
}
}, - "projectUrlNames": {
- "urlNames": [
- "publicdata"
]
}
}
], - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "attributes": {
- "token": {
- "appIds": [
- "string"
]
}
}, - "sourceId": "b7c9a5a4-99c2-4785-bed3-5e6ad9a78603",
- "id": 0,
- "isDeleted": false,
- "deletedTime": 0
}
]
}Manage security categories for a specific project. Security categories can be used to restrict access to a resource. Applying a security category to a resource means that only principals (users or service accounts) that also have this security category can access the resource. To learn more about security categories please read this page.
Create security categories
Creates security categories with the given names. Duplicate names in the request are ignored. If a security category with one of the provided names exists already, then the request will fail and no security categories are created.
Authorizations:
Request Body schema: application/jsonrequired
List of categories to create
required | Array of objects (SecurityCategorySpecDTO) non-empty |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "name": "Guarded by vendor x"
}
]
}Response samples
- 201
{- "items": [
- {
- "name": "Guarded by vendor x",
- "id": 0
}
]
}Delete security categories
Deletes the security categories that match the provided IDs. If any of the provided IDs does not belong to an existing security category, then the request will fail and no security categories are deleted.
Authorizations:
Request Body schema: application/jsonrequired
List of security category IDs to delete.
| items required | Array of integers <int64> non-empty unique [ items <int64 > ] |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- 23872937137,
- 1238712837,
- 128371973
]
}Response samples
- 200
- 400
{ }List security categories
Retrieves a list of all security categories for a project.
Authorizations:
query Parameters
| sort | string Default: "ASC" Enum: "ASC" "DESC" Sort descending or ascending. |
| cursor | string Cursor to use for paging through results. |
| limit | integer <int32> <= 1000 Default: 25 Return up to this many results. Maximum is 1000. Default is 25. |
Responses
Request samples
- JavaScript SDK
- Python SDK
- Java SDK
const securityCategories = await client.securityCategories.list({ sort: 'ASC' });
Response samples
- 200
{- "items": [
- {
- "name": "Guarded by vendor x",
- "id": 0
}
], - "nextCursor": "string"
}Sessions are used to maintain access to CDF resources for an extended period of time. The methods available to extend a sessions lifetime are client credentials and token exchange. Sessions depend on the project OIDC configuration and may become invalid in the following cases
Project OIDC configuration has been updated through the update project endpoint. This action invalidates all of the project's sessions.
The session was invalidated through the identity provider.
Batch Refresh sessions
Authorizations:
Request Body schema: application/json
Array of objects (RefreshSessionRequest) <= 50 items |
Responses
Request samples
- Payload
{- "items": [
- {
- "sessionKey": "string",
- "sessionId": 0
}
]
}Response samples
- 200
{- "items": [
- {
- "id": 0,
- "accessToken": "string",
- "expiresIn": 0,
- "sessionKey": "string",
- "sessionExpirationTime": 0,
- "sessionIsExtendable": null
}
], - "failed": [
- {
- "id": 0,
- "error": "string",
- "code": 0
}
]
}Create sessions
Create sessions
Authorizations:
Request Body schema: application/json
A request containing the information needed to create a session.
Array of CreateSessionWithClientCredentialsRequest (object) or CreateSessionWithTokenExchangeRequest (object) or CreateSessionWithOneshotTokenExchangeRequest (object) (CreateSessionRequest) = 1 items |
Responses
Request samples
- Payload
{- "items": [
- {
- "clientId": "string",
- "clientSecret": "string"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 0,
- "type": "CLIENT_CREDENTIALS",
- "status": "READY",
- "nonce": "string",
- "clientId": "string"
}
]
}Detaches Internal Session
This endpoint is used to detach sessions. When a session transits to DETACHED state, it will not be refreshable anymore, but its child sessions remain intact and they can still be used and refreshed.
Authorizations:
Request Body schema: application/json
Array of objects |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 0
}
]
}Response samples
- 200
{- "items": [
- {
- "id": 0,
- "type": "TOKEN_EXCHANGE",
- "status": "DETACHED",
- "creationTime": 1638795554528,
- "expirationTime": 1638795554528
}
]
}Get internal token for session
This endpoint is used to bind or refresh the session. These operations may fail in the following cases
Project's identity provider settings have been updated. Updating the IdP settings invalidates all sessions within the project.
The session is revoked (or lost through other mechanisms) in the identity provider.
Parent session is revoked through CDF API. Revoking parent sessions revokes all active child sessions.
The session has expired because it has not been refreshed.
Authorizations:
Request Body schema: application/json
| nonce required | string Nonce returned by session creation endpoint |
| maxExpirationSeconds | integer or null Maximum number of seconds that the session may stay valid for, from the time it's bound. Even if the session is refreshed, it may not stay valid beyond this. |
Responses
Request samples
- Payload
{- "nonce": "string",
- "maxExpirationSeconds": 0
}Response samples
- 200
{- "id": 0,
- "accessToken": "string",
- "expiresIn": 0,
- "sessionKey": "string",
- "sessionExpirationTime": 0,
- "sessionIsExtendable": null
}List sessions
List all sessions in the current project.
Authorizations:
query Parameters
| status | string Enum: "ready" "active" "cancelled" "revoked" "access_lost" If given, only sessions with the given status are returned. |
| cursor | string Cursor to use for paging through results. |
| limit | integer <int32> <= 1000 Default: 25 Return up to this many results. Maximum is 1000. Default is 25. |
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "id": 0,
- "type": "CLIENT_CREDENTIALS",
- "status": "READY",
- "creationTime": 1730204346000,
- "expirationTime": 1730204346000,
- "clientId": "string"
}
], - "nextCursor": "string",
- "previousCursor": "string"
}Retrieve sessions with given IDs
Retrieves sessions with given IDs. The request will fail if any of the IDs does not belong to an existing session.
Authorizations:
Request Body schema: application/json
List of session IDs to retrieve
required | Array of objects [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 1
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 105049194919491,
- "type": "TOKEN_EXCHANGE",
- "status": "ACTIVE",
- "creationTime": 1638795559528,
- "expirationTime": 1638795559628
}
]
}Revoke sessions
Revoke access to a session. Revocation is idempotent. Revocation of a session may in some cases take up to 1 hour to take effect.
Authorizations:
Request Body schema: application/json
A request containing the information needed to revoke sessions.
Array of objects (RevokeSessionRequest) non-empty |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 0
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 0,
- "type": "CLIENT_CREDENTIALS",
- "status": "REVOKED",
- "creationTime": 1638795554528,
- "expirationTime": 1638795554528,
- "clientId": "client-123"
}
]
}Inspect
Inspect CDF access granted to an IdP issued token
Authorizations:
Responses
Response samples
- 200
- 401
- 403
{- "subject": "string",
- "projects": [
- {
- "projectUrlName": "string",
- "groups": [
- 0
]
}
], - "capabilities": [
- {
- "groupsAcl": {
- "actions": [
- "LIST"
], - "scope": {
- "all": { }
}
}, - "projectScope": {
- "allProjects": { }
}
}
]
}User profiles is an authoritative source of core user profile information (email, name, job title, etc.) for principals based on data from the identity provider configured for the CDF project.
User profiles are first created (usually within a few seconds) when a principal issues a request against a CDF API. We currently don't support automatic exchange of user identity information between the identity provider and CDF, but the profile data is updated regularly with the latest data from the identity provider for the principals issuing requests against a CDF API.
Note:
- Do not use other fields than
userIdentifier(e.g. email) to uniquely identify a principal. User profile data is mutable and is not guaranteed to be stable or unique (exceptuserIdentifier). - Do not use user profile data for authentication or authorization purposes. It is not guaranteed to be under the strict governance necessary for that. For example, one should not use email address as proof of identity or job title to give access to resources.
- We strongly recommend against storing any user profile data. It is intended for display purposes only and may update at any time. Clients should fetch user profile data at demand, and optionally cache for performance reasons.
(deprecated) Get the user profile of the principal issuing the request Deprecated
Deprecated in favor of the new endpoint.
Retrieves the user profile of the principal issuing the request. If a principal doesn't have a user profile, you get a not found (404) response code. Note: User profiles are created asyncronously, so the endpoint might return 404 for a new principal for a while (usually seconds) until the profile has been created.
Authorizations:
Responses
Request samples
- JavaScript SDK
- Python SDK
const response = await client.profiles.me();
Response samples
- 200
- 404
{- "userIdentifier": "abcd",
- "givenName": "Jane",
- "surname": "Doe",
- "email": "jane.doe@example.com",
- "displayName": "Jane Doe",
- "jobTitle": "Software Engineer",
- "identityType": "USER",
- "lastUpdatedTime": 1730204346000
}Get the user profile of the principal issuing the request Deprecated
Deprecated in favor of the new endpoint.
Retrieves the user profile of the principal issuing the request.
Authorizations:
Responses
Response samples
- 200
{- "userIdentifier": "-cFNuYkHgnn5q8pnlVlCRg",
- "displayName": "Jane Doe",
- "givenName": "Jane",
- "surname": "Doe",
- "email": "jane.doe@example.com",
- "identityType": "USER",
- "lastUpdatedTime": 1730204346000
}List all user profiles in the current project Deprecated
Deprecated in favor of the List principals endpoint.
List all user profiles in the current project. This operation supports pagination by cursor. The results are ordered alphabetically by name.
Authorizations:
query Parameters
| identityType | string (IdentityTypeFilter) Enum: "ALL" "USER" "SERVICE_PRINCIPAL" "INTERNAL_SERVICE" The identity type filter field indicates the type of principal the request should be filtered to show.
If no value is specified, the default value is
|
| limit | integer [ 1 .. 1000 ] Default: 25 Limits the number of results to be returned. The server returns no more than 1000 results even if the specified limit is larger. The default limit is 25. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Request samples
- JavaScript SDK
- Python SDK
const response = await client.profiles.list({ limit: 1000 });
Response samples
- 200
{- "items": [
- {
- "userIdentifier": "abcd",
- "givenName": "Jane",
- "surname": "Doe",
- "email": "jane.doe@example.com",
- "displayName": "Jane Doe",
- "jobTitle": "Software Engineer",
- "identityType": "USER",
- "lastUpdatedTime": 1730204346000
}
], - "nextCursor": "string"
}List users in the organization Deprecated
Deprecated in favor of the List principals v1 endpoint,
with the types=USER filter.
List all users in the specified organization. The list can differ from the one that can be retrieved in a particular project in the organization. This is because organizations can contain several projects, and not all organization users have logged into all projects, and there have a profile there.
Access control
Any logged in principal can list users in their own organization.
Authorizations:
path Parameters
| org required | string (OrgId) [ 3 .. 64 ] characters ^([a-z][a-z0-9-]{1,62}[a-z0-9])$ Example: my-org ID of an organization |
query Parameters
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Response samples
- 200
{- "items": [
- {
- "id": "-user-string-id-aBc123",
- "email": "user@example.com",
- "name": "John N. Doe",
- "givenName": "John",
- "middleName": "N.",
- "familyName": "Doe",
}
], - "nextCursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo"
}{kind=link}
Retrieve profiles by ID in the current project Deprecated
Deprecated in favor of the Retrieve principals endpoint.
Retrieve one or more user profiles indexed by the user identifier in the same CDF project.
Authorizations:
Request Body schema: application/json
Specify a maximum of 1000 unique IDs.
Array of objects (UserIdentifier) |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
{- "items": [
- {
- "userIdentifier": "abcd"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "userIdentifier": "abcd",
- "givenName": "Jane",
- "surname": "Doe",
- "email": "jane.doe@example.com",
- "displayName": "Jane Doe",
- "jobTitle": "Software Engineer",
- "identityType": "USER",
- "lastUpdatedTime": 1730204346000
}
]
}Search user profiles in the current project Deprecated
Deprecated in favor of the List principals endpoint.
Search user profiles in the current project. The result set ordering and match criteria threshold may change over time. This operation does not support pagination.
Authorizations:
Request Body schema: application/json
Query for user profile search.
object | |
| limit | integer <int32> [ 1 .. 1000 ] Default: 25 <- Limits the maximum number of results to be returned by single request. The default is 25. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
{- "search": {
- "name": "string"
}, - "limit": 25
}Response samples
- 200
{- "items": [
- {
- "userIdentifier": "abcd",
- "givenName": "Jane",
- "surname": "Doe",
- "email": "jane.doe@example.com",
- "displayName": "Jane Doe",
- "jobTitle": "Software Engineer",
- "identityType": "USER",
- "lastUpdatedTime": 1730204346000
}
]
}All data in CDF must have a service responsible for its deletion. There must not be more than one such service for each piece of data.
The responsible service must fetch the list of deleted projects regularly (for example in a cronjob) and compare it to the projects it has data for. If it has any data in the project, it must physically delete this data in a timely manner and report the status upon completion, with the exception of data types that need to kept for a longer period after project deletion, such as those listed below.
- Project records
- Audit logs
- Backups
- Data usage, billing info
If the service does not have any data for the given project, for example if the service was never used for the project, data deletion may be skipped. In this case, the service should still report that it has completed deletion of data in the project (with the NOT_APPLICABLE state). If a service is not responsible for deleting any data, it should not report any deletion of data.
Create a project deletion report
Create a project deletion report for a given internal service (referred to as a resource) with a given status.
Internal services should exercise discretion when choosing a resource name, as we currently do not have any sort of internal service catalog, so there is potential for conflict between resource names across services. Choose a name meaningful for your service - e.g. timeseries, iam, etc.
Optional failure reason can be provided in the corresponding field
Authorizations:
Request Body schema: application/jsonrequired
Project deletion report to create
required | Array of objects (DeletionReportRequest) = 1 characters |
Responses
Request samples
- Payload
{- "items": [
- {
- "projectId": 0,
- "resource": "timeseries",
- "state": "RECEIVED",
- "failure": "string"
}
]
}Response samples
- 201
{- "items": [
- {
- "projectId": 0,
- "resource": "timeseries",
- "state": "RECEIVED",
- "failure": "string",
- "createdTime": 1697194426715
}
]
}List project deletion reports
A utility endpoint for listing project deletion reports with the ability to filter by project ID, resource type, and deletion status. Internal services can use this endpoint to query the deletion status of their data or the data of other services if that data should be deleted first. All query parameters are optional. If any field is omitted, filtering by this criterion is disabled.
Authorizations:
query Parameters
| state | string (ProjectDeletionReportState) Enum: "RECEIVED" "STARTED" "COMPLETED" "FAILED" "NOT_APPLICABLE" The state field indicates the state of deletion.
|
| resource | string Example: resource=timeseries Filter reports by resource names |
| projectId | integer <int64> Filter reports by project id |
| sort | string Default: "ASC" Enum: "ASC" "DESC" Sort descending or ascending. |
| cursor | string Cursor to use for paging through results. |
| limit | integer <int32> <= 1000 Default: 25 Return up to this many results. Maximum is 1000. Default is 25. |
Responses
Response samples
- 200
{- "items": [
- {
- "projectId": 0,
- "resource": "timeseries",
- "state": "RECEIVED",
- "failure": "string",
- "createdTime": 1697194426715
}
], - "nextCursor": "string"
}List projects awaiting resource deletion reports
A utility endpoint that internal services may use to figure out if a given resource has data to be removed. The endpoint will list all deleted projects which either have not received any deletion reports for the specified resource, or state is not either COMPLETED or NOT_APPLICABLE.
Authorizations:
query Parameters
| resource required | string Example: resource=timeseries Reports for a resource name |
| cursor | string Cursor to use for paging through results. |
| limit | integer <int32> <= 1000 Default: 25 Return up to this many results. Maximum is 1000. Default is 25. |
Responses
Response samples
- 200
{- "items": [
- {
- "projectId": 0,
- "resource": "timeseries",
- "state": "RECEIVED",
- "failure": "string",
- "lastUpdatedTime": 1697194426715
}
], - "nextCursor": "string"
}Reset deletion reports
A utility endpoint for removing all deletion reports of a particular resource type, reported for some deleted projects. This is handy for when services restores their data from backups and wants to sync their state with that of IAM-API deletion report state.
Authorizations:
Request Body schema: application/jsonrequired
A list of project ids and resource identifier
required | Array of objects (ResetReportRequest) = 1 characters |
Responses
Request samples
- Payload
{- "items": [
- {
- "projectIds": [
- 0
], - "resource": "timeseries"
}
]
}Response samples
- 200
{- "items": [
- 0
]
}Use the Data Modeling Service to build industrial knowledge graphs. For more information, see Data modeling.
This page contains the specifications for the 5 core data modeling resources:
- Spaces
- Instances (Nodes & Edges)
- Containers
- Views
- Data Models
Create or update data models
Add or update (upsert) data models. For unchanged data model specifications, the operation completes without making any changes. We will not update the lastUpdatedTime value for models that remain unchanged.
Authorizations:
Request Body schema: application/jsonrequired
List of data models to add
required | Array of objects (DataModelCreate) [ 1 .. 100 ] items List of data models to create/update |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "space": "string",
- "externalId": "string",
- "name": "string",
- "description": "string",
- "version": "string",
- "views": [
- {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}
]
}
]
}Response samples
- 200
- 400
- 409
{- "items": [
- {
- "space": "string",
- "externalId": "string",
- "name": "string",
- "description": "string",
- "version": "string",
- "views": [
- {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}
], - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "isGlobal": true
}
]
}Delete data models
Delete one or more data models. Currently limited to 100 models at a time. This does not delete the views, nor the containers they reference.
Authorizations:
Request Body schema: application/jsonrequired
List of references to data models you wish to delete
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string"
}
]
}List data models defined in the project
List data models defined in the project. You can filter the returned models by the specified space.
Authorizations:
query Parameters
| limit | integer [ 1 .. 1000 ] Default: 10 Limit the number of results returned. The largest result-set returned by the server will be 1000 items, even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| inlineViews | boolean Default: false Should we expand the referenced views inline in the returned result. |
| space | string [ 1 .. 43 ] characters (?!^(space|cdf|dms|pg3|shared|system|node|edg... Example: space=timeseries The space to query. |
| allVersions | boolean Default: false If all versions of the entity should be returned. Defaults to false which returns the latest version, attributed to the newest 'createdTime' field |
| includeGlobal | boolean Default: false If the global items of the entity should be returned. Defaults to false which excludes global items. |
Responses
Request samples
- Python SDK
data_model_list = client.data_modeling.data_models.list(limit=5) for data_model in client.data_modeling.data_models: data_model # do something with the data_model for data_model_list in client.data_modeling.data_models(chunk_size=10): data_model_list # do something with the data model
Response samples
- 200
- 400
{- "items": [
- {
- "space": "string",
- "externalId": "string",
- "name": "string",
- "description": "string",
- "version": "string",
- "views": [
- {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}
], - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "isGlobal": true
}
], - "nextCursor": "string"
}Retrieve data models by their external ids
Retrieve up to 100 data models by their external ids. Views can be auto-expanded when the InlineViews query parameter is set.
Authorizations:
query Parameters
| inlineViews | boolean Default: false Should we expand the referenced views inline in the returned result. |
Request Body schema: application/jsonrequired
List of external-ids of data models to retrieve.
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "space": "string",
- "externalId": "string",
- "name": "string",
- "description": "string",
- "version": "string",
- "views": [
- {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}
], - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "isGlobal": true
}
]
}Create or update spaces
Add or update (upsert) spaces. For unchanged space specifications, the operation completes without making any changes. We will not update the lastUpdatedTime value for spaces that remain unchanged.
Authorizations:
Request Body schema: application/jsonrequired
Spaces to add or update.
required | Array of objects (SpaceCreateDefinition) [ 1 .. 100 ] items List of spaces to create/update |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "space": "string",
- "description": "string",
- "name": "string"
}
]
}Response samples
- 200
- 400
- 409
{- "items": [
- {
- "space": "string",
- "description": "string",
- "name": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "isGlobal": true
}
]
}Delete spaces
Delete one or more spaces. Currently limited to 100 spaces at a time.
If an existing data model references a space, you cannot delete that space. Nodes, edges and other data types that are part of a space will no longer be available.
Authorizations:
Request Body schema: application/jsonrequired
List of space-ids for spaces to delete.
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "space": "string"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "space": "string"
}
]
}List spaces defined in the project
List spaces defined in the current project.
Authorizations:
query Parameters
| limit | integer [ 1 .. 1000 ] Default: 10 Limit the number of results returned. The largest result-set returned by the server will be 1000 items, even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| includeGlobal | boolean Default: false If the global items of the entity should be returned. Defaults to false which excludes global items. |
Responses
Request samples
- Python SDK
space_list = client.data_modeling.spaces.list(limit=5) for space in client.data_modeling.spaces: space # do something with the space for space_list in client.data_modeling.spaces(chunk_size=2500): space_list # do something with the spaces
Response samples
- 200
- 400
{- "items": [
- {
- "space": "string",
- "description": "string",
- "name": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "isGlobal": true
}
], - "nextCursor": "string"
}Retrieve spaces by their space-ids
Retrieve up to 100 spaces by specifying their space-ids.
Authorizations:
Request Body schema: application/jsonrequired
List of space-ids for the spaces to return.
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "space": "string"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "space": "string",
- "description": "string",
- "name": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "isGlobal": true
}
]
}Create or update views
Add or update (upsert) views. For unchanged view specifications, the operation completes without making any changes. We will not update the lastUpdatedTime value for views that remain unchanged.
Authorizations:
Request Body schema: application/jsonrequired
Views to add or update.
required | Array of objects (ViewCreateDefinition) [ 1 .. 100 ] items List of views to create/update |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "string",
- "space": "string",
- "name": "string",
- "description": "string",
- "filter": {
- "and": [
- {
- "in": {
- "property": [
- "tag"
], - "values": [
- 10011,
- 10011
]
}
}, - {
- "range": {
- "property": [
- "weight"
], - "gte": 0
}
}
]
}, - "implements": [
- {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}
], - "version": "string",
- "properties": {
- "property-identifier1": {
- "name": "string",
- "description": "string",
- "container": {
- "type": "container",
- "space": "string",
- "externalId": "string"
}, - "containerPropertyIdentifier": "string",
- "source": {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}
}, - "property-identifier2": {
- "name": "string",
- "description": "string",
- "container": {
- "type": "container",
- "space": "string",
- "externalId": "string"
}, - "containerPropertyIdentifier": "string",
- "source": {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}
}
}
}
]
}Response samples
- 200
- 400
- 409
{- "items": [
- {
- "externalId": "string",
- "space": "string",
- "name": "string",
- "description": "string",
- "filter": {
- "and": [
- {
- "in": {
- "property": [
- "tag"
], - "values": [
- 10011,
- 10011
]
}
}, - {
- "range": {
- "property": [
- "weight"
], - "gte": 0
}
}
]
}, - "implements": [
- {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}
], - "version": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "writable": true,
- "queryable": true,
- "usedFor": "node",
- "isGlobal": true,
- "properties": {
- "view-property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}, - "container": {
- "type": "container",
- "space": "string",
- "externalId": "string"
}, - "containerPropertyIdentifier": "string"
}, - "view-property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}, - "container": {
- "type": "container",
- "space": "string",
- "externalId": "string"
}, - "containerPropertyIdentifier": "string"
}
}, - "mappedContainers": [
- {
- "type": "container",
- "space": "string",
- "externalId": "string"
}
]
}
]
}Delete views
Delete one or more views. Currently limited to 100 views at a time.
Authorizations:
Request Body schema: application/jsonrequired
List of references to views you want to delete.
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string"
}
]
}List views defined in the project
List of views defined in the current project. You can filter the list by specifying a space.
Authorizations:
query Parameters
| limit | integer [ 1 .. 1000 ] Default: 10 Limit the number of results returned. The largest result-set returned by the server will be 1000 items, even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| space | string [ 1 .. 43 ] characters (?!^(space|cdf|dms|pg3|shared|system|node|edg... Example: space=timeseries The space to query. |
| includeInheritedProperties | boolean Default: true Include properties inherited from views this view implements. |
| allVersions | boolean Default: false If all versions of the entity should be returned. Defaults to false which returns the latest version, attributed to the newest 'createdTime' field |
| includeGlobal | boolean Default: false If the global items of the entity should be returned. Defaults to false which excludes global items. |
Responses
Request samples
- Python SDK
view_list = client.data_modeling.views.list(limit=5) for view in client.data_modeling.views: view # do something with the view for view_list in client.data_modeling.views(chunk_size=10): view_list # do something with the views
Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "string",
- "space": "string",
- "name": "string",
- "description": "string",
- "filter": {
- "and": [
- {
- "in": {
- "property": [
- "tag"
], - "values": [
- 10011,
- 10011
]
}
}, - {
- "range": {
- "property": [
- "weight"
], - "gte": 0
}
}
]
}, - "implements": [
- {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}
], - "version": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "writable": true,
- "queryable": true,
- "usedFor": "node",
- "isGlobal": true,
- "properties": {
- "view-property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}, - "container": {
- "type": "container",
- "space": "string",
- "externalId": "string"
}, - "containerPropertyIdentifier": "string"
}, - "view-property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}, - "container": {
- "type": "container",
- "space": "string",
- "externalId": "string"
}, - "containerPropertyIdentifier": "string"
}
}, - "mappedContainers": [
- {
- "type": "container",
- "space": "string",
- "externalId": "string"
}
]
}
], - "nextCursor": "string"
}Retrieve views by their external ids
Retrieve up to 100 views by their external ids.
Authorizations:
query Parameters
| includeInheritedProperties | boolean Default: true Include properties inherited from views this view implements. |
Request Body schema: application/jsonrequired
List of external-ids of views to retrieve.
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "string",
- "space": "string",
- "name": "string",
- "description": "string",
- "filter": {
- "and": [
- {
- "in": {
- "property": [
- "tag"
], - "values": [
- 10011,
- 10011
]
}
}, - {
- "range": {
- "property": [
- "weight"
], - "gte": 0
}
}
]
}, - "implements": [
- {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}
], - "version": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "writable": true,
- "queryable": true,
- "usedFor": "node",
- "isGlobal": true,
- "properties": {
- "view-property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}, - "container": {
- "type": "container",
- "space": "string",
- "externalId": "string"
}, - "containerPropertyIdentifier": "string"
}, - "view-property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}, - "container": {
- "type": "container",
- "space": "string",
- "externalId": "string"
}, - "containerPropertyIdentifier": "string"
}
}, - "mappedContainers": [
- {
- "type": "container",
- "space": "string",
- "externalId": "string"
}
]
}
]
}Create or update containers
Add or update (upsert) containers. For unchanged container specifications, the operation completes without making any changes. We will not update the lastUpdatedTime value for containers that remain unchanged.
Authorizations:
Request Body schema: application/jsonrequired
Containers to add or update.
required | Array of objects (ContainerCreateDefinition) [ 1 .. 100 ] items List of containers to create/update |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "space": "string",
- "externalId": "string",
- "name": "string",
- "description": "string",
- "usedFor": "node",
- "properties": {
- "containerPropertyIdentifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "containerPropertyIdentifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "constraints": {
- "constraint-identifier1": {
- "constraintType": "requires",
- "require": {
- "type": "container",
- "space": "string",
- "externalId": "string"
}
}, - "constraint-identifier2": {
- "constraintType": "requires",
- "require": {
- "type": "container",
- "space": "string",
- "externalId": "string"
}
}
}, - "indexes": {
- "index-identifier1": {
- "properties": [
- "string"
], - "indexType": "btree",
- "cursorable": false,
- "bySpace": false
}, - "index-identifier2": {
- "properties": [
- "string"
], - "indexType": "btree",
- "cursorable": false,
- "bySpace": false
}
}
}
]
}Response samples
- 200
- 400
- 409
{- "items": [
- {
- "space": "string",
- "externalId": "string",
- "name": "string",
- "description": "string",
- "usedFor": "node",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "isGlobal": true,
- "properties": {
- "containerPropertyIdentifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "containerPropertyIdentifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "constraints": {
- "constraint-identifier1": {
- "state": "current",
- "constraintType": "requires",
- "require": {
- "type": "container",
- "space": "string",
- "externalId": "string"
}
}, - "constraint-identifier2": {
- "state": "current",
- "constraintType": "requires",
- "require": {
- "type": "container",
- "space": "string",
- "externalId": "string"
}
}
}, - "indexes": {
- "index-identifier1": {
- "properties": [
- "string"
], - "indexType": "btree",
- "cursorable": false,
- "bySpace": false,
- "state": "current"
}, - "index-identifier2": {
- "properties": [
- "string"
], - "indexType": "btree",
- "cursorable": false,
- "bySpace": false,
- "state": "current"
}
}
}
]
}Delete constraints from containers
Delete one or more container constraints. Currently limited to 10 constraints at a time.
Authorizations:
Request Body schema: application/jsonrequired
List of the references to constraints you want to delete.
required | Array of objects [ 1 .. 10 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "space": "string",
- "containerExternalId": "string",
- "identifier": "string"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "space": "string",
- "containerExternalId": "string",
- "identifier": "string"
}
]
}Delete containers
Delete one or more containers. Currently limited to 100 containers at a time.
Authorizations:
Request Body schema: application/jsonrequired
List of the spaces and external-ids for the containers you want to delete.
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "string",
- "space": "string"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "string",
- "space": "string"
}
]
}Delete indexes from containers
Delete one or more container indexes. Currently limited to 10 indexes at a time.
Authorizations:
Request Body schema: application/jsonrequired
List of the references to indexes you want to delete.
required | Array of objects [ 1 .. 10 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "space": "string",
- "containerExternalId": "string",
- "identifier": "string"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "space": "string",
- "containerExternalId": "string",
- "identifier": "string"
}
]
}Inspect containers
Authorizations:
Request Body schema: application/jsonrequired
Which containers to inspect and the inspection operations to run.
required | object |
required | Array of objects [ 1 .. 10 ] items |
Responses
Request samples
- Payload
{- "inspectionOperations": {
- "involvedViews": {
- "allVersions": false
}, - "totalInvolvedViewCount": {
- "allVersions": false,
- "includeUnavailableViews": true,
- "includeOutOfAccessScopeViews": true
}
}, - "items": [
- {
- "space": "string",
- "externalId": "string"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "string",
- "space": "string",
- "inspectionResults": {
- "involvedViewCount": 0,
- "involvedViews": [
- {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}
]
}
}
]
}List containers defined in the project
List of containers defined in the current project. You can filter the list by specifying a space.
Authorizations:
query Parameters
| limit | integer [ 1 .. 1000 ] Default: 10 Limit the number of results returned. The largest result-set returned by the server will be 1000 items, even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| space | string [ 1 .. 43 ] characters (?!^(space|cdf|dms|pg3|shared|system|node|edg... Example: space=timeseries The space to query. |
| includeGlobal | boolean Default: false If the global items of the entity should be returned. Defaults to false which excludes global items. |
Responses
Request samples
- Python SDK
container_list = client.data_modeling.containers.list(limit=5) for container in client.data_modeling.containers: container # do something with the container for container_list in client.data_modeling.containers(chunk_size=10): container_list # do something with the containers
Response samples
- 200
- 400
{- "items": [
- {
- "space": "string",
- "externalId": "string",
- "name": "string",
- "description": "string",
- "usedFor": "node",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "isGlobal": true,
- "properties": {
- "containerPropertyIdentifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "containerPropertyIdentifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "constraints": {
- "constraint-identifier1": {
- "state": "current",
- "constraintType": "requires",
- "require": {
- "type": "container",
- "space": "string",
- "externalId": "string"
}
}, - "constraint-identifier2": {
- "state": "current",
- "constraintType": "requires",
- "require": {
- "type": "container",
- "space": "string",
- "externalId": "string"
}
}
}, - "indexes": {
- "index-identifier1": {
- "properties": [
- "string"
], - "indexType": "btree",
- "cursorable": false,
- "bySpace": false,
- "state": "current"
}, - "index-identifier2": {
- "properties": [
- "string"
], - "indexType": "btree",
- "cursorable": false,
- "bySpace": false,
- "state": "current"
}
}
}
], - "nextCursor": "string"
}Retrieve containers by their external ids
Retrieve up to 100 containers by their specified external ids.
Authorizations:
Request Body schema: application/jsonrequired
List of external-ids of containers to retrieve.
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "string",
- "space": "string"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "space": "string",
- "externalId": "string",
- "name": "string",
- "description": "string",
- "usedFor": "node",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "isGlobal": true,
- "properties": {
- "containerPropertyIdentifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "containerPropertyIdentifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "constraints": {
- "constraint-identifier1": {
- "state": "current",
- "constraintType": "requires",
- "require": {
- "type": "container",
- "space": "string",
- "externalId": "string"
}
}, - "constraint-identifier2": {
- "state": "current",
- "constraintType": "requires",
- "require": {
- "type": "container",
- "space": "string",
- "externalId": "string"
}
}
}, - "indexes": {
- "index-identifier1": {
- "properties": [
- "string"
], - "indexType": "btree",
- "cursorable": false,
- "bySpace": false,
- "state": "current"
}, - "index-identifier2": {
- "properties": [
- "string"
], - "indexType": "btree",
- "cursorable": false,
- "bySpace": false,
- "state": "current"
}
}
}
]
}(PoC) Aggregate data across nodes/edges
(PoC) Aggregate data for nodes or edges in a project. You can use an optional query or filter specification to limit the result.
Authorizations:
Request Body schema: application/jsonrequired
Aggregation specification.
| query | string Optional query string. The API will parse the query string, and use it to match the text properties on elements to use for the aggregate(s). |
| properties | Array of strings [ 1 .. 200 ] items Optional list (array) of properties you want to apply the query above to. If you do not list any properties, you search through text fields by default. |
required | object (AggregatesDefinition) [ 1 .. 5 ] properties unique A dictionary of requested aggregates with client defined names/identifiers. Example: |
(BoolFilter (and (object) or or (object) or not (object))) or (LeafFilter (equals (object) or in (object) or range (object) or prefix (object) or exists (object) or containsAny (object) or containsAll (object) or matchAll (object) or nested (object) or overlaps (object) or hasData (object) or instanceReferences (object))) (FilterDefinition) | |
required | object (ViewReference) Reference to a view |
Array of objects (TargetUnits) [ 1 .. 10 ] items Properties to convert to another unit. The API can only convert to another unit, if a unit has been defined as part of the type on the underlying container being queried. | |
| includeTyping | boolean (IncludeTyping) Should we return property type information as part of the result? |
Responses
Request samples
- Payload
{- "query": "string",
- "properties": [
- "string"
], - "aggregates": {
- "my_avg_aggregate1": {
- "avg": {
- "property": [
- "mySpace",
- "myContainer",
- "manufacturer"
]
}
}, - "my_terms_aggregate2": {
- "uniqueValues": {
- "property": [
- "mySpace",
- "myContainer",
- "manufacturer"
], - "aggregates": {
- "my_sub_aggregate1": {
- "min": {
- "property": [
- "mySpace",
- "myContainer",
- "price"
]
}
}, - "my_sub_aggregate2": {
- "max": {
- "property": [
- "mySpace",
- "myContainer",
- "price"
]
}
}, - "my_sub_aggregate3": {
- "uniqueValues": {
- "property": [
- "mySpace",
- "myContainer",
- "region"
]
}
}
}
}
}
}, - "filter": {
- "and": [
- {
- "in": {
- "property": [
- "tag"
], - "values": [
- 10011,
- 10011
]
}
}, - {
- "range": {
- "property": [
- "weight"
], - "gte": 0
}
}
]
}, - "view": {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "targetUnits": [
- {
- "property": "string",
- "unit": {
- "externalId": "string"
}
}
], - "includeTyping": false
}Response samples
- 200
- 400
{- "typing": {
- "space-name1": {
- "view-or-container-external-id1": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "view-or-container-external-id2": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}
}, - "space-name2": {
- "view-or-container-external-id1": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "view-or-container-external-id2": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}
}
}, - "aggregates": {
- "my_avg_aggregate1": {
- "avg": 42
}, - "my_terms_aggregate2": {
- "buckets": [
- {
- "value": "Cognite",
- "count": 42,
- "aggregates": {
- "my_sub_aggregate1": {
- "min": 13
}, - "my_sub_aggregate2": {
- "max": 69
}, - "my_sub_aggregate3": {
- "buckets": [
- {
- "value": "us1",
- "count": 42
}, - {
- "value": "ie1",
- "count": 7
}
]
}
}
}, - {
- "value": "AkerBP",
- "count": 21,
- "aggregates": {
- "my_sub_aggregate1": {
- "min": 99
}, - "my_sub_aggregate2": {
- "max": 999
}, - "my_sub_aggregate3": {
- "buckets": [
- {
- "value": "us1",
- "count": 11
}
]
}
}
}
]
}
}
}Aggregate data across nodes/edges
Aggregate data for nodes or edges in a project. You can use an optional query or filter specification to limit the result.
Authorizations:
Request Body schema: application/jsonrequired
Aggregation specification.
| query | string Optional query string. The API will parse the query string, and use it to match the text properties on elements to use for the aggregate(s). |
| properties | Array of strings [ 1 .. 200 ] items Optional list (array) of properties you want to apply the query above to. If you do not list any properties, you search through text fields by default. |
| limit | integer [ 1 .. 1000 ] Default: 100 Limit the number of results returned. The default limit is currently at 100 items. |
Array of avg (object) or count (object) or min (object) or max (object) or sum (object) or histogram (object) (AggregationDefinition) <= 5 items | |
| groupBy | Array of strings [ 1 .. 5 ] items The selection of fields to group the results by when doing aggregations. You can specify up to 5 items to group by. When you do not specify any aggregates, the fields listed in the |
(BoolFilter (and (object) or or (object) or not (object))) or (LeafFilter (equals (object) or in (object) or range (object) or prefix (object) or exists (object) or containsAny (object) or containsAll (object) or matchAll (object) or nested (object) or overlaps (object) or hasData (object) or instanceReferences (object))) (FilterDefinition) | |
| operator | string (SearchOperator) Enum: "AND" "OR" Controls how multiple search terms are combined when matching documents.
|
| instanceType | string (InstanceType) Enum: "node" "edge" The type of instance |
required | object (ViewReference) Reference to a view |
Array of objects (TargetUnits) [ 1 .. 10 ] items Properties to convert to another unit. The API can only convert to another unit, if a unit has been defined as part of the type on the underlying container being queried. | |
| includeTyping | boolean (IncludeTyping) Should we return property type information as part of the result? |
Responses
Request samples
- Payload
- Python SDK
{- "query": "string",
- "properties": [
- "string"
], - "limit": 100,
- "aggregates": [
- {
- "avg": {
- "property": "string"
}
}
], - "groupBy": [
- "string"
], - "filter": {
- "and": [
- {
- "in": {
- "property": [
- "tag"
], - "values": [
- 10011,
- 10011
]
}
}, - {
- "range": {
- "property": [
- "weight"
], - "gte": 0
}
}
]
}, - "operator": "AND",
- "instanceType": "node",
- "view": {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "targetUnits": [
- {
- "property": "string",
- "unit": {
- "externalId": "string"
}
}
], - "includeTyping": false
}Response samples
- 200
- 400
{- "items": [
- {
- "instanceType": "node",
- "group": {
- "name": "PumpName1",
- "tag": "tag01"
}, - "aggregates": [
- {
- "aggregate": "avg",
- "property": "duration",
- "value": 0.2
}
]
}
], - "typing": {
- "space-name1": {
- "view-or-container-external-id1": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "view-or-container-external-id2": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}
}, - "space-name2": {
- "view-or-container-external-id1": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "view-or-container-external-id2": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}
}
}
}Create or update nodes/edges
Create or update nodes and edges in a transaction. The items field of the payload is an array of objects
where each object describes a node or an edge to create, patch or replace. The instanceType field of
each object must be node or edge and determines how the rest of the object is interpreted.
This operation is currently limited to 1000 nodes and/or edges at a time.
Individual nodes and edges are uniquely identified by their externalId and space.
For more details on ingesting instances into a graph, see [Ingesting instances] (https://docs.cognite.com/cdf/dm/dm_concepts/dm_ingestion).
Creating new instances
When there is no node or edge with the given externalId in the given space, a node will be created and the
properties provided for each of the containers or views in the sources array will be populated for the
node/edge. Nodes can also be created implicitly when an edge between them is created (if
autoCreateStartNodes and/or autoCreateEndNodes is set), or when a direct relation
property is set, the target node does not exist and autoCreateDirectRelations is set.
To add a node or edge, the user must have capabilities to access (write to) both the view(s) referenced in
sources and the container(s) underlying these views, as well as any directly referenced containers.
Updating (patching) or replacing instances
When a node or edge (instance) with the given externalId already exists in a space, the
properties named in the sources field will be written to the instance. Other properties will remain
unchanged. To replace the whole set of properties for an instance (a node or an edge) rather than patch the
instance, set the replace parameter to true.
Note: When using replace as true it will replace any omitted property to either it's default
value as defined on the container(s) or null if no default value is set. All properties on the related
container(s) referenced in the provided sources view(s) will be replaced, so even when the provided
view(s) only contains a subset of properties from a container all the properties in that container for that
instance will be replaced. If the underlying container(s) have any required properties that are not provided,
the operation will fail.
If you use a writable view to update properties (that is, the source you are referring to in sources
is a view), you must have write access to the view as well as all of its backing containers.
No-change patch operations
When a node/edge item has no changes compared to the existing instance - that is, when the supplied property
values are equal to the corresponding values in the existing node/edge, the node/edge will stay unchanged.
In this case, the lastUpdatedTime values for the nodes/edges in question will not change.
Deleting instances
It's also possible to delete instances by passing instance references to the delete field. Upserts and
deletes can be combined in the same request and will be executed atomically. The total number of ingested and
deleted items cannot exceed 1000.
Authorizations:
Request Body schema: application/jsonrequired
Nodes/edges to add or update.
required | Array of NodeWrite (object) or EdgeWrite (object) (NodeOrEdgeCreate) [ 0 .. 1000 ] items List of nodes and edges to create/update |
Array of objects (InstanceDelete) [ 0 .. 1000 ] items List of nodes and edges to delete | |
| autoCreateDirectRelations | boolean Default: true Should we create missing target nodes of direct relations? If the target-container constraint has been specified for a direct relation, the target node cannot be auto-created. If you want to point direct relations to a space where you have only read access, this option must be set to false. |
| autoCreateStartNodes | boolean Default: false Should we create missing start nodes for edges when ingesting? By default, the start node of an edge must exist before we can ingest the edge. |
| autoCreateEndNodes | boolean Default: false Should we create missing end nodes for edges when ingesting? By default, the end node of an edge must exist before we can ingest the edge. |
| skipOnVersionConflict | boolean Default: false If existingVersion is specified on any of the nodes/edges in the input, the default behaviour is that the entire ingestion will fail when version conflicts occur. If skipOnVersionConflict is set to true, items with version conflicts will be skipped instead. If no version is specified for nodes/edges, it will do the write directly. |
| replace | boolean Default: false How do we behave when a property value exists? Do we replace all matching and existing values with the supplied values ( |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "instanceType": "node",
- "existingVersion": 0,
- "space": "string",
- "externalId": "string",
- "type": {
- "space": "string",
- "externalId": "string"
}, - "sources": [
- {
- "source": {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "properties": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}
]
}
], - "delete": [
- {
- "instanceType": "node",
- "space": "string",
- "externalId": "string",
- "existingVersion": 0
}
], - "autoCreateDirectRelations": true,
- "autoCreateStartNodes": false,
- "autoCreateEndNodes": false,
- "skipOnVersionConflict": false,
- "replace": false
}Response samples
- 200
- 400
- 409
{- "items": [
- {
- "instanceType": "node",
- "version": 0,
- "wasModified": true,
- "space": "string",
- "externalId": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
], - "deleted": [
- {
- "instanceType": "node",
- "externalId": "string",
- "space": "string"
}
]
}Delete nodes/edges
Delete nodes and edges in a transaction. Limited to 1000 nodes/edges at a time.
When a node is selected for deletion, all connected incoming and outgoing edges that point to or from it are also deleted. However, please note that the operation might fail if the node has a high number of edge connections. If this is the case, consider deleting the edges connected to the node before deleting the node itself. Nodes and/or edges that do not exist in the graph when the delete request is processed will be ignored. The rationale for this is that the end-state will reflect the desired state regardless of the instance's previous state. Note that attempting to delete something from a space that does not exist will be considered an invalid request, as the API does not affect spaces themselves, only graph nodes and edges.
Authorizations:
Request Body schema: application/jsonrequired
List of types, spaces, and external-ids for nodes and edges to delete.
required | Array of objects (InstanceDelete) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "instanceType": "node",
- "space": "string",
- "externalId": "string",
- "existingVersion": 0
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "instanceType": "node",
- "externalId": "string",
- "space": "string"
}
]
}Filter nodes/edges
Filter the instances - nodes and edges - in a project.
Authorizations:
Request Body schema: application/jsonrequired
Filter based on the instance type, the name, the external-ids, and on properties. The filter supports sorting and pagination. The instances must have data in all the views referenced by the sources field. Properties for up to 10 views can be retrieved in one query.
| includeTyping | boolean (IncludeTyping) Should we return property type information as part of the result? |
Array of objects (SourceSelectorWithoutPropertiesV3) <= 10 items Retrieve properties from the listed - by reference - views. The node/edge must have data in all the sources defined in the list. | |
| instanceType | string Default: "node" Enum: "node" "edge" The type of instance you are querying for; an edge or a node. If the instance type isn't specified, we list nodes. When instanceType is Example: |
object (DebugParameters) Return query debug notices. | |
| cursor | string |
| limit | integer [ 1 .. 1000 ] Default: 1000 Limits the number of results to return. |
Array of objects (PropertySortV3) <= 5 items | |
(BoolFilter (and (object) or or (object) or not (object))) or (LeafFilter (equals (object) or in (object) or range (object) or prefix (object) or exists (object) or containsAny (object) or containsAll (object) or matchAll (object) or nested (object) or overlaps (object) or hasData (object) or instanceReferences (object))) (FilterDefinition) |
Responses
Request samples
- Payload
- Python SDK
{- "includeTyping": false,
- "sources": [
- {
- "source": {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "targetUnits": [
- {
- "property": "string",
- "unit": {
- "externalId": "string"
}
}
]
}
], - "instanceType": "node",
- "debug": {
- "emitResults": true,
- "timeout": 0,
- "includeTranslatedQuery": true,
- "includePlan": true,
- "profile": false
}, - "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo",
- "limit": 1000,
- "sort": [
- {
- "property": [
- "string"
], - "direction": "ascending",
- "nullsFirst": false
}
], - "filter": {
- "and": [
- {
- "in": {
- "property": [
- "tag"
], - "values": [
- 10011,
- 10011
]
}
}, - {
- "range": {
- "property": [
- "weight"
], - "gte": 0
}
}
]
}
}Response samples
- 200
- 400
{- "items": [
- {
- "instanceType": "node",
- "version": 0,
- "space": "string",
- "externalId": "string",
- "type": {
- "space": "string",
- "externalId": "string"
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "deletedTime": 1730204346000,
- "properties": {
- "space-name1": {
- "view-or-container-identifier1": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}, - "view-or-container-identifier2": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}, - "space-name2": {
- "view-or-container-identifier1": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}, - "view-or-container-identifier2": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}
}
}
], - "typing": {
- "space-name1": {
- "view-or-container-external-id1": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "view-or-container-external-id2": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}
}, - "space-name2": {
- "view-or-container-external-id1": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "view-or-container-external-id2": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}
}
}, - "nextCursor": "string",
- "debug": {
- "notices": [
- {
- "code": "excessiveTimeout",
- "category": "invalidDebugOptions",
- "level": "warning",
- "hint": "string",
- "timeout": 0
}
], - "translatedQuery": {
- "query": { },
- "parameters": { }
}, - "plan": {
- "fullPlan": { },
- "profiled": true,
- "byIdentifier": { }
}
}
}Inspect instances
Authorizations:
Request Body schema: application/jsonrequired
Change filter specification
required | object |
required | Array of objects [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "inspectionOperations": {
- "involvedViews": {
- "allVersions": false
}, - "involvedContainers": {
- "allVersions": false
}
}, - "items": [
- {
- "instanceType": "node",
- "externalId": "string",
- "space": "string"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "instanceType": "node",
- "externalId": "string",
- "space": "string",
- "inspectionResults": {
- "involvedViews": [
- {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}
], - "involvedContainers": [
- {
- "type": "container",
- "space": "string",
- "externalId": "string"
}
]
}
}
]
}Query nodes/edges
Specification of query endpoint. For more information, see Query language.
Authorizations:
Request Body schema: application/jsonrequired
Query specification.
required | object [ 1 .. 50 ] properties |
object <= 50 properties Cursors returned from the previous query request. These cursors match the result set expressions you specified in the | |
required | object [ 1 .. 50 ] properties Select properties for each result set. |
object Values in filters can be parameterised. Parameters are provided as part of the query object, and referenced in the filter itself. | |
| includeTyping | boolean (IncludeTyping) Should we return property type information as part of the result? |
| forceCursorsDespitePerformanceHazard | boolean Default: false Issue cursors for sort and filter combinations that are not backed by a cursorable index. Does not issue cursors for recursive result set expressions. |
object (DebugParameters) Return query debug notices. |
Responses
Request samples
- Payload
- Python SDK
{- "with": {
- "result-expression-name1": {
- "sort": [
- {
- "property": [
- "string"
], - "direction": "ascending",
- "nullsFirst": false
}
], - "limit": 100,
- "nodes": {
- "from": "string",
- "chainTo": "source",
- "through": {
- "view": {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "identifier": "string"
}, - "direction": "outwards",
- "filter": {
- "and": [
- {
- "in": {
- "property": [
- "tag"
], - "values": [
- 10011,
- 10011
]
}
}, - {
- "range": {
- "property": [
- "weight"
], - "gte": 0
}
}
]
}
}
}, - "result-expression-name2": {
- "sort": [
- {
- "property": [
- "string"
], - "direction": "ascending",
- "nullsFirst": false
}
], - "limit": 100,
- "nodes": {
- "from": "string",
- "chainTo": "source",
- "through": {
- "view": {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "identifier": "string"
}, - "direction": "outwards",
- "filter": {
- "and": [
- {
- "in": {
- "property": [
- "tag"
], - "values": [
- 10011,
- 10011
]
}
}, - {
- "range": {
- "property": [
- "weight"
], - "gte": 0
}
}
]
}
}
}
}, - "cursors": {
- "pagination cursor reference1": "string",
- "pagination cursor reference2": "string"
}, - "select": {
- "result-expression-name1": {
- "sources": [
- {
- "source": {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "properties": [
- "string"
], - "targetUnits": [
- {
- "property": "string",
- "unit": {
- "externalId": "string"
}
}
]
}
], - "sort": [
- {
- "property": [
- "string"
], - "direction": "ascending",
- "nullsFirst": false
}
], - "limit": 0
}, - "result-expression-name2": {
- "sources": [
- {
- "source": {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "properties": [
- "string"
], - "targetUnits": [
- {
- "property": "string",
- "unit": {
- "externalId": "string"
}
}
]
}
], - "sort": [
- {
- "property": [
- "string"
], - "direction": "ascending",
- "nullsFirst": false
}
], - "limit": 0
}
}, - "parameters": {
- "parameter-identifier1": "string",
- "parameter-identifier2": "string"
}, - "includeTyping": false,
- "forceCursorsDespitePerformanceHazard": false,
- "debug": {
- "emitResults": true,
- "timeout": 0,
- "includeTranslatedQuery": true,
- "includePlan": true,
- "profile": false
}
}Response samples
- 200
- 400
{- "items": {
- "result-expression1": [
- {
- "instanceType": "node",
- "version": 0,
- "space": "string",
- "externalId": "string",
- "type": {
- "space": "string",
- "externalId": "string"
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "deletedTime": 1730204346000,
- "properties": {
- "space-name1": {
- "view-or-container-identifier1": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}, - "view-or-container-identifier2": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}, - "space-name2": {
- "view-or-container-identifier1": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}, - "view-or-container-identifier2": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}
}
}
], - "result-expression2": [
- {
- "instanceType": "node",
- "version": 0,
- "space": "string",
- "externalId": "string",
- "type": {
- "space": "string",
- "externalId": "string"
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "deletedTime": 1730204346000,
- "properties": {
- "space-name1": {
- "view-or-container-identifier1": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}, - "view-or-container-identifier2": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}, - "space-name2": {
- "view-or-container-identifier1": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}, - "view-or-container-identifier2": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}
}
}
]
}, - "typing": {
- "result-expression1": {
- "space-name1": {
- "view-or-container-external-id1": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "view-or-container-external-id2": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}
}, - "space-name2": {
- "view-or-container-external-id1": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "view-or-container-external-id2": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}
}
}, - "result-expression2": {
- "space-name1": {
- "view-or-container-external-id1": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "view-or-container-external-id2": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}
}, - "space-name2": {
- "view-or-container-external-id1": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "view-or-container-external-id2": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}
}
}
}, - "nextCursor": {
- "cursor-name1": "string",
- "cursor-name2": "string"
}, - "debug": {
- "notices": [
- {
- "code": "excessiveTimeout",
- "category": "invalidDebugOptions",
- "level": "warning",
- "hint": "string",
- "timeout": 0
}
], - "translatedQuery": {
- "query": { },
- "parameters": { }
}, - "plan": {
- "fullPlan": { },
- "profiled": true,
- "byIdentifier": { }
}
}
}Retrieve nodes/edges by their external ids
Retrieve up to 1000 nodes or edges by their external ids.
Authorizations:
Request Body schema: application/jsonrequired
List of external-ids for nodes or edges to retrieve. Properties for up to 10 unique views (in total across the external ids requested) can be retrieved in one query.
Array of objects <= 10 items The node/edge must have data in all the sources defined in the list | |
required | Array of objects [ 1 .. 1000 ] items |
| includeTyping | boolean (IncludeTyping) Should we return property type information as part of the result? |
Responses
Request samples
- Payload
- Python SDK
{- "sources": [
- {
- "source": {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "targetUnits": [
- {
- "property": "string",
- "unit": {
- "externalId": "string"
}
}
]
}
], - "items": [
- {
- "instanceType": "node",
- "externalId": "string",
- "space": "string"
}
], - "includeTyping": false
}Response samples
- 200
- 400
{- "items": [
- {
- "instanceType": "node",
- "version": 0,
- "space": "string",
- "externalId": "string",
- "type": {
- "space": "string",
- "externalId": "string"
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "deletedTime": 1730204346000,
- "properties": {
- "space-name1": {
- "view-or-container-identifier1": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}, - "view-or-container-identifier2": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}, - "space-name2": {
- "view-or-container-identifier1": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}, - "view-or-container-identifier2": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}
}
}
], - "typing": {
- "space-name1": {
- "view-or-container-external-id1": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "view-or-container-external-id2": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}
}, - "space-name2": {
- "view-or-container-external-id1": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "view-or-container-external-id2": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}
}
}
}Search for nodes/edges
Search text fields in views for nodes or edge(s). The service will return up to 1000 results. This operation orders the results by relevance, across the specified spaces.
Authorizations:
Request Body schema: application/jsonrequired
The search specification.
required | object (ViewReference) Reference to a view |
| query | string Query string that will be parsed and used for search. |
| instanceType | string Default: "node" Enum: "node" "edge" Limit the search query to searching nodes or edges. Unless you set the item type to apply the search to, the service will default to searching nodes within the view. |
| properties | Array of strings Optional array of properties you want to search through. If you do not specify one or more properties, the service will search all text fields within the view. |
Array of objects (TargetUnits) [ 1 .. 10 ] items Properties to convert to another unit. The API can only convert to another unit, if a unit has been defined as part of the type on the underlying container being queried. | |
(BoolFilter (and (object) or or (object) or not (object))) or (LeafFilter (equals (object) or in (object) or range (object) or prefix (object) or exists (object) or containsAny (object) or containsAll (object) or matchAll (object) or nested (object) or overlaps (object) or hasData (object) or instanceReferences (object))) (FilterDefinition) | |
| includeTyping | boolean (IncludeTyping) Should we return property type information as part of the result? |
Array of objects (SearchSort) <= 5 items | |
| operator | string (SearchOperator) Enum: "AND" "OR" Controls how multiple search terms are combined when matching documents.
|
| limit | integer [ 1 .. 1000 ] Default: 1000 Limits the number of results to return. |
Responses
Request samples
- Payload
- Python SDK
{- "view": {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "query": "string",
- "instanceType": "node",
- "properties": [
- "string"
], - "targetUnits": [
- {
- "property": "string",
- "unit": {
- "externalId": "string"
}
}
], - "filter": {
- "and": [
- {
- "in": {
- "property": [
- "tag"
], - "values": [
- 10011,
- 10011
]
}
}, - {
- "range": {
- "property": [
- "weight"
], - "gte": 0
}
}
]
}, - "includeTyping": false,
- "sort": [
- {
- "property": [
- "string"
], - "direction": "ascending"
}
], - "operator": "AND",
- "limit": 1000
}Response samples
- 200
- 400
{- "items": [
- {
- "instanceType": "node",
- "version": 0,
- "space": "string",
- "externalId": "string",
- "type": {
- "space": "string",
- "externalId": "string"
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "deletedTime": 1730204346000,
- "properties": {
- "space-name1": {
- "view-or-container-identifier1": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}, - "view-or-container-identifier2": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}, - "space-name2": {
- "view-or-container-identifier1": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}, - "view-or-container-identifier2": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}
}
}
], - "typing": {
- "space-name1": {
- "view-or-container-external-id1": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "view-or-container-external-id2": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}
}, - "space-name2": {
- "view-or-container-external-id1": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "view-or-container-external-id2": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}
}
}
}Sync nodes/edges
Subscribe to changes for nodes and edges in a project, matching a supplied filter. This endpoint will always return a NextCursor. The sync specification mirrors the query interface, but sorting is not currently supported. For more information, see Query language.
Authorizations:
Request Body schema: application/jsonrequired
Change filter specification
required | object [ 1 .. 50 ] properties |
object <= 50 properties Cursors returned from the previous sync request. These cursors match the result set expressions you specified in the | |
required | object [ 1 .. 50 ] properties |
object Parameters to return | |
| includeTyping | boolean (IncludeTyping) Should we return property type information as part of the result? |
| allowExpiredCursorsAndAcceptMissedDeletes | boolean Default: false Sync cursors will expire after 3 days. This is because soft-deleted instances are cleaned up after this grace period, so a client using a cursor older than that risks missing deletes. If this option is set to |
object (DebugParameters) Return query debug notices. |
Responses
Request samples
- Payload
- Python SDK
{- "with": {
- "property1": {
- "limit": 100,
- "skipAlreadyDeleted": true,
- "mode": "onePhase",
- "backfillSort": [
- {
- "property": [
- "string"
], - "direction": "ascending",
- "nullsFirst": false
}
], - "nodes": {
- "from": "string",
- "chainTo": "source",
- "through": {
- "view": {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "identifier": "string"
}, - "direction": "outwards",
- "filter": {
- "and": [
- {
- "in": {
- "property": [
- "tag"
], - "values": [
- 10011,
- 10011
]
}
}, - {
- "range": {
- "property": [
- "weight"
], - "gte": 0
}
}
]
}
}
}, - "property2": {
- "limit": 100,
- "skipAlreadyDeleted": true,
- "mode": "onePhase",
- "backfillSort": [
- {
- "property": [
- "string"
], - "direction": "ascending",
- "nullsFirst": false
}
], - "nodes": {
- "from": "string",
- "chainTo": "source",
- "through": {
- "view": {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "identifier": "string"
}, - "direction": "outwards",
- "filter": {
- "and": [
- {
- "in": {
- "property": [
- "tag"
], - "values": [
- 10011,
- 10011
]
}
}, - {
- "range": {
- "property": [
- "weight"
], - "gte": 0
}
}
]
}
}
}
}, - "cursors": {
- "sync cursor reference1": "string",
- "sync cursor reference2": "string"
}, - "select": {
- "property1": {
- "sources": [
- {
- "source": {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "properties": [
- "string"
], - "targetUnits": [
- {
- "property": "string",
- "unit": {
- "externalId": "string"
}
}
]
}
]
}, - "property2": {
- "sources": [
- {
- "source": {
- "type": "view",
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "properties": [
- "string"
], - "targetUnits": [
- {
- "property": "string",
- "unit": {
- "externalId": "string"
}
}
]
}
]
}
}, - "parameters": {
- "parameter-identifier1": "string",
- "parameter-identifier2": "string"
}, - "includeTyping": false,
- "allowExpiredCursorsAndAcceptMissedDeletes": false,
- "debug": {
- "emitResults": true,
- "timeout": 0,
- "includeTranslatedQuery": true,
- "includePlan": true,
- "profile": false
}
}Response samples
- 200
- 400
{- "items": {
- "result-expression1": [
- {
- "instanceType": "node",
- "version": 0,
- "space": "string",
- "externalId": "string",
- "type": {
- "space": "string",
- "externalId": "string"
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "deletedTime": 1730204346000,
- "properties": {
- "space-name1": {
- "view-or-container-identifier1": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}, - "view-or-container-identifier2": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}, - "space-name2": {
- "view-or-container-identifier1": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}, - "view-or-container-identifier2": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}
}
}
], - "result-expression2": [
- {
- "instanceType": "node",
- "version": 0,
- "space": "string",
- "externalId": "string",
- "type": {
- "space": "string",
- "externalId": "string"
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "deletedTime": 1730204346000,
- "properties": {
- "space-name1": {
- "view-or-container-identifier1": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}, - "view-or-container-identifier2": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}, - "space-name2": {
- "view-or-container-identifier1": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}, - "view-or-container-identifier2": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}
}
}
]
}, - "typing": {
- "result-expression1": {
- "space-name1": {
- "view-or-container-external-id1": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "view-or-container-external-id2": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}
}, - "space-name2": {
- "view-or-container-external-id1": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "view-or-container-external-id2": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}
}
}, - "result-expression2": {
- "space-name1": {
- "view-or-container-external-id1": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "view-or-container-external-id2": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}
}, - "space-name2": {
- "view-or-container-external-id1": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}, - "view-or-container-external-id2": {
- "property-identifier1": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}, - "property-identifier2": {
- "immutable": false,
- "nullable": true,
- "autoIncrement": false,
- "defaultValue": "string",
- "description": "string",
- "name": "string",
- "constraintState": {
- "nullability": "current",
- "maxListSize": "current",
- "maxTextSize": "current"
}, - "type": {
- "type": "text",
- "list": false,
- "maxListSize": 0,
- "maxTextSize": 0,
- "collation": "ucs_basic"
}
}
}
}
}
}, - "nextCursor": {
- "cursor-name1": "string",
- "cursor-name2": "string"
}, - "debug": {
- "notices": [
- {
- "code": "excessiveTimeout",
- "category": "invalidDebugOptions",
- "level": "warning",
- "hint": "string",
- "timeout": 0
}
], - "translatedQuery": {
- "query": { },
- "parameters": { }
}, - "plan": {
- "fullPlan": { },
- "profiled": true,
- "byIdentifier": { }
}
}
}Use the streams and records API to build high volume extensions to industrial knowledge graphs which are built with Data Modeling. The streams API lets you manage the streams that are used for storing records. With the API you can define the streams, and retrieve the streams, and eventually set and get settings (and statistics) associated with each stream.
Each project can have up to 10 active streams. A stream defines the data lifecycle, and not schema, type or source. Multiple different sets of data which have nothing in common can be put into the same stream, provided that settings of this stream fit lifecycle and usage patterns (volume, rate, etc) of the data involved.
Data in a stream has two phases which define access conditions (limits, latency, etc): hot phase and cold phase.
When ingested, data is in the hot phase and has the lowest access latency. As the time passes,
data transitions to the cold phase. Access to cold data can be slower and stricter limits may be applied.
It is expected that hot data will be accessed more often than the cold one.
The duration of each phase depends on the stream settings
(the stream creation template defines the settings at the moment of stream creation).
Customization of stream settings is possible, but there is no API for it yet.
To delete all data in a stream, the stream itself should be deleted. To protect against irretrievable erroneous deletion, streams are 'soft deleted' allowing them to be recovered for up to 6 weeks after the time of deletion. The template used to create the stream determines the actual recovery time.
A single project may have up to 100 soft deleted streams at any given time. To avoid hitting this limit, please
avoid using any pattern of create and delete streams in a high frequency.
Please note that we expect streams to be long lived. The exception are streams created
with one of the test templates. Deleting a stream can take a long time.
How long depends on the stream settings settings and the volume of data stored.
While a stream is soft deleted, it is not possible to recreate a stream with the same identifier as the deleted stream.
Once a stream is deleted, it does not count as one of the active streams, and more streams can be created to serve as active streams. If a stream is accidentally deleted, it is possible to recover the data by contacting Cognite early adopter program representative. You must contact Cognite no less than 1 week prior to the expiration of the stream retention period to ensure we can recover the data.
This section lists all currently available templates that can be used for creating streams.
NB! New templates can be added and existing ones can be modified or even deleted if we see a very strong need for it. However, such modifications will not affect existing streams.
Please contact your Cognite early adopter program representative if none of the existing templates seem suitable, as we can add new templates to cover particular needs.
Immutable streams
ImmutableTestStream
This template should be used exclusively for experimentation. It is configured for high throughput and total data volume, but has short data retention. Low retention in a soft-deleted state means that such streams can be quickly discarded when no longer needed, or recreated to get rid of the experimental data.
NB! This template should never be used for production purposes. As this template allows significant load on the system, if we detect improper usage patterns, we can change setting of streams created from this template as a last resort.
- Max number of unique properties with data across all records is 1000.
- Max number of records ingested per 10 minutes is 800,000 items.
- Max ingestion throughput per 10 minutes is 1.5GB.
- Max reading throughput per 10 minutes is 1.5GB.
- Maximum total number of records is 5B (5,000,000,000).
- Maximum total data volume is 500GB.
- Maximum range filter interval for the
lastUpdatedTimeproperty is 7 days. hotphase duration is 3 days.- Everything that is not
hotphase iscoldphase. - Data retention is 7 days.
- Stream stays in soft-deleted state before being hard-deleted for 1 day.
ImmutableDataStaging
This template is primarily intended for creating "staging area" streams where data is temporarily stored before being processed and moved to other streams. It can be used for other purposes where relatively short data retention is desired to reduce costs incurred by consumed storage volume.
- Max number of unique properties with data across all records is 1000.
- Max number of records ingested per 10 minutes is 170,000 items.
- Max ingestion throughput per 10 minutes is 170MB.
- Max reading throughput per 10 minutes is 500MB.
- Maximum total number of records is 100M (100,000,000).
- Maximum total data volume is 100GB.
- Maximum range filter interval for the
lastUpdatedTimeproperty is 31 day. hotphase duration is 31 day.- Everything that is not
hotphase iscoldphase. - Data retention is 31 day.
- Stream stays in soft-deleted state before being hard-deleted for 31 day.
ImmutableNormalizedData
This template is comparable to the ImmutableDataStaging, but has a longer data retention.
It can be used when up to 3 months of data retention and query period
are desired.
- Max number of unique properties with data across all records is 1000.
- Max number of records ingested per 10 minutes is 170,000 items.
- Max ingestion throughput per 10 minutes is 170MB.
- Max reading throughput per 10 minutes is 800MB.
- Maximum total number of records is 100M (100,000,000).
- Maximum total data volume is 100GB.
- Maximum range filter interval for the
lastUpdatedTimeproperty is 92 days. hotphase duration is 31 day.- Everything that is not
hotphase iscoldphase. - Data retention is 92 days.
- Stream stays in soft-deleted state before being hard-deleted for 6 weeks.
ImmutableArchive
This template is intended for perpetual storage of data. However, overall data volume is limited, which needs to be taken into account when planning usage.
- Max number of unique properties with data across all records is 1000.
- Max number of records ingested per 10 minutes is 170,000 items.
- Max ingestion throughput per 10 minutes is 170MB.
- Max reading throughput per 10 minutes is 1.7GB.
- Maximum total number of records is 5B (5,000,000,000).
- Maximum total data volume is 5TB.
- Maximum range filter interval for the
lastUpdatedTimeproperty is 365 days. hotphase duration is 45 days.- Everything that is not
hotphase iscoldphase. - Data retention is unlimited (data never gets deleted).
- Stream stays in soft-deleted state before being hard-deleted for 6 weeks.
Mutable streams
MutableTestStream
This template intended exclusively for experimentation, as it has a very limited capacity and throughput. Low retention in a soft-deleted state means that such streams can be quickly discarded when no longer needed, or recreated to get rid of the experimental data.
- Max number of unique properties with data across all records is 1000.
- Max number of records ingested per 10 minutes is 170,000 items.
- Max number of records updated or deleted per 10 minutes is 85,000 items.
- Max ingestion throughput per 10 minutes is 170MB.
- Max reading throughput per 10 minutes is 340MB.
- Maximum total number of records is 10M (10,000,000).
- Maximum total data volume is 20GB.
- Stream stays in soft-deleted state before being hard-deleted for 1 day.
MutableLiveData
This template is intended for production usage and offers significant data volume and throughput.
- Max number of unique properties with data across all records is 1000.
- Max number of records ingested per 10 minutes is 800,000 items.
- Max number of records updated or deleted per 10 minutes is 400,000 items.
- Max ingestion throughput per 10 minutes is 340MB.
- Max reading throughput per 10 minutes is 1.7GB.
- Maximum total number of records is 100M (100,000,000).
- Maximum total data volume is 300GB.
- Stream stays in soft-deleted state before being hard-deleted for 6 weeks.
Both the rate of requests (denoted as request per second, or ‘rps’) and the number of concurrent (parallel)
requests are governed by limits, for all CDF API endpoints. If a request exceeds one of the limits,
it will be throttled with a 429: Too Many Requests response. More on limit types
and how to avoid being throttled is described
here.
As streams are intended to be long-lived, users are not expected to interact with these endpoints frequently.
The version limits for the streams endpoints are illustrated in the diagram below. These limits are subject to change, pending review of changing consumption patterns and resource availability over time:

Create stream
Create a new stream. A stream is a target for high volume data ingestion, with data shaped by the Data Modeling concepts.
Authorizations:
Request Body schema: application/jsonrequired
Stream to create.
required | Array of objects (streamItems) [ items = 1 items ] List of streams. |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "test_stream_1",
- "settings": {
- "template": {
- "name": "ImmutableTestStream"
}
}
}
]
}Response samples
- 201
- 400
- 409
{- "items": [
- {
- "externalId": "test1",
- "createdTime": 1730204346000,
- "createdFromTemplate": "ImmutableTestStream",
- "type": "Immutable",
- "settings": {
- "lifecycle": {
- "hotPhaseDuration": "P31D",
- "dataDeletedAfter": "P1Y",
- "retainedAfterSoftDelete": "P42D"
}, - "limits": {
- "maxRecordsTotal": {
- "provisioned": 1000,
- "consumed": 999
}, - "maxGigaBytesTotal": {
- "provisioned": 1000,
- "consumed": 999
}, - "maxFilteringInterval": "P1Y"
}
}
}
]
}Delete stream
Delete a stream by its identifier, along with all records stored in the stream.
Authorizations:
path Parameters
| streamId required | string [ 1 .. 100 ] characters ^[a-z]([a-z0-9_-]{0,98}[a-z0-9])?$ Example: test1 An identifier of the stream where the records are stored. |
Responses
Response samples
- 200
- 400
{ }List streams
List all streams available in the project.
Authorizations:
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "test1",
- "createdTime": 1730204346000,
- "createdFromTemplate": "ImmutableTestStream",
- "type": "Immutable",
- "settings": {
- "lifecycle": {
- "hotPhaseDuration": "P31D",
- "dataDeletedAfter": "P1Y",
- "retainedAfterSoftDelete": "P42D"
}, - "limits": {
- "maxRecordsTotal": {
- "provisioned": 1000,
- "consumed": 999
}, - "maxGigaBytesTotal": {
- "provisioned": 1000,
- "consumed": 999
}, - "maxFilteringInterval": "P1Y"
}
}
}
]
}Retrieve stream
Retrieve a stream by its identifier.
Authorizations:
path Parameters
| streamId required | string [ 1 .. 100 ] characters ^[a-z]([a-z0-9_-]{0,98}[a-z0-9])?$ Example: test1 An identifier of the stream where the records are stored. |
query Parameters
| includeStatistics | boolean NB! This parameter can only be specified if request has an alpha cdf-version header, otherwise the request would be considered invalid. If set to |
Responses
Response samples
- 200
- 400
{- "externalId": "test1",
- "createdTime": 1730204346000,
- "createdFromTemplate": "ImmutableTestStream",
- "type": "Immutable",
- "settings": {
- "lifecycle": {
- "hotPhaseDuration": "P31D",
- "dataDeletedAfter": "P1Y",
- "retainedAfterSoftDelete": "P42D"
}, - "limits": {
- "maxRecordsTotal": {
- "provisioned": 1000,
- "consumed": 999
}, - "maxGigaBytesTotal": {
- "provisioned": 1000,
- "consumed": 999
}, - "maxFilteringInterval": "P1Y"
}
}
}Records are immutable data objects that are stored in a stream. Records are created by ingesting data into a stream.
Records have similar shape as you have for instances that live in the Data Modeling service,
and their schema is defined by the containers that are referenced as sources.
Each record item also links to the space that the record belongs to. This means we also support space based access control for records.
This page contains the specification for records resource which uses the next Data Modeling concepts:
Note: Every record has a required top-level externalId property, which can be used
in some queries to retrieve or aggregate records (as a filtering or sorting property).
In the future, this property (together with the space property) will be used to
uniquely identify mutable records for write operations (create/upsert/delete).
During immutable record creation, the uniqueness of the space + externalId pair is not enforced by the records API.
However, this uniqueness will be enforced for all write operations (create/upsert/delete) involving mutable records in the future.
Both the rate of requests (denoted as request per second, or ‘rps’) and the number of concurrent (parallel)
requests are governed by limits, for all CDF API endpoints. If a request exceeds one of the limits,
it will be throttled with a 429: Too Many Requests response. More on limit types
and how to avoid being throttled is described
here.
Limits are defined on the API endpoints belonging to the service. Some types of requests consume more resources (compute, storage IO) than others. For example, ingest requests are less resource intensive than ‘Analytical’ type requests (Aggregate, Retrieve).
Limits for query endpoints (Sync, Retrieve, Aggregate) have a hierarchical structure. Top level limits include requests to all of these endpoints. In addition, there are dedicated limits for Retrieve and Aggregate endpoint. For example, it is possible to send up to 40 rps to Sync, Retrieve and Aggregate endpoints together, but only up to 20 of them can go to Retrieve endpoint and up to 15 to Aggregate endpoint.
Since requests that touch cold data can be considerably slower and consume more resources,
query endpoints (Sync, Retrieve, Aggregate) have different limits for hot and cold data.
It is therefore important to build use cases so that frequent operations are performed only on hot data
and cold data is touched less often. In the future multiple stream creation templates with different
hot storage durations will be available to choose from.
For Retrieve and Aggregate endpoints a request is considered to touch cold data
if interval defined by the lastUpdatedTime filter extends beyond the stream's hot storage duration.
For Sync endpoint a request is considered to touch cold data if its cursor attribute
points to the data that is in the cold storage. If cursor attribute is not provided,
initializeCursor attribute is considered instead.
Amount of data that the service can return in responses to query endpoints (Sync, Retrieve, Aggregate)
is also limited. It is therefore recommended reading only data that will actually be used
(by providing appropriate filter and/or limiting the sources to be retrieved) rather than
retrieving excessive amounts of data most of which will not be used.
The version limits for the records endpoints are illustrated in the diagram below. These limits are subject to change, pending review of changing consumption patterns and resource availability over time:
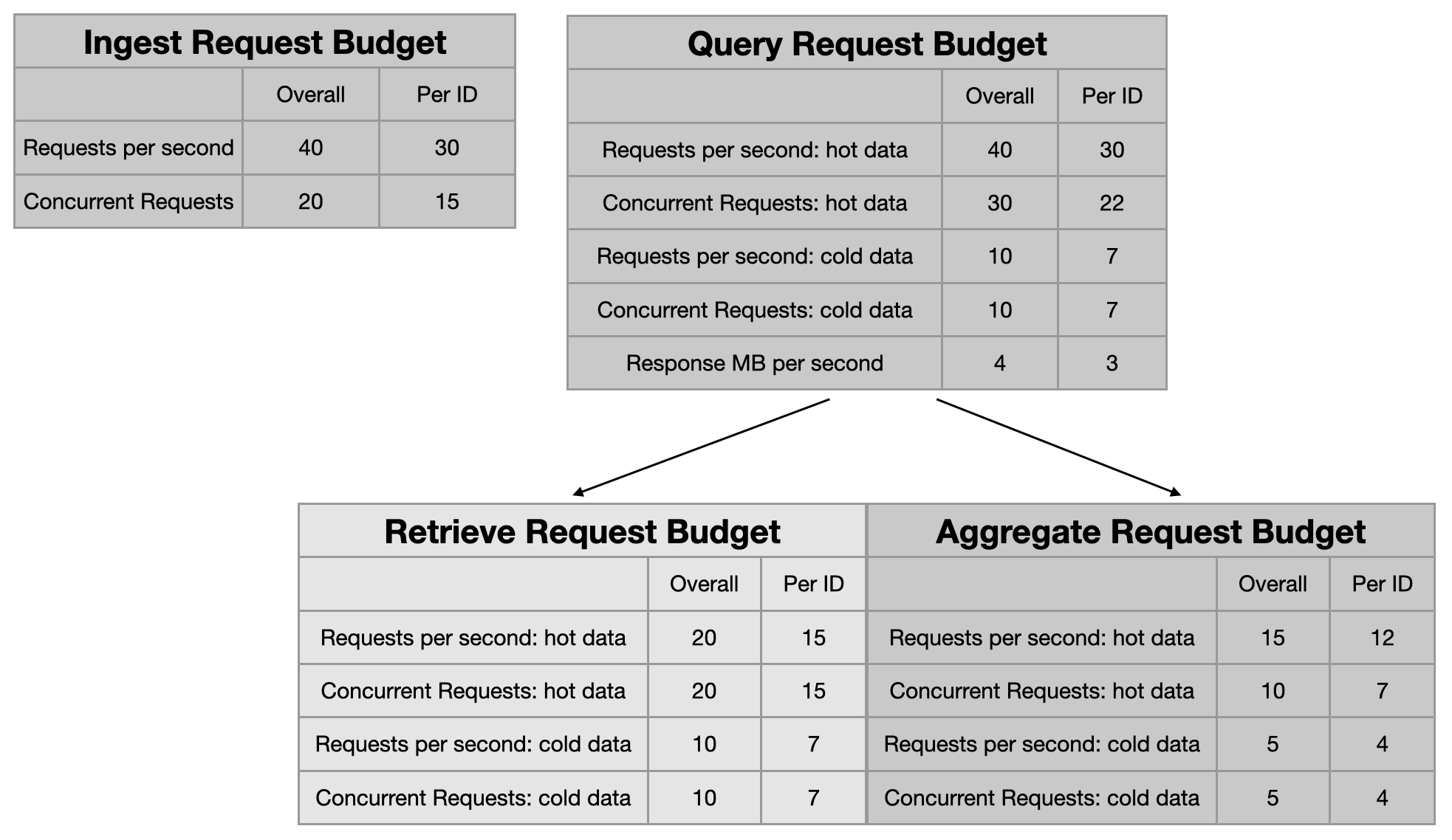
Aggregate records data from a stream
Aggregate data for records from the stream.
You can use an optional filter specification to limit the results.
The Records API supports three main groups of aggregates:
Metric aggregates: sum, min, max, count, etc.
Bucket aggregates (result records are aggregated into groups (buckets) — similar to the Data Model Instances groupBy concept):
uniqueValues (group by property values), timeHistogram (group by date/time ranges), filters (group by filter criteria), etc.
Pipeline aggregates: movingFunction.
Note: The pipeline aggregate applies to the results of another histogram aggregate.
It applies to metrics (such as count, min, max, sum, etc.), not to the records in the parent aggregate buckets.
This differs from sub-aggregates, which apply directly to records within each bucket.
Every aggregate request can contain multiple aggregate entries. Every bucket aggregate can contain multiple sub-aggregates (of any type), which are applied to records in each bucket of the parent aggregate.
Example:
Imagine there is paddle-tennis players game_statistics container with model:
{
game_id: Long,
game_time: Instant,
player_name: String,
points_scored: Int,
...
}
To get the following data:
for each day
calculate average number of points scored by players in all games on that day
and for each player
calculate the total number of points scored by the player in all games they participated in on that day
and find the max number of points scored by the player in all games they participated in on that day
and find the max number of points scored by players in all games they participated in during the entire search period.
Use aggregates like these (meta language):
timeHistogram(daily, game_time) // group by (form buckets) 1-day range based on `game_time` property values
avg(points_scored) // inside every day group calculate average value in `points_scored` property
uniqueValues(player_name) // inside every day group group by (form buckets) player names
sum(points_scored) // inside every player group which is inside every day group calculate the sum of points scored
max(points_scored) // inside every player group which is inside every day group find the maximum of points scored
max(points_scored) // find the maximum number of points scored across all statistic records (without any grouping)
Or the same in Cognite Records Aggregates DSL (Json):
{
"my_groups_by_1d_range": {
"timeHistogram": {
"calendarInterval": "1d",
"property": [ "paddle", "game_statistics", "game_time" ],
"aggregates": {
"my_groups_by_player_name": {
"uniqueValues": {
"property": [ "paddle", "game_statistics", "player_name" ],
"aggregates": {
"my_player_daily_scores_sum": {
"sum": { "property": [ "paddle", "game_statistics", "points_scored" ] }
},
"my_player_daily_scores_maximum": {
"max": { "property": [ "paddle", "game_statistics", "points_scored" ] }
}
}
}
},
"my_daily_scores_average": {
"avg": { "property": [ "paddle", "game_statistics", "points_scored" ] }
}
}
}
},
"my_scores_maximum_across_all_games": {
"max": { "property": [ "paddle", "game_statistics", "points_scored" ] }
}
}
and the response would be
{
"my_groups_by_1d_range": {
"timeHistogramBuckets": [
{
"count": 13
"intervalStart": "2025-05-25T00:00:00Z",
"aggregates": {
"my_groups_by_player_name": {
"uniqueValueBuckets": [
{
"count": 3
"value": "Vasya Rogov",
"aggregates": {
"my_player_daily_scores_sum": {
"sum": 57
},
"my_player_daily_scores_maximum": {
"max": 25
}
}
},
{
"count": 5
"value": "Vinni Pooh",
"aggregates": {
"my_player_daily_scores_sum": {
"sum": 53
},
"my_player_daily_scores_maximum": {
"max": 21
}
}
},
...
]
},
"my_daily_scores_average": {
"avg": 33
}
}
},
{
"count": 7
"intervalStart": "2025-05-26T00:00:00Z",
"aggregates": {
"my_groups_by_player_name": {
"uniqueValueBuckets": [
{
"count": 1
"value": "Vasya Rogov",
"aggregates": {
"my_player_daily_scores_sum": {
"sum": 24
},
"my_player_daily_scores_maximum": {
"max": 24
}
}
},
{
"count": 2
"value": "Pyatochok",
"aggregates": {
"my_player_daily_scores_sum": {
"sum": 42
},
"my_player_daily_scores_maximum": {
"max": 23
}
}
},
...
]
},
"my_daily_scores_average": {
"avg": 22
}
}
},
...
]
},
"my_scores_maximum_across_all_games": {
"max": 42
}
}
Authorizations:
path Parameters
| streamId required | string [ 1 .. 100 ] characters ^[a-z]([a-z0-9_-]{0,98}[a-z0-9])?$ Example: test1 An identifier of the stream where the records are stored. |
Request Body schema: application/jsonrequired
Aggregation specification.
object (lastUpdatedTime) Matches records with the last updated time within the provided range. This attribute is mandatory for immutable streams but it's optional for mutable streams. The maximum time interval that can be defined by the attribute is limited by the stream settings. If more data needs to be queried than allowed by the stream settings, it should be done with multiple requests. For example, if stream allows querying up to 1 month of data, but a quarterly report is needed, the solution is to make 3 requests, one for each month, and then aggregate the responses. The range must include at least a left ( Note: | |
(boolFilter (and (object) or or (object) or not (object))) or (leafFilter (matchAll (object) or exists (object) or equals (object) or hasData (object) or prefix (object) or range (object) or in (object) or containsAll (object) or containsAny (object))) (filter) A filter Domain Specific Language (DSL) used to create advanced filter queries. Note: the max number of nodes in the filter tree is 100 and the max tree depth is 10. | |
required | object (aggregatesDictionary) [ 1 .. 5 ] properties unique A dictionary of requested aggregates with client defined names/identifiers. Example: Max number of (sub-)aggregate trees on a level is 5, Max aggregate tree depth is 5. Max number of aggregates in the forest is 16. |
Responses
Request samples
- Payload
{- "lastUpdatedTime": {
- "gt": 1705341600000,
- "lt": "2030-05-15T18:00:00.00Z"
}, - "filter": {
- "and": [
- {
- "containsAll": {
- "property": [
- "mySpace",
- "myContainer",
- "myProperty"
], - "values": [
- 10011,
- 10012
]
}
}, - {
- "range": {
- "property": [
- "my_space",
- "my_container",
- "my_weight"
], - "gte": 0
}
}
]
}, - "aggregates": {
- "my_avg_aggregate1": {
- "avg": {
- "property": [
- "mySpace",
- "myContainer",
- "manufacturer"
]
}
}, - "my_terms_aggregate2": {
- "uniqueValues": {
- "property": [
- "mySpace",
- "myContainer",
- "manufacturer"
], - "aggregates": {
- "my_sub_aggregate1": {
- "min": {
- "property": [
- "mySpace",
- "myContainer",
- "price"
]
}
}, - "my_sub_aggregate2": {
- "max": {
- "property": [
- "mySpace",
- "myContainer",
- "price"
]
}
}, - "my_sub_aggregate3": {
- "uniqueValues": {
- "property": [
- "mySpace",
- "myContainer",
- "region"
]
}
}
}
}
}
}
}Response samples
- 200
- 400
{- "aggregates": {
- "my_avg_aggregate1": {
- "avg": 42
}, - "my_terms_aggregate2": {
- "uniqueValueBuckets": [
- {
- "value": "Cognite",
- "count": 42,
- "aggregates": {
- "my_sub_aggregate1": {
- "min": 13
}, - "my_sub_aggregate2": {
- "max": 69
}, - "my_sub_aggregate3": {
- "uniqueValueBuckets": [
- {
- "value": "us1",
- "count": 42
}, - {
- "value": "ie1",
- "count": 7
}
]
}
}
}, - {
- "value": "AkerBP",
- "count": 21,
- "aggregates": {
- "my_sub_aggregate1": {
- "min": 99
}, - "my_sub_aggregate2": {
- "max": 999
}, - "my_sub_aggregate3": {
- "uniqueValueBuckets": [
- {
- "value": "us1",
- "count": 11
}
]
}
}
}
]
}
}
}Delete records from a stream
NB! This endpoint is only available for mutable streams. Mutable streams is an alpha feature, so this endpoint requires cdf-version header to be set to alpha.
To delete records, the user must have capabilities to access (write to) the referenced record space.
Batches of records are deleted from a stream with implicit ignoreUnknownIds=true semantic.
The record operations are eventually consistent, but under normal conditions deleted records stop being returned by other endpoints within a few seconds. Sync endpoint is returning a "tombstone" record (which only has a few top level fields and a deleted status) for at least 3 days since deleting the actual record.
Authorizations:
path Parameters
| streamId required | string [ 1 .. 100 ] characters ^[a-z]([a-z0-9_-]{0,98}[a-z0-9])?$ Example: test1 An identifier of the stream where the records are stored. |
Request Body schema: application/jsonrequired
Records to delete from a stream.
required | Array of objects (recordItems) [ 1 .. 1000 ] items List of records to delete. |
Responses
Request samples
- Payload
{- "items": [
- {
- "space": "mySpace",
- "externalId": "some_id"
}
]
}Response samples
- 204
- 400
- 422
- 500
- 503
{ }Ingest records into a stream
Before a user can add records, all referenced schema elements (Spaces, Containers, Properties) must be defined/created in Data Modeling
To add records, the user must have capabilities to access (read to) the referenced containers as well as capabilities to access (write to) the referenced record space.
Batches of records are ingested into a stream.
Under normal ingestion operation, and where the data stream does not contain any duplicated records,
the record will be created, and the properties defined in each of the containers in the sources array will be populated.
For immutable streams a duplicate record is defined as one which is being written to the same space,
which uses the same container definitions in the sources array,
and all the properties (names and values) are the same.
For immutable streams under most circumstances, when duplicate records are encountered during ingestion, the duplicate is discarded. However there are rare occasions when certain internal database operations occur, a duplicate may be stored.
For mutable streams duplicated record identifiers (space + externalId) are not allowed
and a request which tries to create a record with existing identifier will be rejected.
Note: The maximum total request size is 10MB.
Authorizations:
path Parameters
| streamId required | string [ 1 .. 100 ] characters ^[a-z]([a-z0-9_-]{0,98}[a-z0-9])?$ Example: test1 An identifier of the stream where the records are stored. |
Request Body schema: application/jsonrequired
Records to ingest into a stream.
required | Array of objects (recordItems) [ 1 .. 1000 ] items List of records to write. |
Responses
Request samples
- Payload
{- "items": [
- {
- "space": "mySpace",
- "externalId": "some_id",
- "sources": [
- {
- "source": {
- "type": "container,",
- "space": "mySpace,",
- "externalId": "myContainer"
}, - "properties": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}
]
}
]
}Response samples
- 202
- 400
- 409
- 422
- 500
- 503
{ }Retrieve records from a stream
Filter the records from the stream.
Authorizations:
path Parameters
| streamId required | string [ 1 .. 100 ] characters ^[a-z]([a-z0-9_-]{0,98}[a-z0-9])?$ Example: test1 An identifier of the stream where the records are stored. |
Request Body schema: application/jsonrequired
Filter records based on the last updated time, on the space and on container(s) properties. The response supports custom sorting. Otherwise, the records in the response are sorted by last updated time.
object (lastUpdatedTime) Matches records with the last updated time within the provided range. This attribute is mandatory for immutable streams but it's optional for mutable streams. The maximum time interval that can be defined by the attribute is limited by the stream settings. If more data needs to be queried than allowed by the stream settings, it should be done with multiple requests. For example, if stream allows querying up to 1 month of data, but a quarterly report is needed, the solution is to make 3 requests, one for each month, and then aggregate the responses. The range must include at least a left ( Note: | |
(boolFilter (and (object) or or (object) or not (object))) or (leafFilter (matchAll (object) or exists (object) or equals (object) or hasData (object) or prefix (object) or range (object) or in (object) or containsAll (object) or containsAny (object))) (filter) A filter Domain Specific Language (DSL) used to create advanced filter queries. Note: the max number of nodes in the filter tree is 100 and the max tree depth is 10. | |
Array of objects (propertiesPerContainer) [ 1 .. 10 ] items List of containers and their properties which values should be selected for the response. | |
| limit | integer [ 1 .. 1000 ] Default: 10 Limits the number of results to return. |
Array of objects (orderedSortSpecList) [ 1 .. 5 ] items Ordered list of sorting specifications (property, direction, etc) to sort on. |
Responses
Request samples
- Payload
{- "lastUpdatedTime": {
- "gt": 1705341600000,
- "lt": "2030-05-15T18:00:00.00Z"
}, - "filter": {
- "and": [
- {
- "containsAll": {
- "property": [
- "mySpace",
- "myContainer",
- "myProperty"
], - "values": [
- 10011,
- 10012
]
}
}, - {
- "range": {
- "property": [
- "my_space",
- "my_container",
- "my_weight"
], - "gte": 0
}
}
]
}, - "sources": [
- {
- "source": {
- "type": "container,",
- "space": "mySpace,",
- "externalId": "myContainer"
}, - "properties": [
- "someProperty"
]
}
], - "limit": 42,
- "sort": [
- {
- "property": [
- "space"
], - "direction": "descending"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "space": "mySpace",
- "externalId": "some_id",
- "createdTime": 1720616232,
- "lastUpdatedTime": 1720616232,
- "properties": {
- "space-name1": {
- "container-identifier1": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}, - "container-identifier2": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}, - "space-name2": {
- "container-identifier1": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}, - "container-identifier2": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}
}
}
]
}Sync records from a stream
Subscribe to changes for records from the stream, matching a supplied filter.
Authorizations:
path Parameters
| streamId required | string [ 1 .. 100 ] characters ^[a-z]([a-z0-9_-]{0,98}[a-z0-9])?$ Example: test1 An identifier of the stream where the records are stored. |
Request Body schema: application/jsonrequired
Change filter specification.
Array of objects (propertiesPerContainer) [ 1 .. 10 ] items List of containers and their properties which values should be selected for the response. | |
(boolFilter (and (object) or or (object) or not (object))) or (leafFilter (matchAll (object) or exists (object) or equals (object) or hasData (object) or prefix (object) or range (object) or in (object) or containsAll (object) or containsAny (object))) (filter) A filter Domain Specific Language (DSL) used to create advanced filter queries. Note: the max number of nodes in the filter tree is 100 and the max tree depth is 10. | |
| cursor | string [ 1 .. 100500 ] characters A cursor returned from the previous sync request. |
| initializeCursor | string [ 6 .. 500 ] characters The format is " If Note that |
| limit | integer [ 1 .. 1000 ] Default: 10 Limits the number of results to return. |
Responses
Request samples
- Payload
{- "sources": [
- {
- "source": {
- "type": "container,",
- "space": "mySpace,",
- "externalId": "myContainer"
}, - "properties": [
- "someProperty"
]
}
], - "filter": {
- "and": [
- {
- "containsAll": {
- "property": [
- "mySpace",
- "myContainer",
- "myProperty"
], - "values": [
- 10011,
- 10012
]
}
}, - {
- "range": {
- "property": [
- "my_space",
- "my_container",
- "my_weight"
], - "gte": 0
}
}
]
}, - "cursor": "c29tZSBjdXJzb3I=",
- "initializeCursor": "42d-ago",
- "limit": 42
}Response samples
- 200
- 400
{- "items": [
- {
- "space": "mySpace",
- "externalId": "some_id",
- "createdTime": 1720616232,
- "lastUpdatedTime": 1720616232,
- "properties": {
- "space-name1": {
- "container-identifier1": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}, - "container-identifier2": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}, - "space-name2": {
- "container-identifier1": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}, - "container-identifier2": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}
}, - "status": "created"
}
], - "nextCursor": "c29tZSBjdXJzb3I=",
- "hasNext": true
}Upsert (create or update) records into a stream
NB! This endpoint is only available for mutable streams. Mutable streams is an alpha feature, so this endpoint requires cdf-version header to be set to alpha.
Before a user can upsert records, all referenced schema elements (Spaces, Containers, Properties) must be defined/created in Data Modeling.
To upsert records, the user must have capabilities to access (read to) the referenced containers as well as capabilities to access (write to) the referenced record space.
Batches of records are ingested or updated into a stream.
Under normal upsert operation, the record will be created or updated, and the properties defined in each of the containers in the sources array will be populated.
If record identifiers (space + externalId) are already in the stream, records are fully updated (no partial updates for this endpoint).
Otherwise, records are created.
Note: The maximum total request size is 10MB.
Authorizations:
path Parameters
| streamId required | string [ 1 .. 100 ] characters ^[a-z]([a-z0-9_-]{0,98}[a-z0-9])?$ Example: test1 An identifier of the stream where the records are stored. |
Request Body schema: application/jsonrequired
Records to upsert into a stream.
required | Array of objects (recordItems) [ 1 .. 1000 ] items List of records to write. |
Responses
Request samples
- Payload
{- "items": [
- {
- "space": "mySpace",
- "externalId": "some_id",
- "sources": [
- {
- "source": {
- "type": "container,",
- "space": "mySpace,",
- "externalId": "myContainer"
}, - "properties": {
- "someStringProperty": "someStringValue",
- "someDirectRelation": {
- "space": "mySpace",
- "externalId": "someNode"
}, - "someIntArrayProperty": [
- 1,
- 2,
- 3,
- 4
]
}
}
]
}
]
}Response samples
- 202
- 400
- 409
- 422
- 500
- 503
{ }The assets resource type stores digital representations of objects or groups of objects from the physical world. Assets are organized in hierarchies. For example, a water pump asset can be a part of a subsystem asset on an oil platform asset.
Both the rate of requests (denoted as request per second, or ‘rps’) and the number of concurrent (parallel) requests are governed by limits,
for all CDF API endpoints. If a request exceeds one of the limits,
it will be throttled with a 429: Too Many Requests response. More on limit types
and how to avoid being throttled is described
here.
Limits are defined at both the overall API service level, and on the API endpoints belonging to the service.
Some types of requests consume more resources (compute, storage IO) than others, and where a service handles
multiple concurrent requests with varying resource consumption.
For example, ‘CRUD’ type requests (Create, Retrieve, Request ByIDs, Update and Delete) are far less resource
intensive than ‘Analytical’ type requests (List, Search and Filter) and in addition, the most resource
intensive Analytical endpoint of all, Aggregates, receives its own request budget within the overall Analytical request budget.
The version 1.0 limits for the overall API service and its constituent endpoints are illustrated in the diagram below.
These limits are subject to change, pending review of changing consumption patterns and resource availability over time:
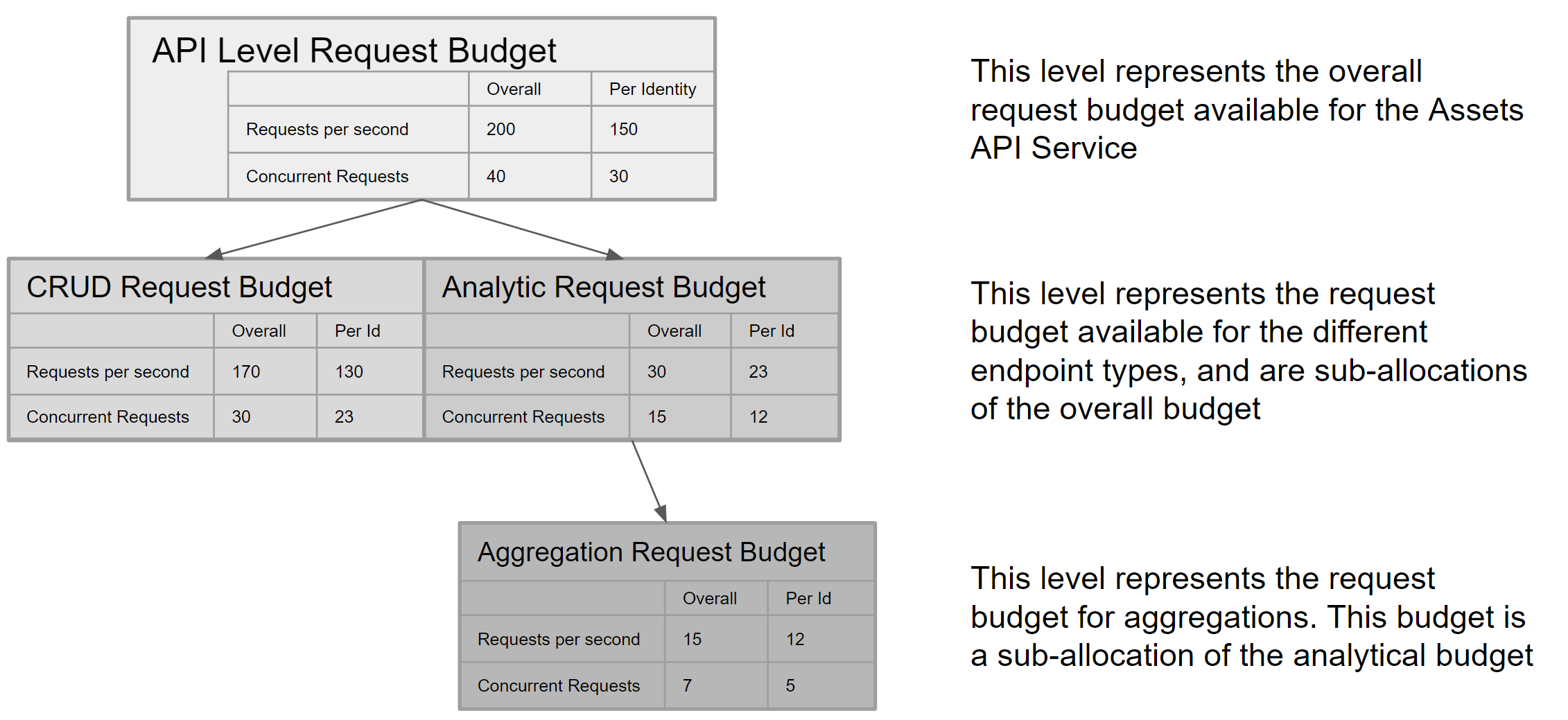
Translating RPS into data speed
A single request may retrieve up to 1000 items. In the context of Assets, 1 item = 1 asset record
Therefore, the maximum theoretical data speed at the top API service level is 200,000 items per second for all consumers,
and 150,000 for a single identity or client in a project.
Use of Partitions / Parallel Retrieval
As a general guidance, Parallel Retrieval is a technique that should be used where due to query complexity, retrieval of data in a single request session turns out to be slow. By parallelizing such requests, data retrieval performance can be tuned to meet the client application needs. Parallel retrieval may also be used where retrieval of large sets of data is required, up to the capacity limits defined for a given API service. For example (using the Assets API request budget):
- A single request may retrieve up to 1000 items
- Up to 23 requests per second may be issued for an analytical query (per identity), such as when using /list or /filter API endpoints
- This provides a theoretical maximum of 23,000 items read per second per identity
- The query complexity may result in it taking longer than 1s to read or write 1000 items in a single request
- Therefore, it is appropriate to specify the query to retrieve a lower number of items per request, and retrieve more items in parallel, up to the theoretical maximum performance of 23,000 items per second.
Important Note:
Parallel retrieval should be only used in situations where, due to query complexity,
a single request flow provides data retrieval speeds that are significantly less than the theoretical maximum.
Parallel retrieval does not act as a speed multiplier on optimally running queries. Regardless of the number
of concurrent requests issued, the overall requests per second limit still applies.
So for example, a single request returning data at approximately 18,000 items per second will only
benefit from adding a second parallel request, the capacity of which goes somewhat wasted
as only an additional 5,000 items per second will return before the request rate budget limit is reached.
Aggregate assets
The aggregation API lets you compute aggregated results on assets, such as getting the count of all assets in a project, checking different names and descriptions of assets in your project, etc.
Aggregate filtering
Filter (filter & advancedFilter) data for aggregates
Filters behave the same way as for the Filter assets endpoint.
In text properties, the values are aggregated in a case-insensitive manner.
aggregateFilter to filter aggregate results
aggregateFilter works similarly to advancedFilter but always applies to aggregate properties.
For instance, in case of an aggregation for the source property, only the values (aka buckets) of the source property can be filtered out.
Request throttling
This endpoint is meant for data analytics/exploration usage and is not suitable for high load data retrieval usage.
It is a subject of the new throttling schema (limited request rate and concurrency).
Please check Assets resource description for more information.
Authorizations:
Request Body schema: application/json
| aggregate | string Value: "count" Type of aggregation to apply.
| ||||||||||||||||||||||||||||
(BoolFilter (and (object) or or (object) or not (object))) or (LeafFilter (equals (object) or in (object) or range (object) or prefix (object) or exists (object) or containsAny (object) or containsAll (object) or search (object))) A filter DSL (Domain Specific Language) to define advanced filter queries. See more information about filtering DSL here. Supported properties:
Note: Filtering on the | |||||||||||||||||||||||||||||
object (Filter) Filter on assets with strict matching. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "aggregate": "count",
- "advancedFilter": {
- "or": [
- {
- "not": {
- "and": [
- {
- "equals": {
- "property": [
- "metadata",
- "asset_type"
], - "value": "gas pump"
}
}, - {
- "in": {
- "property": [
- "source"
], - "values": [
- "blueprint",
- "inventory"
]
}
}, - {
- "range": {
- "property": [
- "dataSetId"
], - "gte": 1,
- "lt": 10
}
}
]
}
}, - {
- "and": [
- {
- "containsAny": {
- "property": [
- "labels"
], - "values": [
- "pump",
- "cooler"
]
}
}, - {
- "equals": {
- "property": [
- "parentId"
], - "value": 95867294876
}
}
]
}, - {
- "search": {
- "property": [
- "description"
], - "value": "My favorite pump"
}
}
]
}, - "filter": {
- "name": "string",
- "parentIds": [
- 1
], - "parentExternalIds": [
- "my.known.id"
], - "rootIds": [
- {
- "id": 1
}
], - "assetSubtreeIds": [
- {
- "id": 1
}
], - "dataSetId": {
- "in": [
- {
- "id": 123
}, - {
- "externalId": "my.known.id"
}
], - "isNull": true
}, - "dataSetIds": [
- {
- "id": 1
}
], - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "createdTime": {
- "max": 0,
- "min": 0
}, - "lastUpdatedTime": {
- "max": 0,
- "min": 0
}, - "root": true,
- "externalIdPrefix": "my.known.prefix",
- "labels": {
- "containsAny": [
- {
- "externalId": "my.known.id"
}
]
}, - "geoLocation": {
- "relation": "INTERSECTS",
- "shape": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}
}
}
}Response samples
- 200
- 400
- 429
{- "items": [
- {
- "count": 10
}
]
}Create assets
Create multiple asset objects in the same project. It is possible to create a maximum of 1000 assets per request.
Request throttling
This endpoint is a subject of the new throttling schema (limited request rate and concurrency). Please check Assets resource description for more information.
Authorizations:
Request Body schema: application/jsonrequired
List of the assets to create. You can create a maximum of 1000 assets per request.
required | Array of objects (DataExternalAssetItem) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "parentId": 1,
- "parentExternalId": "my.known.id",
- "description": "string",
- "dataSetId": 1,
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}
}
]
}Response samples
- 201
- 400
- 429
{- "items": [
- {
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "rootId": 1,
- "aggregates": {
- "childCount": 0,
- "depth": 0,
- "path": [
- {
- "id": 1
}
]
}, - "parentId": 1,
- "parentExternalId": "my.known.id",
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1
}
]
}Delete assets
Delete assets. By default, recursive=false and the request would fail if attempting to delete assets that are referenced as parent by other assets.
To delete such assets and all its descendants, set recursive to true.
The limit of the request does not include the number of descendants that are deleted.
Request throttling
This endpoint is a subject of the new throttling schema (limited request rate and concurrency). Please check Assets resource description for more information.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of AssetInternalId (object) or AssetExternalId (object) (AssetIdEither) [ 1 .. 1000 ] items |
| recursive | boolean Default: false Recursively delete all asset subtrees under the specified IDs. |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1
}
], - "recursive": false,
- "ignoreUnknownIds": false
}Response samples
- 200
- 400
- 429
{ }Filter assets
Retrieve a list of assets in the same project. This operation supports pagination by cursor. Apply Filtering and Advanced filtering criteria to select a subset of assets.
Advanced filtering
Advanced filter lets you create complex filtering expressions that combine simple operations,
such as equals, prefix, exists, etc., using boolean operators and, or, and not.
It applies to basic fields as well as metadata.
See the advancedFilter attribute in the example.
See more information about filtering DSL here.
Supported leaf filters
| Leaf filter | Supported fields | Description |
|---|---|---|
containsAll |
Array type fields | Only includes results which contain all of the specified values. {"containsAll": {"property": ["property"], "values": [1, 2, 3]}} |
containsAny |
Array type fields | Only includes results which contain at least one of the specified values. {"containsAny": {"property": ["property"], "values": [1, 2, 3]}} |
equals |
Non-array type fields | Only includes results that are equal to the specified value. {"equals": {"property": ["property"], "value": "example"}} |
exists |
All fields | Only includes results where the specified property exists (has value). {"exists": {"property": ["property"]}} |
in |
Non-array type fields | Only includes results that are equal to one of the specified values. {"in": {"property": ["property"], "values": [1, 2, 3]}} |
prefix |
String type fields | Only includes results which start with the specified value. {"prefix": {"property": ["property"], "value": "example"}} |
range |
Non-array type fields | Only includes results that fall within the specified range. {"range": {"property": ["property"], "gt": 1, "lte": 5}} Supported operators: gt, lt, gte, lte |
search |
["name"], ["description"] |
Introduced to provide functional parity with /assets/search endpoint. {"search": {"property": ["property"], "value": "example"}} |
Search
The search leaf filter provides functional parity with the /assets/search endpoint.
It's available only for the ["description"] and ["name"] properties. When specifying only this filter with no explicit ordering,
behavior is the same as of the /assets/search/ endpoint without specifying filters.
Explicit sorting overrides the default ordering by relevance.
It's possible to use the search leaf filter as any other leaf filter for creating complex queries.
See the search filter in the advancedFilter attribute in the example.
advancedFilter attribute limits
- filter query max depth: 10
- filter query max number of clauses: 100
andandorclauses must have at least one elementpropertyarray of each leaf filter has the following limitations:- number of elements in the array is in the range [1, 2]
- elements must not be blank
- each element max length is 128 symbols
- property array must match one of the existing properties (static or dynamic metadata).
containsAll,containsAny, andinfiltervaluesarray size must be in the range [1, 100]containsAll,containsAny, andinfiltervaluesarray must contain elements of a primitive type (number, string)rangefilter must have at least one ofgt,gte,lt,lteattributes. Butgtis mutually exclusive togte, whileltis mutually exclusive tolte. At least one of the bounds must be specified.gt,gte,lt,ltein therangefilter must be a primitive valuesearchfiltervaluemust not be blank and the length must be in the range [1, 128]- filter query may have maximum 2 search leaf filters
- maximum leaf filter string value length is different depending on the property the filter is using:
externalId- 255name- 128 for thesearchfilter and 255 for other filtersdescription- 128 for thesearchfilter and 255 for other filterslabelsitem - 255source- 128- any
metadatakey - 128
Sorting
By default, assets are sorted by id in the ascending order.
Use the search leaf filter to sort the results by relevance.
Sorting by other fields can be explicitly requested. The order field is optional
and defaults to desc for _score_ and asc for all other fields.
The nulls field is optional and defaults to auto. auto is translated to
last for the asc order and to first for the desc order by the service.
Partitions are done independently of sorting; there's no guarantee of the sort order between elements from different partitions.
See the sort attribute in the example.
Null values
In case the nulls attribute has the auto value or the attribute isn't specified,
null (missing) values are considered to be bigger than any other values.
They are placed last when sorting in the asc order and first when sorting in desc.
Otherwise, missing values are placed according to the nulls attribute (last or first), and their placement doesn't depend on the order value.
Values, such as empty strings, aren't considered as nulls.
Sorting by score
Use a special sort property _score_ when sorting by relevance.
The more filters a particular asset matches, the higher its score is. This can be useful,
for example, when building UIs. Let's assume we want exact matches to be be displayed above matches by
prefix as in the request below. An asset named pump will match both equals and prefix
filters and, therefore, have higher score than assets with names like pump valve that match only prefix filter.
"advancedFilter" : {
"or" : [
{
"equals": {
"property": ["name"],
"value": "pump"
}
},
{
"prefix": {
"property": ["name"],
"value": "pump"
}
}
]
},
"sort": [
{
"property" : ["_score_"]
}
]
Request throttling
This endpoint is meant for data analytics/exploration usage and is not suitable for high load data retrieval usage. It is a subject of the new throttling schema (limited request rate and concurrency). Please check Assets resource description for more information.
Authorizations:
Request Body schema: application/json
object (Filter) Filter on assets with strict matching. | |||||||||||||||||||||||||||||
(BoolFilter (and (object) or or (object) or not (object))) or (LeafFilter (equals (object) or in (object) or range (object) or prefix (object) or exists (object) or containsAny (object) or containsAll (object) or search (object))) A filter DSL (Domain Specific Language) to define advanced filter queries. See more information about filtering DSL here. Supported properties:
Note: Filtering on the | |||||||||||||||||||||||||||||
| limit | integer <int32> [ 1 .. 1000 ] Default: 100 Limits the number of results to return. | ||||||||||||||||||||||||||||
Array of objects (AssetSortProperty) [ 1 .. 2 ] items Sort by array of selected properties. | |||||||||||||||||||||||||||||
| cursor | string | ||||||||||||||||||||||||||||
| aggregatedProperties | Array of strings (AggregatedProperty) Items Enum: "childCount" "path" "depth" Set of aggregated properties to include | ||||||||||||||||||||||||||||
| partition | string (PartitionLimited10) Splits the data set into The maximum number of allowed partitions ( Cognite rejects requests if you specify more than 10 partitions. When Cognite enforces this behavior, the requests result in a 400 Bad Request status. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "filter": {
- "name": "string",
- "parentIds": [
- 1
], - "parentExternalIds": [
- "my.known.id"
], - "rootIds": [
- {
- "id": 1
}
], - "assetSubtreeIds": [
- {
- "id": 1
}
], - "dataSetId": {
- "in": [
- {
- "id": 123
}, - {
- "externalId": "my.known.id"
}
], - "isNull": true
}, - "dataSetIds": [
- {
- "id": 1
}
], - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "createdTime": {
- "max": 0,
- "min": 0
}, - "lastUpdatedTime": {
- "max": 0,
- "min": 0
}, - "root": true,
- "externalIdPrefix": "my.known.prefix",
- "labels": {
- "containsAny": [
- {
- "externalId": "my.known.id"
}
]
}, - "geoLocation": {
- "relation": "INTERSECTS",
- "shape": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}
}
}, - "advancedFilter": {
- "or": [
- {
- "not": {
- "and": [
- {
- "equals": {
- "property": [
- "metadata",
- "asset_type"
], - "value": "gas pump"
}
}, - {
- "in": {
- "property": [
- "source"
], - "values": [
- "blueprint",
- "inventory"
]
}
}, - {
- "range": {
- "property": [
- "dataSetId"
], - "gte": 1,
- "lt": 10
}
}
]
}
}, - {
- "and": [
- {
- "containsAny": {
- "property": [
- "labels"
], - "values": [
- "pump",
- "cooler"
]
}
}, - {
- "equals": {
- "property": [
- "parentId"
], - "value": 95867294876
}
}
]
}, - {
- "search": {
- "property": [
- "description"
], - "value": "My favorite pump"
}
}
]
}, - "limit": 100,
- "sort": [
- {
- "property": [
- "createdTime"
], - "order": "desc"
}, - {
- "property": [
- "metadata",
- "customMetadataKey"
], - "nulls": "first"
}
], - "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo",
- "aggregatedProperties": [
- "childCount"
], - "partition": "1/3"
}Response samples
- 200
- 400
- 429
{- "items": [
- {
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "rootId": 1,
- "aggregates": {
- "childCount": 0,
- "depth": 0,
- "path": [
- {
- "id": 1
}
]
}, - "parentId": 1,
- "parentExternalId": "my.known.id",
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1
}
], - "nextCursor": "string"
}List assets
List all assets, or only the assets matching the specified query.
Request throttling
This endpoint is meant for data analytics/exploration usage and is not suitable for high load data retrieval usage. It is a subject of the new throttling schema (limited request rate and concurrency). Please check Assets resource description for more information.
Authorizations:
query Parameters
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 1000 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| includeMetadata | boolean Default: true Whether the metadata field should be returned or not. |
| name | string (AssetName) [ 1 .. 140 ] characters The name of the asset. |
| parentIds | string <jsonArray(int64)> (JsonArrayInt64) Example: parentIds=[363848954441724, 793045462540095, 1261042166839739] List only assets that have one of the parentIds as a parent. The parentId for root assets is null. |
| parentExternalIds | string <jsonArray(string)> (JsonArrayString) Example: parentExternalIds=[externalId_1, externalId_2, externalId_3] List only assets that have one of the parentExternalIds as a parent. The parentId for root assets is null. |
| rootIds | string <jsonArray(int64)> (JsonArrayInt64) Deprecated Example: rootIds=[363848954441724, 793045462540095, 1261042166839739] This parameter is deprecated. Use assetSubtreeIds instead. List only assets that have one of the rootIds as a root asset. A root asset is its own root asset. |
| assetSubtreeIds | string <jsonArray(int64)> (JsonArrayInt64) Example: assetSubtreeIds=[363848954441724, 793045462540095, 1261042166839739] List only assets that are in a subtree rooted at any of these assetIds (including the roots given). If the total size of the given subtrees exceeds 100,000 assets, an error will be returned. |
| assetSubtreeExternalIds | string <jsonArray(string)> (JsonArrayString) Example: assetSubtreeExternalIds=[externalId_1, externalId_2, externalId_3] List only assets that are in a subtree rooted at any of these assetExternalIds. If the total size of the given subtrees exceeds 100,000 assets, an error will be returned. |
| source | string <= 128 characters The source of the asset, for example which database it's from. |
| root | boolean Default: false Whether the filtered assets are root assets, or not. Set to True to only list root assets. |
| minCreatedTime | integer <int64> (EpochTimestamp) >= 0 Example: minCreatedTime=1730204346000 The number of milliseconds since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| maxCreatedTime | integer <int64> (EpochTimestamp) >= 0 Example: maxCreatedTime=1730204346000 The number of milliseconds since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| minLastUpdatedTime | integer <int64> (EpochTimestamp) >= 0 Example: minLastUpdatedTime=1730204346000 The number of milliseconds since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| maxLastUpdatedTime | integer <int64> (EpochTimestamp) >= 0 Example: maxLastUpdatedTime=1730204346000 The number of milliseconds since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| externalIdPrefix | string (CogniteExternalIdPrefix) <= 255 characters Example: externalIdPrefix=my.known.prefix Filter by this (case-sensitive) prefix for the external ID. |
| partition | string Example: partition=1/3 Splits the data set into The maximum number of allowed partitions ( Cognite rejects requests if you specify more than 10 partitions. When Cognite enforces this behavior, the requests result in a 400 Bad Request status. |
Responses
Request samples
- JavaScript SDK
- Python SDK
const assets = await client.assets.list({ filter: { name: '21PT1019' } });
Response samples
- 200
- 400
- 429
{- "items": [
- {
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "rootId": 1,
- "aggregates": {
- "childCount": 0,
- "depth": 0,
- "path": [
- {
- "id": 1
}
]
}, - "parentId": 1,
- "parentExternalId": "my.known.id",
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1
}
], - "nextCursor": "string"
}Retrieve an asset by its ID
Retrieve an asset by its internal ID. If you want to retrieve assets by externalIds, use Retrieve assets instead.
Request throttling
This endpoint is a subject of the new throttling schema (limited request rate and concurrency). Please check Assets resource description for more information.
Authorizations:
path Parameters
| id required | integer <int64> (CogniteInternalId) [ 1 .. 9007199254740991 ] A server-generated ID for the object. |
Responses
Request samples
- JavaScript SDK
- Python SDK
const assets = await client.assets.retrieve([{id: 123}, {externalId: 'abc'}]);
Response samples
- 200
- 400
- 429
{- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "rootId": 1,
- "aggregates": {
- "childCount": 0,
- "depth": 0,
- "path": [
- {
- "id": 1
}
]
}, - "parentId": 1,
- "parentExternalId": "my.known.id",
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1
}Retrieve assets
Retrieve assets by IDs or external IDs. If you specify to get aggregates, then be aware that the aggregates are eventually consistent.
Request throttling
This endpoint is a subject of the new throttling schema (limited request rate and concurrency). Please check Assets resource description for more information.
Authorizations:
Request Body schema: application/jsonrequired
All provided IDs and external IDs must be unique.
required | Array of AssetInternalId (object) or AssetExternalId (object) (AssetIdEither) [ 1 .. 1000 ] items |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
| aggregatedProperties | Array of strings (AggregatedProperty) Items Enum: "childCount" "path" "depth" Set of aggregated properties to include |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1
}
], - "ignoreUnknownIds": false,
- "aggregatedProperties": [
- "childCount"
]
}Response samples
- 200
- 400
- 429
{- "items": [
- {
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "rootId": 1,
- "aggregates": {
- "childCount": 0,
- "depth": 0,
- "path": [
- {
- "id": 1
}
]
}, - "parentId": 1,
- "parentExternalId": "my.known.id",
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1
}
]
}Search assets
Fulltext search for assets based on result relevance. Primarily meant for human-centric use-cases, not for programs, since matching and ordering may change over time. Additional filters can also be specified. This operation doesn't support pagination.
Request throttling
This endpoint is meant for data analytics/exploration usage and is not suitable for high load data retrieval usage. It is a subject of the new throttling schema (limited request rate and concurrency). Please check Assets resource description for more information.
Authorizations:
Request Body schema: application/jsonrequired
Search query
object (Filter) Filter on assets with strict matching. | |
| limit | integer <int32> [ 1 .. 1000 ] Default: 100 Limits the number of results to return. |
object (Search) Fulltext search for assets. Primarily meant for for human-centric use-cases, not for programs. The query parameter uses a different search algorithm than the deprecated name and description parameters, and will generally give much better results. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
{- "filter": {
- "parentIds": [
- 1293812938,
- 293823982938
]
}, - "search": {
- "name": "flow",
- "description": "upstream"
}
}Response samples
- 200
- 400
- 429
{- "items": [
- {
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "rootId": 1,
- "aggregates": {
- "childCount": 0,
- "depth": 0,
- "path": [
- {
- "id": 1
}
]
}, - "parentId": 1,
- "parentExternalId": "my.known.id",
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1
}
]
}Sync changes of assets (alpha feature)
Sync changes of assets. Use nextCursor to paginate through the results.
This endpoint can continuously sync asset changes out of CDF using an internal change log.
The change log follows the internal id of the asset, not the external id.
It will include delete operations on the assets.
Once asset is deleted, it won't appear again in the change log with the same internal id,
even if it's recreated with the same external id.
Once all assets have been synced out, the API will return an empty list of items and a valid nextCursor.
The client should continue to poll the API with the nextCursor to get future updates and items.
Client should preserve the latest returned nextCursor to avoid starting the sync from scratch.
The API guarantees that the client will be able to sync to the latest version of
all assets, however, doesn't guarantee that the client will see all changes in between.
Resource data for deleted assets won't be included or if includeAssetData parameter is false.
If you only want to sync out future changes of assets, you can use the onlyFuture parameter.
The header cdf-version needs to be set to alpha to use this feature.
Authorizations:
header Parameters
| cdf-version | string Example: alpha cdf version header. Use this to specify the requested CDF release. |
Request Body schema: application/json
| onlyFuture | boolean Default: false Initialise the cursor to only sync future updates. Only applicable when cursor isn't set. |
| includeAssetData | boolean Default: true Whether the asset resource data should be returned or not. |
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to return. |
| cursor | string |
Responses
Request samples
- Payload
{- "onlyFuture": false,
- "includeAssetData": true,
- "limit": 100,
- "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo"
}Response samples
- 200
- 400
- 429
{- "items": [
- {
- "id": 1,
- "transactionId": 26500,
- "version": 3,
- "isDeleted": false,
- "asset": {
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "rootId": 1,
- "aggregates": {
- "childCount": 0,
- "depth": 0,
- "path": [
- {
- "id": 1
}
]
}, - "parentId": 1,
- "parentExternalId": "my.known.id",
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1
}
}
], - "nextCursor": "string"
}Update assets
Update the attributes of assets.
Request throttling
This endpoint is a subject of the new throttling schema (limited request rate and concurrency). Please check Assets resource description for more information.
Authorizations:
Request Body schema: application/jsonrequired
All provided IDs and external IDs must be unique. Fields that aren't included in the request aren't changed.
required | Array of AssetChangeById (object) or AssetChangeByExternalId (object) (AssetChange) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "update": {
- "externalId": {
- "set": "my.known.id"
}, - "name": {
- "set": "string"
}, - "description": {
- "set": "string"
}, - "dataSetId": {
- "set": 0
}, - "metadata": {
- "set": {
- "key1": "value1",
- "key2": "value2"
}
}, - "source": {
- "set": "string"
}, - "parentId": {
- "set": 1
}, - "parentExternalId": {
- "set": "my.known.id"
}, - "labels": {
- "add": [
- {
- "externalId": "my.known.id"
}
], - "remove": [
- {
- "externalId": "my.known.id"
}
]
}, - "geoLocation": {
- "set": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}
}
}, - "id": 1
}
]
}Response samples
- 200
- 400
- 429
{- "items": [
- {
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "rootId": 1,
- "aggregates": {
- "childCount": 0,
- "depth": 0,
- "path": [
- {
- "id": 1
}
]
}, - "parentId": 1,
- "parentExternalId": "my.known.id",
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1
}
]
}A time series consists of a sequence of data points connected to a single asset. For example, a water pump asset can have a temperature time series that records a data point in units of °C every second.
A single asset can have several time series. The water pump could have additional time series measuring pressure within the pump, rpm, flow volume, power consumption, and more.Time series store data points as either numbers or strings. This is controlled by the is_string flag on the time series object. Numerical data points can be aggregated before they are returned from a query (e.g., to find the average temperature for a day). String data points, on the other hand, can't be aggregated by CDF but can store arbitrary information like states (e.g., “open”/”closed”) or more complex information (JSON).
Cognite stores discrete data points, but the underlying
process measured by the data points can vary continuously. When interpolating
between data points, we can either assume that each value stays the same until
the next measurement or linearly changes between the two measurements.
The isStep flag controls this on the time series object. For example,
if we estimate the average over a time containing two data points, the average
will either be close to the first (isStep) or close to the mean of the two (not
isStep).
A data point stores a single piece of information, a number or a string, associated with a specific time. Data points are identified by their timestamps, measured in milliseconds since the unix epoch -- 00:00:00.000, January 1st, 1970. The time series service accepts timestamps in the range from 00:00:00.000, January 1st, 1900 through 23:59:59.999, December 31st, 2099 (in other words, every millisecond in the two centuries from 1900 to but not including 2100). Negative timestamps are used to define dates before 1970. Milliseconds is the finest time resolution supported by CDF, i.e., fractional milliseconds are not supported. Leap seconds are not counted.
Numerical data points can be aggregated before they are retrieved from CDF. This allows for faster queries by reducing the amount of data transferred. You can aggregate data points by specifying one or more aggregates (e.g., average, minimum, maximum) as well as the time granularity over which the aggregates should be applied (e.g., “1h” for one hour).
Aggregates are aligned to the start time modulo the granularity unit. For example, if you ask for daily average temperatures since Monday afternoon last week, the first aggregated data point will contain averages for Monday, the second for Tuesday, etc. Determining aggregate alignment without considering data point timestamps allows CDF to pre-calculate aggregates (e.g., to quickly return daily average temperatures for a year). Consequently, aggregating over 60 minutes can return a different result than aggregating over 1 hour because the two queries will be aligned differently. Asset references obtained from a time series - through its asset ID - may be invalid simply by the non-transactional nature of HTTP. They are maintained in an eventually consistent manner.
Aggregate time series
The aggregation API allows you to compute aggregated results from a set of time series, such as
getting the number of time series in a project or checking what assets the different time series
in your project are associated with (along with the number of time series for each asset).
By specifying filter and/or advancedFilter, the aggregation will take place only over those
time series that match the filters. filter and advancedFilter behave the same way as in the
list endpoint.
The default behavior, when the aggregate field is not specified the request body, is to return the
number of time series that match the filters (if any), which is the same behavior as when the
aggregate field is set to count.
The following requests will both return the total number of
time series whose name begins with pump:
{
"advancedFilter": {"prefix": {"property": ["name"], "value": "pump"}}
}
and
{
"aggregate": "count",
"advancedFilter": {"prefix": {"property": ["name"], "value": "pump"}}
}
The response might be:
{"items": [{"count": 42}]}
Setting aggregate to uniqueValues and specifying a property in properties (this field is an array, but currently only supports one property) will
return all unique values (up to a maximum of 1000) that are taken on by that property
across all the time series that match the filters, as well as the number of time series that
have each of those property values.
This example request finds all the unique asset ids that are
referenced by the time series in your project whose name begins with pump:
{
"aggregate": "uniqueValues",
"properties": [{"property": ["assetId"]}],
"advancedFilter": {"prefix": {"property": ["name"], "value": "pump"}}
}
The response might be the following, saying that 23 time series are associated with asset 18 and 107 time series are associated with asset 76:
{
"items": [
{"values": ["18"], "count": 23},
{"values": ["76"], "count": 107}
]
}
Setting aggregate to cardinalityValues will instead return the approximate number of
distinct values that are taken on by the given property among the matching time series.
Example request:
{
"aggregate": "cardinalityValues",
"properties": [{"property": ["assetId"]}],
"advancedFilter": {"prefix": {"property": ["name"], "value": "pump"}}
}
The result is likely exact when the set of unique values is small. In this example, there are likely two distinct asset ids among the matching time series:
{"items": [{"count": 2}]}
Setting aggregate to uniqueProperties will return the set of unique properties whose property
path begins with path (which can currently only be ["metadata"]) that are contained in the time series that match the filters.
Example request:
{
"aggregate": "uniqueProperties",
"path": ["metadata"],
"advancedFilter": {"prefix": {"property": ["name"], "value": "pump"}}
}
The result contains all the unique metadata keys in the time series whose name begins with
pump, and the number of time series that contains each metadata key:
{
"items": [
{"values": [{"property": ["metadata", "tag"]}], "count": 43},
{"values": [{"property": ["metadata", "installationDate"]}], "count": 97}
]
}
Setting aggregate to cardinalityProperties will instead return the approximate number of
different property keys whose path begins with path (which can currently only be ["metadata"], meaning that this can only be used to count the approximate number of distinct metadata keys among the matching time series).
Example request:
{
"aggregate": "cardinalityProperties",
"path": ["metadata"],
"advancedFilter": {"prefix": {"property": ["name"], "value": "pump"}}
}
The result is likely exact when the set of unique values is small. In this example, there are likely two distinct metadata keys among the matching time series:
{"items": [{"count": 2}]}
The aggregateFilter field may be specified if aggregate is set to cardinalityProperties or uniqueProperties. The structure of this field is similar to that of advancedFilter, except that the set of leaf filters is smaller (in, prefix, and range), and that none of the leaf filters specify a property. Unlike advancedFilter, which is applied before the aggregation (in order to restrict the set of time series that the aggregation operation should be applied to), aggregateFilter is applied after the initial aggregation has been performed, in order to restrict the set of results.
Click here for more details about aggregateFilter.
When aggregate is set to uniqueProperties, the result set contains a number of property paths, each with an associated count that shows how many time series contained that property (among those time series that matched the filter and advancedFilter, if they were specified) . If aggregateFilter is specified, it will restrict the property paths included in the output. Let us add an aggregateFilter to the uniqueProperties example from above:
{
"aggregate": "uniqueProperties",
"path": ["metadata"],
"advancedFilter": {"prefix": {"property": ["name"], "value": "pump"}},
"aggregateFilter": {"prefix": {"value": "t"}}
}
Now, the result only contains those metadata properties whose key begins with t (but it will be the same set of metadata properties that begin with t as in the original query without aggregateFilter, and the counts will be the same):
{
"items": [
{"values": [{"property": ["metadata", "tag"]}], "count": 43}
]
}
Similarly, adding aggregateFilter to cardinalityProperties will return the approximate number of properties whose property key matches aggregateFilter from those time series matching the filter and advancedFilter (or from all time series if neither filter nor aggregateFilter are specified):
{
"aggregate": "cardinalityProperties",
"path": ["metadata"],
"advancedFilter": {"prefix": {"property": ["name"], "value": "pump"}},
"aggregateFilter": {"prefix": {"value": "t"}}
}
As we saw above, only one property matches:
{"items": [{"count": 1}]}
Note that aggregateFilter is also accepted when aggregate is set to cardinalityValues or cardinalityProperties. For those aggregations, the effect of any aggregateFilter could also be achieved via a similar advancedFilter. However, aggregateFilter is not accepted when aggregate is omitted or set to count.
Rate and concurrency limits
Rate and concurrency limits apply this endpoint. If a request exceeds one of the limits,
it will be throttled with a 429: Too Many Requests response. More on limit types
and how to avoid being throttled is described
here.
| Limit | Per project | Per user (identity) |
|---|---|---|
| Rate | 15 requests per second | 10 requests per second |
| Concurrency | 6 concurrent requests | 4 concurrent requests |
Authorizations:
Request Body schema: application/json
Aggregates the time series that match the given criteria.
(Boolean filter (and (object) or or (object) or not (object))) or (Leaf filter (equals (object) or in (object) or range (object) or prefix (object) or exists (object) or containsAny (object) or containsAll (object) or search (object))) (TimeSeriesFilterLanguage) | |
object (Filter) | |
(Boolean filter (and (object) or or (object) or not (object))) or (Leaf filter (in (object) or range (object) or prefix (object))) (TimeSeriesAggregateFilter) | |
| aggregate | string Value: "count" The |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "advancedFilter": {
- "or": [
- {
- "not": {
- "and": [
- {
- "equals": {
- "property": [
- "metadata",
- "manufacturer"
], - "value": "acme"
}
}, - {
- "in": {
- "property": [
- "name"
], - "values": [
- "pump-1-temperature",
- "motor-9-temperature"
]
}
}, - {
- "range": {
- "property": [
- "dataSetId"
], - "gte": 1,
- "lt": 10
}
}
]
}
}, - {
- "and": [
- {
- "equals": {
- "property": [
- "assetId"
], - "value": 1234
}
}, - {
- "equals": {
- "property": [
- "description"
], - "value": "Temperature in Celsius"
}
}
]
}
]
}, - "filter": {
- "name": "string",
- "unit": "string",
- "unitExternalId": "string",
- "unitQuantity": "string",
- "isString": true,
- "isStep": true,
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 363848954441724,
- 793045462540095,
- 1261042166839739
], - "assetExternalIds": [
- "my.known.id"
], - "rootAssetIds": [
- 343099548723932,
- 88483999203217
], - "assetSubtreeIds": [
- {
- "id": 1
}
], - "dataSetIds": [
- {
- "id": 1
}
], - "externalIdPrefix": "my.known.prefix",
- "createdTime": {
- "max": 0,
- "min": 0
}, - "lastUpdatedTime": {
- "max": 0,
- "min": 0
}
}, - "aggregateFilter": {
- "and": [
- { }
]
}, - "aggregate": "count"
}Response samples
- 200
- 400
{- "items": [
- {
- "count": 0
}
]
}Create time series
Creates one or more time series.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (PostTimeSeriesMetadataDTO) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "externalId": "string",
- "name": "string",
- "legacyName": "string",
- "isString": false,
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "unit": "string",
- "unitExternalId": "string",
- "assetId": 1,
- "isStep": false,
- "description": "string",
- "securityCategories": [
- 0
], - "dataSetId": 1
}
]
}Response samples
- 201
- 400
- 409
- 422
{- "items": [
- {
- "id": 1,
- "externalId": "string",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "name": "string",
- "isString": true,
- "type": "string",
- "stateSet": {
- "space": "string",
- "externalId": "string"
}, - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "unit": "string",
- "unitExternalId": "string",
- "assetId": 1,
- "isStep": true,
- "description": "string",
- "securityCategories": [
- 0
], - "dataSetId": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Delete data points
Delete data points from time series.
Authorizations:
Request Body schema: application/jsonrequired
The list of delete requests to perform.
required | Array of QueryWithInternalId (object) or QueryWithExternalId (object) or QueryWithInstanceId (object) (DatapointsDeleteRequest) [ 1 .. 10000 ] items List of delete filters. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1,
- "inclusiveBegin": 1638795554528,
- "exclusiveEnd": 1638795554528
}
]
}Response samples
- 200
- 400
{ }Delete time series
Deletes the time series with the specified IDs and their data points.
Authorizations:
Request Body schema: application/jsonrequired
Specify a list of the time series to delete.
required | Array of QueryWithInternalId (object) or QueryWithExternalId (object) [ 1 .. 1000 ] items unique List of ID objects. |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1
}
], - "ignoreUnknownIds": false
}Response samples
- 200
- 400
- 422
{ }Filter time series
Retrieves a list of time series that match the given criteria.
Advanced filtering
The advancedFilter
field lets you create complex filtering expressions that combine simple operations,
such as equals, prefix, and exists, by using the Boolean operators and, or, and not.
Filtering applies to basic fields as well as metadata. See the advancedFilter syntax in the request example.
Supported leaf filters
| Leaf filter | Supported fields | Description and example |
|---|---|---|
containsAll |
Array type fields | Only includes results which contain all of the specified values. {"containsAll": {"property": ["property"], "values": [1, 2, 3]}} |
containsAny |
Array type fields | Only includes results which contain at least one of the specified values. {"containsAny": {"property": ["property"], "values": [1, 2, 3]}} |
equals |
Non-array type fields | Only includes results that are equal to the specified value. {"equals": {"property": ["property"], "value": "example"}} |
exists |
All fields | Only includes results where the specified property exists (has a value). {"exists": {"property": ["property"]}} |
in |
Non-array type fields | Only includes results that are equal to one of the specified values. {"in": {"property": ["property"], "values": [1, 2, 3]}} |
prefix |
String type fields | Only includes results which start with the specified text. {"prefix": {"property": ["property"], "value": "example"}} |
range |
Non-array type fields | Only includes results that fall within the specified range. {"range": {"property": ["property"], "gt": 1, "lte": 5}} Supported operators: gt, lt, gte, lte |
search |
["name"] and ["description"] |
Introduced to provide functional parity with the /timeseries/search endpoint. {"search": {"property": ["property"], "value": "example"}} |
Supported properties
| Property | Type |
|---|---|
["description"] |
string |
["externalId"] |
string |
["metadata", "<someCustomKey>"] |
string |
["name"] |
string |
["unit"] |
string |
["unitExternalId"] |
string |
["unitQuantity"] |
string |
["instanceId", "space"] |
string |
["instanceId", "externalId"] |
string |
["assetId"] |
number |
["assetRootId"] |
number |
["createdTime"] |
number |
["dataSetId"] |
number |
["id"] |
number |
["lastUpdatedTime"] |
number |
["isStep"] |
Boolean |
["isString"] |
Boolean |
["securityCategories"] |
array of numbers |
Limits
- Filter query max depth: 10.
- Filter query max number of clauses: 100.
andandorclauses must have at least one element (and at most 99, since each element counts towards the total clause limit, and so does theand/orclause itself).- The
propertyarray of each leaf filter has the following limitations:- Number of elements in the array is 1 or 2.
- Elements must not be null or blank.
- Each element max length is 256 characters.
- The
propertyarray must match one of the existing properties (static top-level property or dynamic metadata property).
containsAll,containsAny, andinfiltervaluesarray size must be in the range [1, 100].containsAll,containsAny, andinfiltervaluesarray must contain elements of number or string type (matching the type of the given property).rangefilter must have at lest one ofgt,gte,lt,lteattributes. Butgtis mutually exclusive togte, whileltis mutually exclusive tolte.gt,gte,lt,ltein therangefilter must be of number or string type (matching the type of the given property).searchfiltervaluemust not be blank, and the length must be in the range [1, 128], and there may be at most twosearchfilters in the entire filter query.- The maximum length of the
valueof a leaf filter that is applied to a string property is 256.
Sorting
By default, time series are sorted by their creation time in ascending order.
Sorting by another property or by several other properties can be explicitly requested via the
sort field, which must contain a list
of one or more sort specifications. Each sort specification indicates the property to sort on
and, optionally, the order in which to sort (defaults to asc). If multiple sort specifications are
supplied, the results are sorted on the first property, and those with the same value for the first
property are sorted on the second property, and so on.
Partitioning is done independently of sorting; there is no guarantee of sort order between elements from different partitions.
Null values
In case the nulls field has the auto value, or the field isn't specified, null (missing) values
are considered bigger than any other values. They are placed last when sorting in the asc
order and first in the desc order. Otherwise, missing values are placed according to
the nulls field (last or first), and their placement won't depend on the order
field. Note that the number zero, empty strings, and empty lists are all considered
not null.
Example
{
"sort": [
{
"property" : ["createdTime"],
"order": "desc",
"nulls": "last"
},
{
"property" : ["metadata", "<someCustomKey>"]
}
]
}
Properties
You can sort on the following properties:
| Property |
|---|
["assetId"] |
["createdTime"] |
["dataSetId"] |
["description"] |
["externalId"] |
["lastUpdatedTime"] |
["metadata", "<someCustomKey>"] |
["name"] |
["instanceId", "space"] |
["instanceId", "externalId"] |
Limits
The sort array must contain 1 to 2 elements.
Authorizations:
Request Body schema: application/json
object (Filter) | |
(Boolean filter (and (object) or or (object) or not (object))) or (Leaf filter (equals (object) or in (object) or range (object) or prefix (object) or exists (object) or containsAny (object) or containsAll (object) or search (object))) (TimeSeriesFilterLanguage) | |
| limit | integer <int32> [ 1 .. 1000 ] Default: 100 Return up to this many results. |
| cursor | string |
| partition | string (Partition) Splits the data set into To prevent unexpected problems and maximize read throughput, you should at most use 10 (N <= 10) partitions. When using more than 10 partitions, CDF may reduce the number of partitions silently.
For example, CDF may reduce the number of partitions to In future releases of the resource APIs, Cognite may reject requests if you specify more than 10 partitions. When Cognite enforces this behavior, the requests will result in a 400 Bad Request status. |
Array of objects (TimeSeriesSortItem) [ 1 .. 2 ] items Sort by array of selected properties. |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "filter": {
- "name": "string",
- "unit": "string",
- "unitExternalId": "string",
- "unitQuantity": "string",
- "isString": true,
- "isStep": true,
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 363848954441724,
- 793045462540095,
- 1261042166839739
], - "assetExternalIds": [
- "my.known.id"
], - "rootAssetIds": [
- 343099548723932,
- 88483999203217
], - "assetSubtreeIds": [
- {
- "id": 1
}
], - "dataSetIds": [
- {
- "id": 1
}
], - "externalIdPrefix": "my.known.prefix",
- "createdTime": {
- "max": 0,
- "min": 0
}, - "lastUpdatedTime": {
- "max": 0,
- "min": 0
}
}, - "advancedFilter": {
- "or": [
- {
- "not": {
- "and": [
- {
- "equals": {
- "property": [
- "metadata",
- "manufacturer"
], - "value": "acme"
}
}, - {
- "in": {
- "property": [
- "name"
], - "values": [
- "pump-1-temperature",
- "motor-9-temperature"
]
}
}, - {
- "range": {
- "property": [
- "dataSetId"
], - "gte": 1,
- "lt": 10
}
}
]
}
}, - {
- "and": [
- {
- "equals": {
- "property": [
- "assetId"
], - "value": 1234
}
}, - {
- "equals": {
- "property": [
- "description"
], - "value": "Temperature in Celsius"
}
}
]
}
]
}, - "limit": 100,
- "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo",
- "partition": "1/10",
- "sort": [
- {
- "property": [
- "string"
], - "order": "asc",
- "nulls": "first"
}
]
}Response samples
- 200
{- "items": [
- {
- "id": 1,
- "externalId": "string",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "name": "string",
- "isString": true,
- "type": "string",
- "stateSet": {
- "space": "string",
- "externalId": "string"
}, - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "unit": "string",
- "unitExternalId": "string",
- "assetId": 1,
- "isStep": true,
- "description": "string",
- "securityCategories": [
- 0
], - "dataSetId": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
], - "nextCursor": "string"
}Insert data points
Insert data points into a time series. You can do this for multiple time series. If you insert a data point with a timestamp that already exists, it will be overwritten with the new value.
Authorizations:
Request Body schema: required
The datapoints to insert.
required | Array of DatapointsWithInternalId (object) or DatapointsWithExternalId (object) or DatapointsWithInstanceId (object) (DatapointsPostDatapoint) [ 1 .. 10000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1,
- "datapoints": [
- {
- "timestamp": -2208988800000,
- "value": 0,
- "status": {
- "code": 0,
- "symbol": "string"
}
}
]
}
]
}Response samples
- 200
- 400
- 422
{ }List time series
List time series. Use nextCursor to paginate through the results.
Authorizations:
query Parameters
| limit | integer <int32> [ 1 .. 1000 ] Default: 100 Limits the number of results to return. CDF returns a maximum of 1000 results even if you specify a higher limit. |
| includeMetadata | boolean Default: true Whether the metadata field should be returned or not. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| partition | string Example: partition=1/10 Splits the data set into To prevent unexpected problems and maximize read throughput, you should at most use 10 (N <= 10) partitions. When using more than 10 partitions, CDF may reduce the number of partitions silently.
For example, CDF may reduce the number of partitions to In future releases of the resource APIs, Cognite may reject requests if you specify more than 10 partitions. When Cognite enforces this behavior, the requests will result in a 400 Bad Request status. |
| assetIds | string <jsonArray(int64)> (JsonArrayInt64) Example: assetIds=[363848954441724, 793045462540095, 1261042166839739] Gets the time series related to the assets. The format is a list of IDs serialized as a JSON array(int64). Takes [ 1 .. 100 ] unique items. |
| rootAssetIds | string <jsonArray(int64)> (JsonArrayInt64) Example: rootAssetIds=[363848954441724, 793045462540095, 1261042166839739] Only includes time series that have a related asset in a tree rooted at any of these root |
| externalIdPrefix | string (CogniteExternalIdPrefix) <= 255 characters Example: externalIdPrefix=my.known.prefix Filter by this (case-sensitive) prefix for the external ID. |
Responses
Request samples
- JavaScript SDK
- Python SDK
const timeseries = await client.timeseries.list({ filter: { assetIds: [1, 2] }});
Response samples
- 200
{- "items": [
- {
- "id": 1,
- "externalId": "string",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "name": "string",
- "isString": true,
- "type": "string",
- "stateSet": {
- "space": "string",
- "externalId": "string"
}, - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "unit": "string",
- "unitExternalId": "string",
- "assetId": 1,
- "isStep": true,
- "description": "string",
- "securityCategories": [
- 0
], - "dataSetId": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
], - "nextCursor": "string"
}Retrieve data points
Retrieves a list of data points from multiple time series in a project. This operation supports aggregation and pagination. Learn more about aggregation.
Note: when start isn't specified in the top level and for an individual item, it will default to epoch 0, which is 1 January, 1970, thus
excluding potential existent data points before 1970. start needs to be specified as a negative number to get data points before 1970.
Authorizations:
Request Body schema: application/jsonrequired
Specify parameters to query for multiple data points. If you omit fields in individual data point query items, the top-level field values are used. For example, you can specify a default limit for all items by setting the top-level limit field. If you request aggregates, only the aggregates are returned. If you don't request any aggregates, all data points are returned.
required | Array of QueryWithInternalId (object) or QueryWithExternalId (object) or QueryWithInstanceId (object) (DatapointsQuery) [ 1 .. 100 ] items |
integer or string (TimestampOrStringStart) | |
integer or string (TimestampOrStringEnd) | |
| limit | integer <int32> Default: 100 Returns up to this number of data points. The maximum is 100000 non-aggregated data points and 10000 aggregated data points in total across all queries in a single request. |
| aggregates | Array of strings (Aggregate) non-empty unique Items Enum: "average" "max" "maxDatapoint" "min" "minDatapoint" "count" "sum" "interpolation" "stepInterpolation" "totalVariation" "continuousVariance" "discreteVariance" "countGood" "countUncertain" "countBad" "durationGood" "durationUncertain" "durationBad" "stateCount" "stateDuration" "stateTransitions" Specify the aggregates to return. Omit to return data points without aggregation. Some aggregates are only available for time series of a specific type. |
| granularity | string The time granularity size and unit to aggregate over. Valid entries are 'month, day, hour, minute, second', or short forms 'mo, d, h, m, s', or a multiple of these indicated by a number as a prefix. For 'second' and 'minute', the multiple must be an integer between 1 and 120 inclusive; for 'hour', 'day', and 'month', the multiple must be an integer between 1 and 100000 inclusive. For example, a granularity '5m' means that aggregates are calculated over 5 minutes. This field is required if aggregates are specified. |
| includeOutsidePoints | boolean Default: false Defines whether to include the last data point before the requested time period and the first one after. This option can be useful for interpolating data. It's not available for aggregates or cursors. Note: If there are more than When doing manual paging (sequentially requesting smaller intervals instead of
requesting a larger interval and using cursors to get all the data points) with this
field set to true, the |
| timeZone | string Default: "UTC" For aggregates of granularity 'hour' and longer, which time zone should we align to. Align to the start of the hour, start of the day or start of the month. For time zones of type Region/Location, the aggregate duration can vary, typically due to daylight saving time. For time zones of type UTC+/-HH:MM, use increments of 15 minutes. Note: Time zones with minute offsets (e.g. UTC+05:30 or Asia/Kolkata) may take longer to execute. Historical time zones, with offsets not multiples of 15 minutes, are not supported. |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1,
- "start": 0,
- "end": 0,
- "limit": 0,
- "aggregates": [
- "average"
], - "granularity": "1h",
- "targetUnit": "temperature:deg_f",
- "targetUnitSystem": "imperial",
- "includeOutsidePoints": false,
- "includeStatus": false,
- "ignoreBadDataPoints": true,
- "treatUncertainAsBad": true,
- "cursor": "string",
- "timeZone": "Europe/Oslo or UTC+05:30"
}
], - "start": 0,
- "end": 0,
- "limit": 100,
- "aggregates": [
- "average"
], - "granularity": "1h",
- "includeOutsidePoints": false,
- "timeZone": "Europe/Oslo or UTC+05:30",
- "ignoreUnknownIds": false
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 1,
- "externalId": "string",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "isString": false,
- "type": "string",
- "isStep": true,
- "unit": "string",
- "unitExternalId": "string",
- "nextCursor": "string",
- "datapoints": [
- {
- "timestamp": 1638795554528,
- "count": 0,
- "countGood": 0,
- "countUncertain": 0,
- "countBad": 0,
- "durationGood": 0,
- "durationUncertain": 0,
- "durationBad": 0,
- "average": 0.1,
- "max": 0.1,
- "maxDatapoint": {
- "timestamp": 1638795554528,
- "value": 0.1,
- "status": {
- "code": 0,
- "symbol": "string"
}
}, - "min": 0.1,
- "minDatapoint": {
- "timestamp": 1638795554528,
- "value": 0.1,
- "status": {
- "code": 0,
- "symbol": "string"
}
}, - "sum": 0.1,
- "interpolation": 0.1,
- "stepInterpolation": 0.1,
- "continuousVariance": 0.1,
- "discreteVariance": 0.1,
- "totalVariation": 0.1
}
]
}
]
}Retrieve latest data point
Retrieves the latest data point in one or more time series. Note that the latest data point in a time series is the one with the highest timestamp, which is not necessarily the one that was ingested most recently.
Authorizations:
Request Body schema: application/jsonrequired
The list of the queries to perform.
required | Array of QueryWithInternalId (object) or QueryWithExternalId (object) or QueryWithInstanceId (object) (LatestDataBeforeRequest) [ 1 .. 100 ] items List of latest queries |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1,
- "before": "now",
- "targetUnit": "temperature:deg_f",
- "targetUnitSystem": "imperial",
- "includeStatus": false,
- "ignoreBadDataPoints": true,
- "treatUncertainAsBad": true
}
], - "ignoreUnknownIds": false
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 1,
- "externalId": "string",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "isString": true,
- "type": "string",
- "isStep": true,
- "unit": "string",
- "unitExternalId": "string",
- "nextCursor": "string",
- "datapoints": [
- {
- "timestamp": 1638795554528,
- "value": 0.1,
- "status": {
- "code": 0,
- "symbol": "string"
}
}
]
}
]
}Retrieve time series
Retrieves one or more time series by ID or external ID. The response returns the time series in the same order as in the request.
Authorizations:
Request Body schema: application/jsonrequired
List of the IDs of the time series to retrieve.
required | Array of QueryWithInternalId (object) or QueryWithExternalId (object) or QueryWithInstanceId (object) [ 1 .. 1000 ] items unique List of ID objects. |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1
}
], - "ignoreUnknownIds": false
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "id": 1,
- "externalId": "string",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "name": "string",
- "isString": true,
- "type": "string",
- "stateSet": {
- "space": "string",
- "externalId": "string"
}, - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "unit": "string",
- "unitExternalId": "string",
- "assetId": 1,
- "isStep": true,
- "description": "string",
- "securityCategories": [
- 0
], - "dataSetId": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Search time series
Fulltext search for time series based on result relevance. Primarily meant for human-centric use cases, not for programs, since matching and order may change over time. Additional filters can also be specified. This operation does not support pagination.
Authorizations:
Request Body schema: application/json
object (Filter) | |
object (Search) | |
| limit | integer <int32> [ 1 .. 1000 ] Default: 100 Return up to this many results. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
{- "filter": {
- "name": "string",
- "unit": "string",
- "unitExternalId": "string",
- "unitQuantity": "string",
- "isString": true,
- "isStep": true,
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 363848954441724,
- 793045462540095,
- 1261042166839739
], - "assetExternalIds": [
- "my.known.id"
], - "rootAssetIds": [
- 343099548723932,
- 88483999203217
], - "assetSubtreeIds": [
- {
- "id": 1
}
], - "dataSetIds": [
- {
- "id": 1
}
], - "externalIdPrefix": "my.known.prefix",
- "createdTime": {
- "max": 0,
- "min": 0
}, - "lastUpdatedTime": {
- "max": 0,
- "min": 0
}
}, - "search": {
- "name": "string",
- "description": "string",
- "query": "some other"
}, - "limit": 100
}Response samples
- 200
{- "items": [
- {
- "id": 1,
- "externalId": "string",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "name": "string",
- "isString": true,
- "type": "string",
- "stateSet": {
- "space": "string",
- "externalId": "string"
}, - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "unit": "string",
- "unitExternalId": "string",
- "assetId": 1,
- "isStep": true,
- "description": "string",
- "securityCategories": [
- 0
], - "dataSetId": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Undo upgrade to data modeling
Unlink the time series, setting pendingInstanceId and instanceId to null. This will stop the synchronization from data modeling. Unlinking is only allowed for time series created in the time series API.
If any of the time series were migrated (instanceId != null), then new time series will be created for these instance ids. This is to uphold the invariant that all time series in data modeling should exist in the time series API.
Note: This endpoint will not delete any time series in data modeling. The data modeling instances must be deleted using the data modeling API.
Authorizations:
Request Body schema: application/json
required | Array of QueryWithInternalId (object) or QueryWithExternalId (object) [ 1 .. 1000 ] items [ items unique ] List of time series to unlink instanceIds for. |
Responses
Request samples
- Payload
{- "items": [
- [
- {
- "id": 1
}
]
]
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 1,
- "externalId": "string",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "name": "string",
- "isString": true,
- "type": "string",
- "stateSet": {
- "space": "string",
- "externalId": "string"
}, - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "unit": "string",
- "unitExternalId": "string",
- "assetId": 1,
- "isStep": true,
- "description": "string",
- "securityCategories": [
- 0
], - "dataSetId": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "pendingInstanceId": {
- "space": "string",
- "externalId": "string"
}
}
]
}Update time series
Updates one or more time series. Fields outside of the request remain unchanged.
For primitive fields (those whose type is string, number, or boolean), use "set": value
to update the value; use "setNull": true to set the field to null.
For JSON array fields (for example securityCategories), use "set": [value1, value2] to
update the value; use "add": [value1, value2] to add values; use
"remove": [value1, value2] to remove values.
Authorizations:
Request Body schema: application/jsonrequired
List of changes.
required | Array of TimeSeriesUpdateById (object) or TimeSeriesUpdateByExternalId (object) or TimeSeriesUpdateByInstanceId (object) (TimeSeriesUpdate) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1,
- "update": {
- "externalId": {
- "set": "string"
}, - "name": {
- "set": "string"
}, - "metadata": {
- "set": {
- "key1": "value1",
- "key2": "value2"
}
}, - "unit": {
- "set": "string"
}, - "unitExternalId": {
- "set": "string"
}, - "assetId": {
- "set": 0
}, - "isStep": {
- "set": true
}, - "description": {
- "set": "string"
}, - "securityCategories": {
- "set": [
- 0
]
}, - "dataSetId": {
- "set": 0
}
}
}
]
}Response samples
- 200
- 400
- 409
- 422
{- "items": [
- {
- "id": 1,
- "externalId": "string",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "name": "string",
- "isString": true,
- "type": "string",
- "stateSet": {
- "space": "string",
- "externalId": "string"
}, - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "unit": "string",
- "unitExternalId": "string",
- "assetId": 1,
- "isStep": true,
- "description": "string",
- "securityCategories": [
- 0
], - "dataSetId": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Upgrade to data modeling
Set pending instance ID for a time series. This is used to upgrade the time series to data modeling, maintaining the data points and metadata. This endpoint is only available in the alpha version of the API for a limited time. Please consult with your Cognite support representative before using this endpoint.
Authorizations:
Request Body schema: application/json
required | Array of SetWithInternalId (object) or SetWithExternalId (object) [ 1 .. 1000 ] items List of time series to set pending instance ids for. |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 1,
- "pendingInstanceId": {
- "space": "string",
- "externalId": "string"
}
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 1,
- "externalId": "string",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "name": "string",
- "isString": true,
- "type": "string",
- "stateSet": {
- "space": "string",
- "externalId": "string"
}, - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "unit": "string",
- "unitExternalId": "string",
- "assetId": 1,
- "isStep": true,
- "description": "string",
- "securityCategories": [
- 0
], - "dataSetId": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "pendingInstanceId": {
- "space": "string",
- "externalId": "string"
}
}
]
}Synthetic Time Series (STS) is a way to combine various input time series, constants and operators, to create completely new time series.
For example can we use the expression 24 * TS{externalId='production/hour'} to convert from hourly to daily production rates.
But STS is not limited to simple conversions.
- We support combination of different time series
TS{id=123} + TS{externalId='hei'} / TS{space='data modeling space', externalId='dm id'}. - Functions of time series
sin(pow(TS{id=123}, 2)). - Aggregations of time series
TS{id=123, aggregate='average', granularity='1h'}+TS{id=456} - Convert time series with
unitExternalIdto another unitTS{externalId='temp_c', targetUnit='temperature:deg_f'}.
To learn more about synthetic time series please follow our guide.
Synthetic query
Execute an on-the-fly synthetic query
Authorizations:
Request Body schema: application/jsonrequired
The list of queries to perform
required | Array of objects (SyntheticQuery) [ 1 .. 10 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
{- "items": [
- {
- "expression": "(5 + TS{externalId='hello'}) / TS{id=123, aggregate='average', granularity='1h'} * TS{space='dm space', externalId='dm id'}",
- "start": 0,
- "end": 0,
- "limit": 100,
- "timeZone": "Europe/Oslo or UTC+05:30"
}
]
}Response samples
- 200
{- "items": [
- {
- "isString": false,
- "datapoints": [
- {
- "timestamp": 1730204346000,
- "value": 0
}
]
}
]
}A data point subscription is a way to listen to changes to time series data points, in ingestion order.
A single subscription can listen to many time series, and a time series can be part of many subscriptions.
You listen to subscriptions by calling the “list subscription data“ endpoint. It will return a list of data point upserts and deleted ranges, together with a cursor to retrieve the next batch of updates. Updates written since the creation of the subscription, up to 7 days ago, can be retrieved through the subscription.
Subscriptions can be defined explicitly through a list of time series external ids and instance ids, or implicitly through a filter. The filter is a subset of the advanced filter query in the regular “time series search“ endpoint.
Partitions: Subscriptions can be further divided into a number of partitions, for the purpose of fetching subscription data in parallel. Each partition will return data in ingestion order, but the order between partitions is not guaranteed.
Limitations:
- Each subscription can have at most 10000 time series.
- A time series can be part of at most 10 subscriptions.
- A project can have at most 1000 subscriptions, of which 100 are filter subscriptions.
- Time series with security categories can not be shown in filter subscriptions.
- Time series with neither external id nor instance id cannot be added to non-filter subscriptions.
- The number of partitions cannot be changed after creation.
Access control: You need READ access to subscriptions ACL to read/list subscriptions or list data, and you need WRITE access to create/update/delete subscriptions. Furthermore, you need READ access to the time series you want to get updates from. For filter subscriptions, you either need READ access to all time series, or the filter must be restricted according to your access rights (e.g. by filtering on specific data set IDs).
Subscriptions can have data sets that allow for more granular access control. The data set on a subscription does not influence the data stream, but allows you to restrict who can read/update the subscription.
Name of ACL:
timeSeriesSubscriptionsAcl
Supported actions:
READWRITE
Example capabilities:
[
{"timeSeriesAcl":{"actions":["READ"], "scope":{"all":{}}}},
{"timeSeriesSubscriptionsAcl":{"actions":["WRITE", "READ"], "scope":{"all":{}}}}
]
Create subscriptions
Create one or more subscriptions that can be used to listen for changes in data points for a set of time series.
Authorizations:
Request Body schema: application/jsonrequired
The subscriptions to create.
required | Array of objects = 1 items
Subscription definitions. A subscription may be configured explicitly with a list
of time series, or it may be a configured dynamically through a filter. The
subscription cannot change type later.
|
| Leaf filter | Supported fields | Description and example |
|---|---|---|
containsAll |
Array type fields | Only includes results which contain all of the specified values. {"containsAll": {"property": ["property"], "values": [1, 2, 3]}} |
containsAny |
Array type fields | Only includes results which contain at least one of the specified values. {"containsAny": {"property": ["property"], "values": [1, 2, 3]}} |
equals |
Non-array type fields | Only includes results that are equal to the specified value. {"equals": {"property": ["property"], "value": "example"}} |
exists |
All fields | Only includes results where the specified property exists (has a value). {"exists": {"property": ["property"]}} |
in |
Non-array type fields | Only includes results that are equal to one of the specified values. {"in": {"property": ["property"], "values": [1, 2, 3]}} |
prefix |
String type fields | Only includes results which start with the specified text. {"prefix": {"property": ["property"], "value": "example"}} |
range |
Non-array type fields | Only includes results that fall within the specified range. {"range": {"property": ["property"], "gt": 1, "lte": 5}} Supported operators: gt, lt, gte, lte |
Supported properties
| Property | Type |
|---|---|
["description"] |
string |
["externalId"] |
string |
["metadata", "<someCustomKey>"] |
string |
["name"] |
string |
["unit"] |
string |
["unitExternalId"] |
string |
["unitQuantity"] |
string |
["instanceId", "space"] |
string |
["instanceId", "externalId"] |
string |
["assetId"] |
number |
["assetRootId"] |
number |
["createdTime"] |
number |
["dataSetId"] |
number |
["id"] |
number |
["lastUpdatedTime"] |
number |
["isStep"] |
Boolean |
["isString"] |
Boolean |
Limits
- Filter query max depth: 10.
- Filter query max number of clauses: 100.
andandorclauses must have at least one element (and at most 99, since each element counts towards the total clause limit, and so does theand/orclause itself).- The
propertyarray of each leaf filter has the following limitations:- Number of elements in the array is 1 or 2.
- Elements must not be null or blank.
- Each element max length is 256 characters.
- The
propertyarray must match one of the existing properties (static top-level property or dynamic metadata property).
containsAll,containsAny, andinfiltervaluesarray size must be in the range [1, 100].containsAll,containsAny, andinfiltervaluesarray must contain elements of number or string type (matching the type of the given property).rangefilter must have at lest one ofgt,gte,lt,lteattributes. Butgtis mutually exclusive togte, whileltis mutually exclusive tolte.gt,gte,lt,ltein therangefilter must be of number or string type (matching the type of the given property).- The maximum length of the
valueof a leaf filter that is applied to a string property is 256.
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "string",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "partitionCount": 1,
- "timeSeriesIds": [
- "my.known.id"
], - "instanceIds": [
- {
- "space": "string",
- "externalId": "string"
}
], - "filter": {
- "or": [
- {
- "not": {
- "and": [
- {
- "equals": {
- "property": [
- "metadata",
- "manufacturer"
], - "value": "acme"
}
}, - {
- "in": {
- "property": [
- "name"
], - "values": [
- "pump-1-temperature",
- "motor-9-temperature"
]
}
}, - {
- "range": {
- "property": [
- "dataSetId"
], - "gte": 1,
- "lt": 10
}
}
]
}
}, - {
- "and": [
- {
- "equals": {
- "property": [
- "assetId"
], - "value": 1234
}
}, - {
- "equals": {
- "property": [
- "description"
], - "value": "Temperature in Celsius"
}
}
]
}
]
}
}
]
}Response samples
- 201
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "partitionCount": 1,
- "timeSeriesCount": 0,
- "filter": {
- "or": [
- {
- "not": {
- "and": [
- {
- "equals": {
- "property": [
- "metadata",
- "manufacturer"
], - "value": "acme"
}
}, - {
- "in": {
- "property": [
- "name"
], - "values": [
- "pump-1-temperature",
- "motor-9-temperature"
]
}
}, - {
- "range": {
- "property": [
- "dataSetId"
], - "gte": 1,
- "lt": 10
}
}
]
}
}, - {
- "and": [
- {
- "equals": {
- "property": [
- "assetId"
], - "value": 1234
}
}, - {
- "equals": {
- "property": [
- "description"
], - "value": "Temperature in Celsius"
}
}
]
}
]
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Delete subscriptions
Delete subscription(s). This operation cannot be undone
Authorizations:
Request Body schema: application/jsonrequired
Specify a list of the subscriptions to delete.
required | Array of objects (QueryWithExternalId) = 1 items unique List of ID objects |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "my.known.id"
}
], - "ignoreUnknownIds": false
}Response samples
- 200
- 400
{ }List subscription data
Fetch the next batch of data from a given subscription and partition(s). Data can be ingested datapoints and time ranges where data is deleted. This endpoint will also return changes to the subscription itself, that is, if time series are added or removed from the subscription.
The data can be returned multiple times, there is no mechanism to acknowledge or delete data. Use cursors to paginate through the results.
Authorizations:
Request Body schema: application/json
| externalId | string (CogniteExternalId) <= 255 characters The external ID provided by the client. Must be unique for the resource type. |
required | Array of objects (SubscriptionsDataPartitionRequestDTO) Pairs of (partition, cursor) to fetch from. |
| limit | integer [ 1 .. 100000 ] Default: 100 Approximate number of results to return across all partitions. We will batch together groups of updates, where each group come from the same ingestion request. Thus, if a single group is large, it may exceed limit, otherwise we will return up to limit results. To check whether you have reached the end, do not rely on the count. Instead, check the |
| initializeCursors | string If The format is "N[timeunit]-ago", where timeunit is w,d,h,m (week, day, hour, minute). For instance, "2d-ago" will give a stream of changes ingested up to 2 days ago. You can also use "now" to jump straight to the end of the stream. Note that initializeCursors is not exact; a deviation of some seconds can occur. |
| pollTimeoutSeconds | integer [ 0 .. 5 ] Default: 5 The maximum time to wait for data to arrive, in seconds. As soon as data is available, the request will return immediately with the data. If the timeout is reached while waiting for data, the request will return an empty data response. |
| includeStatus | boolean Default: false Show the status code for each data point in the response. Good (code = 0) status codes are always omitted. |
| ignoreBadDataPoints | boolean Default: true Treat data points with a Bad status code as if they do not exist. Set to false to include all data points. |
| treatUncertainAsBad | boolean Default: true Treat data points with Uncertain status codes as Bad. Set to false to include uncertain data points. |
Responses
Request samples
- Payload
- Python SDK
{- "externalId": "my.known.id",
- "partitions": [
- {
- "index": 0,
- "cursor": "string"
}
], - "limit": 100,
- "initializeCursors": "string",
- "pollTimeoutSeconds": 5,
- "includeStatus": false,
- "ignoreBadDataPoints": true,
- "treatUncertainAsBad": true
}Response samples
- 200
{- "updates": [
- {
- "timeSeries": {
- "id": 1,
- "externalId": "my.known.id",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "isString": true,
- "type": "string"
}, - "upserts": [
- {
- "timestamp": -2208988800000,
- "value": 0,
- "status": {
- "code": 0,
- "symbol": "string"
}
}
], - "deletes": [
- {
- "inclusiveBegin": 1638795554528,
- "exclusiveEnd": 1638795554528
}
]
}
], - "subscriptionChanges": {
- "added": [
- {
- "id": 1,
- "externalId": "my.known.id",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "isString": true,
- "type": "string"
}
], - "removed": [
- {
- "id": 1,
- "externalId": "my.known.id",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "isString": true,
- "type": "string"
}
]
}, - "partitions": [
- {
- "index": 0,
- "nextCursor": "string"
}
], - "hasNext": true
}List subscription members
List all member time series for a subscription.
For non-filter subscriptions, either externalId or instanceId will be set. This is to be
able to see if each time series was added by external id or instance id. If a time series
has been added to a subscription both by external id and by instance id, it will be listed
twice in the output. If a time series that belonged to the subscription has been deleted,
id will not be set.
Use nextCursor to paginate through the results.
Authorizations:
query Parameters
| limit | integer <int32> [ 1 .. 100 ] Default: 100 Limit on the number of results to return. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| externalId | string (CogniteExternalId) <= 255 characters Example: externalId=my.known.id External id of the subscription. |
Responses
Request samples
- Python SDK
from cognite.client.data_classes import DataPointSubscriptionUpdate members = client.time_series.subscriptions.list_member_time_series("my_subscription") timeseries_external_ids = members.as_external_ids()
Response samples
- 200
{- "items": [
- {
- "externalId": "my.known.id",
- "id": 1,
- "instanceId": {
- "space": "string",
- "externalId": "string"
}
}
], - "nextCursor": "string"
}List subscriptions
List all subscriptions for the tenant. Use nextCursor to paginate through the results.
Authorizations:
query Parameters
| limit | integer <int32> [ 1 .. 100 ] Default: 100 Limit on the number of results to return. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Request samples
- Python SDK
subscriptions = client.time_series.subscriptions.list(limit=5)
Response samples
- 200
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "partitionCount": 1,
- "timeSeriesCount": 0,
- "filter": {
- "or": [
- {
- "not": {
- "and": [
- {
- "equals": {
- "property": [
- "metadata",
- "manufacturer"
], - "value": "acme"
}
}, - {
- "in": {
- "property": [
- "name"
], - "values": [
- "pump-1-temperature",
- "motor-9-temperature"
]
}
}, - {
- "range": {
- "property": [
- "dataSetId"
], - "gte": 1,
- "lt": 10
}
}
]
}
}, - {
- "and": [
- {
- "equals": {
- "property": [
- "assetId"
], - "value": 1234
}
}, - {
- "equals": {
- "property": [
- "description"
], - "value": "Temperature in Celsius"
}
}
]
}
]
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
], - "nextCursor": "string"
}Retrieve subscriptions
Retrieve one or more subscriptions by external ID.
Authorizations:
Request Body schema: application/jsonrequired
Specify a list of the subscriptions to retrieve.
required | Array of objects (QueryWithExternalId) = 1 items unique List of ID objects |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "my.known.id"
}
], - "ignoreUnknownIds": false
}Response samples
- 200
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "partitionCount": 1,
- "timeSeriesCount": 0,
- "filter": {
- "or": [
- {
- "not": {
- "and": [
- {
- "equals": {
- "property": [
- "metadata",
- "manufacturer"
], - "value": "acme"
}
}, - {
- "in": {
- "property": [
- "name"
], - "values": [
- "pump-1-temperature",
- "motor-9-temperature"
]
}
}, - {
- "range": {
- "property": [
- "dataSetId"
], - "gte": 1,
- "lt": 10
}
}
]
}
}, - {
- "and": [
- {
- "equals": {
- "property": [
- "assetId"
], - "value": 1234
}
}, - {
- "equals": {
- "property": [
- "description"
], - "value": "Temperature in Celsius"
}
}
]
}
]
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Update subscriptions
Updates one or more subscriptions. Fields that are not included in the request, are not changed.
If both instanceIds and timeSeriesIds are set, they must either both be add/remove or
both be set operations.
Authorizations:
Request Body schema: application/jsonrequired
The subscriptions to update
required | Array of objects (Select by externalId) = 1 items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "my.known.id",
- "update": {
- "timeSeriesIds": {
- "add": [
- "my.known.id"
], - "remove": [
- "my.known.id"
]
}, - "instanceIds": {
- "add": [
- {
- "space": "string",
- "externalId": "string"
}
], - "remove": [
- {
- "space": "string",
- "externalId": "string"
}
]
}, - "name": {
- "set": "string"
}, - "description": {
- "set": "string"
}, - "dataSetId": {
- "set": 0
}, - "filter": {
- "set": {
- "or": [
- {
- "not": {
- "and": [
- {
- "equals": {
- "property": [
- "metadata",
- "manufacturer"
], - "value": "acme"
}
}, - {
- "in": {
- "property": [
- "name"
], - "values": [
- "pump-1-temperature",
- "motor-9-temperature"
]
}
}, - {
- "range": {
- "property": [
- "dataSetId"
], - "gte": 1,
- "lt": 10
}
}
]
}
}, - {
- "and": [
- {
- "equals": {
- "property": [
- "assetId"
], - "value": 1234
}
}, - {
- "equals": {
- "property": [
- "description"
], - "value": "Temperature in Celsius"
}
}
]
}
]
}
}
}
}
]
}Response samples
- 200
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "partitionCount": 1,
- "timeSeriesCount": 0,
- "filter": {
- "or": [
- {
- "not": {
- "and": [
- {
- "equals": {
- "property": [
- "metadata",
- "manufacturer"
], - "value": "acme"
}
}, - {
- "in": {
- "property": [
- "name"
], - "values": [
- "pump-1-temperature",
- "motor-9-temperature"
]
}
}, - {
- "range": {
- "property": [
- "dataSetId"
], - "gte": 1,
- "lt": 10
}
}
]
}
}, - {
- "and": [
- {
- "equals": {
- "property": [
- "assetId"
], - "value": 1234
}
}, - {
- "equals": {
- "property": [
- "description"
], - "value": "Temperature in Celsius"
}
}
]
}
]
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Events objects store complex information about multiple assets over a time period.
Typical types of events that would be stored in this service might include Alarms, Process Data, and Logs.
For the storage of low volume, manually generated, schedulable activities (such as maintenance schedules,
work orders or other ‘appointment’ type activities, the Data Modeling service is now recommended.
Important Note:
Events and Time Series are somewhat closely related in that both are high volume types of data,
capable of recording data in microsecond resolutions. However, Events is not recommended as a Time Series store,
such as where the data flow is from a single instance of sensors (i.e. temperature, pressure, voltage),
simulators or state machines (on, off, disconnected, etc).
Time Series offers very low latency read and write performance, as well as specialised filters and aggregations that
are tailored to the analysis of time series data.
An event’s time period is defined by a start time and end time, both millisecond timestamps since the UNIX epoch.
The timestamps can be in the future. In addition, events can have a text description as well as arbitrary metadata and properties.
When storing event information in metadata, it should be considered that all data is stored as string format.
Note:
In Events API, timestamps are treated as strings when added to metadata fields and aren’t converted to the user’s local time zone.
**Caveats:**
Due to the eventually consistent nature of Asset IDs stored in Events,
it should be noted that Asset ID references obtained from the Events API may
occasionally be invalid (such as if an Asset ID is deleted,
but the reference to that ID remains in the Event record for a time).
Asset references obtained from an event - through asset ids - may be invalid, simply by the non-transactional nature of HTTP. They are maintained in an eventual consistent manner.
Both the rate of requests (denoted as request per second, or ‘rps’) and the number of concurrent (parallel) requests are governed by limits,
for all CDF API endpoints. If a request exceeds one of the limits,
it will be throttled with a 429: Too Many Requests response. More on limit types
and how to avoid being throttled is described
here.
Limits are defined at both the overall API service level, and on the API endpoints belonging to the service.
Some types of requests consume more resources (compute, storage IO) than others, and where a service handles
multiple concurrent requests with varying resource consumption.
For example, ‘CRUD’ type requests (Create, Retrieve, Request ByIDs, Update and Delete) are far less resource
intensive than ‘Analytical’ type requests (List, Search and Filter) and in addition, the most resource
intensive Analytical endpoint of all, Aggregates, receives its own request budget within the overall Analytical request budget.
The version 1.0 limits for the overall API service and its constituent endpoints are illustrated in the diagram below.
These limits are subject to change, pending review of changing consumption patterns and resource availability over time:
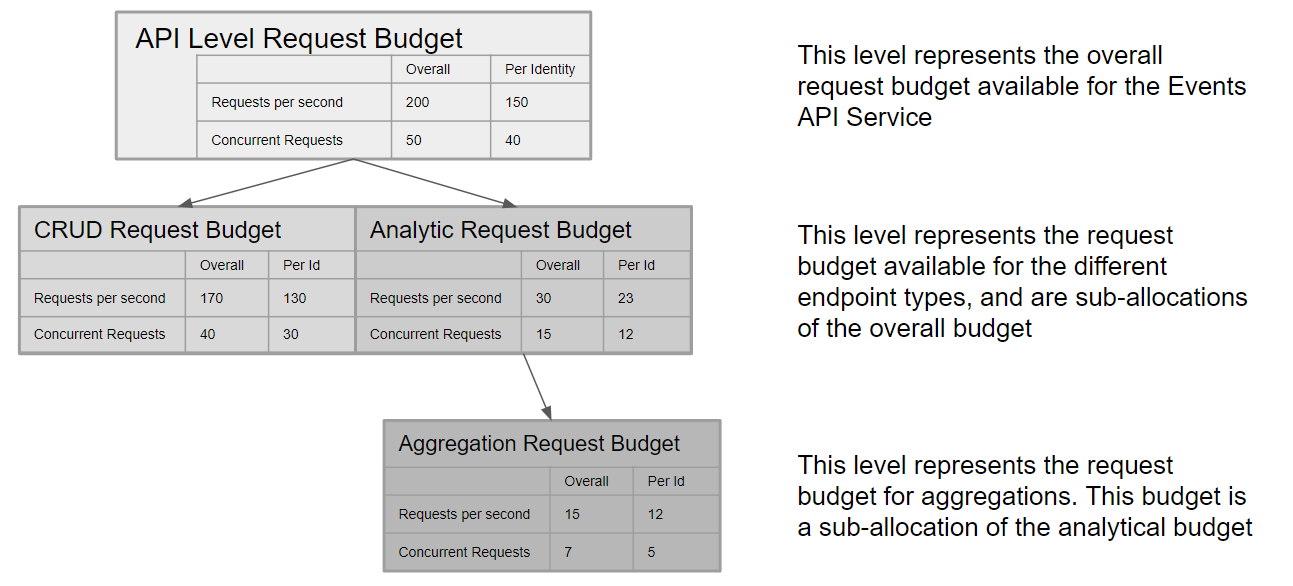
Translating RPS into data speed
A single request may retrieve up to 1000 items. In the context of Events, 1 item = 1 event record
Therefore, the maximum theoretical data speed at the top API service level is 200,000 items per second for all consumers,
and 150,000 for a single identity or client in a project.
Use of Partitions / Parallel Retrieval
As a general guidance, Parallel Retrieval is a technique that should be used where due to query complexity, retrieval of data in a single request session turns out to be slow. By parallelizing such requests, data retrieval performance can be tuned to meet the client application needs. Parallel retrieval may also be used where retrieval of large sets of data is required, up to the capacity limits defined for a given API service. For example (using the Events API request budget):
- A single request may retrieve up to 1000 items
- Up to 23 requests per second may be issued for an analytical query (per identity), such as when using /list or /filter API endpoints
- This provides a theoretical maximum of 23,000 items read per second per identity
- The query complexity may result in it taking longer than 1s to read or write 1000 items in a single request
- Therefore, it is appropriate to specify the query to retrieve a lower number of items per request, and retrieve more items in parallel, up to the theoretical maximum performance of 23,000 items per second.
Important Note:
Parallel retrieval should be only used in situations where, due to query complexity,
a single request flow provides data retrieval speeds that are significantly less than the theoretical maximum.
Parallel retrieval does not act as a speed multiplier on optimally running queries. Regardless of the number
of concurrent requests issued, the overall requests per second limit still applies.
So for example, a single request returning data at approximately 18,000 items per second will only
benefit from adding a second parallel request, the capacity of which goes somewhat wasted
as only an additional 5,000 items per second will return before the request rate budget limit is reached.
Aggregate events
The aggregation API lets you compute aggregated results on events, such as getting the count of all Events in a project, checking different descriptions of events in your project, etc.
Aggregate filtering
Filter (filter & advancedFilter) data for aggregates
Filters behave the same way as for the Filter events endpoint.
In text properties, the values are aggregated in a case-insensitive manner.
aggregateFilter to filter aggregate results
aggregateFilter works similarly to advancedFilter but always applies to aggregate properties.
For instance, in an aggregation for the source property, only the values (aka buckets) of the source property can be filtered out.
Request throttling
This endpoint is meant for data analytics/exploration usage and is not suitable for high load data retrieval usage.
The Aggregates endpoint, as with all endpoints in the Events API, is subject to a request budget that applies
limits to both request rate and concurrency.
Please check Events resource description for more information.
Authorizations:
Request Body schema: application/json
| aggregate | string Value: "count" Type of aggregation to apply.
|
(BoolFilter (and (object) or or (object) or not (object))) or (LeafFilter (equals (object) or in (object) or range (object) or prefix (object) or exists (object) or containsAny (object) or containsAll (object) or search (object))) (EventAdvancedFilter) | |
object (EventFilter) Filter on events filter with exact match |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "aggregate": "count",
- "advancedFilter": {
- "or": [
- {
- "not": {
- "and": [
- {
- "equals": {
- "property": [
- "metadata",
- "severity"
], - "value": "medium"
}
}, - {
- "in": {
- "property": [
- "source"
], - "values": [
- "inspection protocol",
- "incident report"
]
}
}, - {
- "range": {
- "property": [
- "dataSetId"
], - "gte": 1,
- "lt": 10
}
}
]
}
}, - {
- "and": [
- {
- "equals": {
- "property": [
- "type"
], - "value": "equipment malfunction"
}
}, - {
- "equals": {
- "property": [
- "subtype"
], - "value": "mechanical failure"
}
}
]
}, - {
- "search": {
- "property": [
- "description"
], - "value": "outage"
}
}
]
}, - "filter": {
- "startTime": {
- "max": 0,
- "min": 0
}, - "endTime": {
- "max": 0,
- "min": 0
}, - "activeAtTime": {
- "max": 0,
- "min": 0
}, - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "assetExternalIds": [
- "my.known.id"
], - "assetSubtreeIds": [
- {
- "id": 1
}
], - "dataSetId": {
- "in": [
- {
- "id": 123
}, - {
- "externalId": "my.known.id"
}
], - "isNull": true
}, - "dataSetIds": [
- {
- "id": 1
}
], - "source": "string",
- "type": "string",
- "subtype": "string",
- "createdTime": {
- "max": 0,
- "min": 0
}, - "lastUpdatedTime": {
- "max": 0,
- "min": 0
}, - "externalIdPrefix": "my.known.prefix"
}
}Response samples
- 200
- 400
- 429
{- "items": [
- {
- "count": 10
}
]
}Create events
Creates multiple event objects in the same project. It is possible to post a maximum of 1000 events per request.
Request throttling
This endpoint is a subject of the new throttling schema (limited request rate and concurrency). Please check Events resource description for more information.
Authorizations:
Request Body schema: application/jsonrequired
List of events to be posted. It is possible to post a maximum of 1000 events per request.
required | Array of objects (ExternalEvent) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "externalId": "my.known.id",
- "dataSetId": 1,
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "type": "string",
- "subtype": "string",
- "description": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "source": "string"
}
]
}Response samples
- 201
- 400
- 429
{- "items": [
- {
- "externalId": "my.known.id",
- "dataSetId": 1,
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "type": "string",
- "subtype": "string",
- "description": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "source": "string",
- "id": 1,
- "lastUpdatedTime": 1730204346000,
- "createdTime": 1730204346000
}
]
}Delete events
Deletes events with the given ids. A maximum of 1000 events can be deleted per request.
Request throttling
This endpoint is a subject of the new throttling schema (limited request rate and concurrency). Please check Events resource description for more information.
Authorizations:
Request Body schema: application/jsonrequired
List of IDs to delete.
required | Array of InternalId (object) or ExternalId (object) (EitherId) [ 1 .. 1000 ] items |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1
}
], - "ignoreUnknownIds": false
}Response samples
- 200
- 400
- 429
{ }Filter events
Retrieve a list of events in the same project. This operation supports pagination by cursor. Apply Filtering and Advanced filtering criteria to select a subset of events.
Advanced filtering
Advanced filter lets you create complex filtering expressions that combine simple operations,
such as equals, prefix, exists, etc., using boolean operators and, or, and not.
It applies to basic fields as well as metadata.
See the advancedFilter attribute in the example.
See more information about filtering DSL here.
Supported leaf filters
| Leaf filter | Supported fields | Description |
|---|---|---|
containsAll |
Array type fields | Only includes results which contain all of the specified values. {"containsAll": {"property": ["property"], "values": [1, 2, 3]}} |
containsAny |
Array type fields | Only includes results which contain at least one of the specified values. {"containsAny": {"property": ["property"], "values": [1, 2, 3]}} |
equals |
Non-array type fields | Only includes results that are equal to the specified value. {"equals": {"property": ["property"], "value": "example"}} |
exists |
All fields | Only includes results where the specified property exists (has value). {"exists": {"property": ["property"]}} |
in |
Non-array type fields | Only includes results that are equal to one of the specified values. {"in": {"property": ["property"], "values": [1, 2, 3]}} |
prefix |
String type fields | Only includes results which start with the specified value. {"prefix": {"property": ["property"], "value": "example"}} |
range |
Non-array type fields | Only includes results that fall within the specified range. {"range": {"property": ["property"], "gt": 1, "lte": 5}} Supported operators: gt, lt, gte, lte |
search |
["description"] |
Introduced to provide functional parity with /events/search endpoint. {"search": {"property": ["property"], "value": "example"}} |
Search
The search leaf filter provides functional parity with the /events/search endpoint.
It's available only for the ["description"] field. When specifying only this filter with no explicit ordering,
behavior is the same as of the /events/search/ endpoint without specifying filters.
Explicit sorting overrides the default ordering by relevance.
It's possible to use the search leaf filter as any other leaf filter for creating complex queries.
See the search filter in the advancedFilter attribute in the example.
advancedFilter attribute limits
- filter query max depth: 10
- filter query max number of clauses: 100
- filter by metadata is case-insensitive, and it supports filtering on keys and values up to 256 characters
andandorclauses must have at least one elementpropertyarray of each leaf filter has the following limitations:- number of elements in the array is in the range [1, 2]
- elements must not be blank
- each element max length is 128 symbols
- property array must match one of the existing properties (static or dynamic metadata)
containsAll,containsAny, andinfiltervaluesarray size must be in the range [1, 100]containsAll,containsAny, andinfiltervaluesarray must contain elements of a primitive type (number, string)rangefilter must have at least one ofgt,gte,lt,lteattributes. Butgtis mutually exclusive togte, whileltis mutually exclusive tolte. For metadata, both upper and lower bounds must be specified.gt,gte,lt,ltein therangefilter must be a primitive valuesearchfiltervaluemust not be blank and the length must be in the range [1, 128]- filter query may have maximum 2 search leaf filters
- maximum leaf filter string value length is different depending on the property the filter is using:
externalId- 255description- 128 for thesearchfilter and 255 for other filterstype- 64subtype- 64source- 128- any
metadatakey - 128
Sorting
By default, events are sorted by their creation time in the ascending order.
Use the search leaf filter to sort the results by relevance.
Sorting by other fields can be explicitly requested. The order field is optional and defaults
to desc for _score_ and asc for all other fields.
The nulls field is optional and defaults to auto. auto is translated to last
for the asc order and to first for the desc order by the service.
Partitions are done independently of sorting: there's no guarantee of the sort order between elements from different partitions.
See the sort attribute in the example.
Null values
In case the nulls attribute has the auto value or the attribute isn't specified,
null (missing) values are considered to be bigger than any other values.
They are placed last when sorting in the asc order and first when sorting in desc.
Otherwise, missing values are placed according to the nulls attribute (last or first), and their placement doesn't depend on the order value.
Values, such as empty strings, aren't considered as nulls.
Sorting by score
Use a special sort property _score_ when sorting by relevance.
The more filters a particular event matches, the higher its score is. This can be useful,
for example, when building UIs. Let's assume we want exact matches to be be displayed above matches by
prefix as in the request below. An event with the type fire will match both equals and prefix
filters and, therefore, have higher score than events with names like fire training that match only the prefix filter.
"advancedFilter" : {
"or" : [
{
"equals": {
"property": ["type"],
"value": "fire"
}
},
{
"prefix": {
"property": ["type"],
"value": "fire"
}
}
]
},
"sort": [
{
"property" : ["_score_"]
}
]
Request throttling
This endpoint is meant for data analytics/exploration usage and is not suitable for high load data retrieval usage. It is a subject of the new throttling schema (limited request rate and concurrency). Please check Events resource description for more information.
Authorizations:
Request Body schema: application/json
object (EventFilter) Filter on events filter with exact match | |
(BoolFilter (and (object) or or (object) or not (object))) or (LeafFilter (equals (object) or in (object) or range (object) or prefix (object) or exists (object) or containsAny (object) or containsAll (object) or search (object))) (EventAdvancedFilter) | |
| limit | integer <int32> [ 1 .. 1000 ] Default: 100 Limits the maximum number of results to be returned by a single request. In case there are more results to the request, the 'nextCursor' attribute will be provided as part of the response. Request may contain less results than the request limit. |
Array of objects (modern) <= 2 items Sort by array of selected properties. | |
| cursor | string |
| partition | string (PartitionLimited10) Splits the data set into The maximum number of allowed partitions ( Cognite rejects requests if you specify more than 10 partitions. When Cognite enforces this behavior, the requests result in a 400 Bad Request status. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "filter": {
- "startTime": {
- "max": 0,
- "min": 0
}, - "endTime": {
- "max": 0,
- "min": 0
}, - "activeAtTime": {
- "max": 0,
- "min": 0
}, - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "assetExternalIds": [
- "my.known.id"
], - "assetSubtreeIds": [
- {
- "id": 1
}
], - "dataSetId": {
- "in": [
- {
- "id": 123
}, - {
- "externalId": "my.known.id"
}
], - "isNull": true
}, - "dataSetIds": [
- {
- "id": 1
}
], - "source": "string",
- "type": "string",
- "subtype": "string",
- "createdTime": {
- "max": 0,
- "min": 0
}, - "lastUpdatedTime": {
- "max": 0,
- "min": 0
}, - "externalIdPrefix": "my.known.prefix"
}, - "advancedFilter": {
- "or": [
- {
- "not": {
- "and": [
- {
- "equals": {
- "property": [
- "metadata",
- "severity"
], - "value": "medium"
}
}, - {
- "in": {
- "property": [
- "source"
], - "values": [
- "inspection protocol",
- "incident report"
]
}
}, - {
- "range": {
- "property": [
- "dataSetId"
], - "gte": 1,
- "lt": 10
}
}
]
}
}, - {
- "and": [
- {
- "equals": {
- "property": [
- "type"
], - "value": "equipment malfunction"
}
}, - {
- "equals": {
- "property": [
- "subtype"
], - "value": "mechanical failure"
}
}
]
}, - {
- "search": {
- "property": [
- "description"
], - "value": "outage"
}
}
]
}, - "limit": 100,
- "sort": [
- {
- "property": [
- "createdTime"
], - "order": "desc"
}, - {
- "property": [
- "metadata",
- "FooBar"
], - "nulls": "first"
}
], - "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo",
- "partition": "1/3"
}Response samples
- 200
- 400
- 429
{- "items": [
- {
- "externalId": "my.known.id",
- "dataSetId": 1,
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "type": "string",
- "subtype": "string",
- "description": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "source": "string",
- "id": 1,
- "lastUpdatedTime": 1730204346000,
- "createdTime": 1730204346000
}
], - "nextCursor": "string"
}List events
List events optionally filtered on query parameters
Request throttling
This endpoint is meant for data analytics/exploration usage and is not suitable for high load data retrieval usage. It is a subject of the new throttling schema (limited request rate and concurrency). Please check Events resource description for more information.
Authorizations:
query Parameters
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 1000 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| minStartTime | integer <int64> (EpochTimestamp) >= 0 Example: minStartTime=1730204346000 The number of milliseconds since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| maxStartTime | integer <int64> (EpochTimestamp) >= 0 Example: maxStartTime=1730204346000 The number of milliseconds since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| minEndTime | integer <int64> (EpochTimestamp) >= 0 Example: minEndTime=1730204346000 The number of milliseconds since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| maxEndTime | integer <int64> (EpochTimestamp) >= 0 Example: maxEndTime=1730204346000 The number of milliseconds since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| minActiveAtTime | integer <int64> >= 0 Example: minActiveAtTime=1730204346000 Event is considered active from its startTime to endTime inclusive. If startTime is null, event is never active. If endTime is null, event is active from startTime onwards. activeAtTime filter will match all events that are active at some point from min to max, from min, or to max, depending on which of min and max parameters are specified. |
| maxActiveAtTime | integer <int64> >= 0 Example: maxActiveAtTime=1730204346000 Event is considered active from its startTime to endTime inclusive. If startTime is null, event is never active. If endTime is null, event is active from startTime onwards. activeAtTime filter will match all events that are active at some point from min to max, from min, or to max, depending on which of min and max parameters are specified. |
| assetIds | string <jsonArray(int64)> (JsonArrayInt64) Example: assetIds=[363848954441724, 793045462540095, 1261042166839739] Asset IDs of equipment that this event relates to. Format is list of IDs serialized as JSON array(int64). Takes [ 1 .. 100 ] of unique items. |
| assetExternalIds | string <jsonArray(string)> (JsonArrayString) Example: assetExternalIds=["externalId1", "externalId2", "externalId3"] Asset external IDs of equipment that this event relates to. Takes 1..100 unique items. |
| assetSubtreeIds | string <jsonArray(int64)> (JsonArrayInt64) Example: assetSubtreeIds=[363848954441724, 793045462540095, 1261042166839739] Only include events that have a related asset in a subtree rooted at any of these assetIds (including the roots given). If the total size of the given subtrees exceeds 100,000 assets, an error will be returned. |
| assetSubtreeExternalIds | string <jsonArray(string)> (JsonArrayString) Example: assetSubtreeExternalIds=["externalId1", "externalId2", "externalId3"] Only include events that have a related asset in a subtree rooted at any of these assetExternalIds (including the roots given). If the total size of the given subtrees exceeds 100,000 assets, an error will be returned. |
| source | string <= 128 characters The source of this event. |
| type | string (EventType) <= 64 characters Type of the event, e.g 'failure'. |
| subtype | string (EventSubType) <= 64 characters SubType of the event, e.g 'electrical'. |
| minCreatedTime | integer <int64> (EpochTimestamp) >= 0 Example: minCreatedTime=1730204346000 The number of milliseconds since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| maxCreatedTime | integer <int64> (EpochTimestamp) >= 0 Example: maxCreatedTime=1730204346000 The number of milliseconds since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| minLastUpdatedTime | integer <int64> (EpochTimestamp) >= 0 Example: minLastUpdatedTime=1730204346000 The number of milliseconds since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| maxLastUpdatedTime | integer <int64> (EpochTimestamp) >= 0 Example: maxLastUpdatedTime=1730204346000 The number of milliseconds since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| externalIdPrefix | string (CogniteExternalIdPrefix) <= 255 characters Example: externalIdPrefix=my.known.prefix Filter by this (case-sensitive) prefix for the external ID. |
| partition | string Example: partition=1/3 Splits the data set into The maximum number of allowed partitions ( Cognite rejects requests if you specify more than 10 partitions. When Cognite enforces this behavior, the requests result in a 400 Bad Request status. |
| includeMetadata | boolean Default: true Whether the metadata field should be returned or not. |
| sort | Array of strings Example: sort=endTime:desc Sort by an array of the selected fields. Syntax: |
Responses
Request samples
- JavaScript SDK
- Python SDK
const events = await client.events.list({ filter: { startTime: { min: new Date('1 jan 2018') }, endTime: { max: new Date('1 jan 2019') } } });
Response samples
- 200
- 400
- 429
{- "items": [
- {
- "externalId": "my.known.id",
- "dataSetId": 1,
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "type": "string",
- "subtype": "string",
- "description": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "source": "string",
- "id": 1,
- "lastUpdatedTime": 1730204346000,
- "createdTime": 1730204346000
}
], - "nextCursor": "string"
}Receive an event by its ID
Retrieves an event by its internal (service-generated) ID.
Request throttling
This endpoint is a subject of the new throttling schema (limited request rate and concurrency). Please check Events resource description for more information.
Authorizations:
path Parameters
| id required | integer <int64> (CogniteInternalId) [ 1 .. 9007199254740991 ] A server-generated ID for the object. |
Responses
Request samples
- JavaScript SDK
- Python SDK
const events = await client.events.retrieve([{id: 123}, {externalId: 'abc'}]);
Response samples
- 200
- 400
- 429
{- "externalId": "my.known.id",
- "dataSetId": 1,
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "type": "string",
- "subtype": "string",
- "description": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "source": "string",
- "id": 1,
- "lastUpdatedTime": 1730204346000,
- "createdTime": 1730204346000
}Retrieve events
Retrieves information about events in the same project. Events are returned in the same order as the ids listed in the query.
A maximum of 1000 event IDs may be listed per request and all of them must be unique.
Request throttling
This endpoint is a subject of the new throttling schema (limited request rate and concurrency). Please check Events resource description for more information.
Authorizations:
Request Body schema: application/jsonrequired
List of IDs of events to retrieve. Must be up to a maximum of 1000 IDs, and all of them must be unique.
required | Array of InternalId (object) or ExternalId (object) (EitherId) [ 1 .. 1000 ] items |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1
}
], - "ignoreUnknownIds": false
}Response samples
- 200
- 400
- 429
{- "items": [
- {
- "externalId": "my.known.id",
- "dataSetId": 1,
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "type": "string",
- "subtype": "string",
- "description": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "source": "string",
- "id": 1,
- "lastUpdatedTime": 1730204346000,
- "createdTime": 1730204346000
}
]
}Search events
Fulltext search for events based on result relevance. Primarily meant for human-centric use-cases, not for programs, since matching and ordering may change over time. Additional filters can also be specified. This operation doesn't support pagination.
Request throttling
This endpoint is meant for data analytics/exploration usage and is not suitable for high load data retrieval usage. It is a subject of the new throttling schema (limited request rate and concurrency). Please check Events resource description for more information.
Authorizations:
Request Body schema: application/json
object (EventFilter) Filter on events filter with exact match | |
object (EventSearch) | |
| limit | integer <int32> [ 1 .. 1000 ] Default: 100 <- Limits the maximum number of results to be returned by single request. Request may contain less results than request limit. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
{- "filter": {
- "startTime": {
- "max": 0,
- "min": 0
}, - "endTime": {
- "max": 0,
- "min": 0
}, - "activeAtTime": {
- "max": 0,
- "min": 0
}, - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "assetExternalIds": [
- "my.known.id"
], - "assetSubtreeIds": [
- {
- "id": 1
}
], - "dataSetId": {
- "in": [
- {
- "id": 123
}, - {
- "externalId": "my.known.id"
}
], - "isNull": true
}, - "dataSetIds": [
- {
- "id": 1
}
], - "source": "string",
- "type": "string",
- "subtype": "string",
- "createdTime": {
- "max": 0,
- "min": 0
}, - "lastUpdatedTime": {
- "max": 0,
- "min": 0
}, - "externalIdPrefix": "my.known.prefix"
}, - "search": {
- "description": "string"
}, - "limit": 100
}Response samples
- 200
- 400
- 429
{- "items": [
- {
- "externalId": "my.known.id",
- "dataSetId": 1,
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "type": "string",
- "subtype": "string",
- "description": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "source": "string",
- "id": 1,
- "lastUpdatedTime": 1730204346000,
- "createdTime": 1730204346000
}
]
}Update events
Updates events in the same project. This operation supports partial updates; Fields omitted from queries will remain unchanged on objects.
For primitive fields (String, Long, Int), use 'set': 'value' to update value; use 'setNull': true to set that field to null.
For the Json Array field (e.g. assetIds), use 'set': [value1, value2] to update value; use 'add': [v1, v2] to add values to current list of values; use 'remove': [v1, v2] to remove these values from current list of values if exists.
A maximum of 1000 events can be updated per request, and all of the event IDs must be unique.
Request throttling
This endpoint is a subject of the new throttling schema (limited request rate and concurrency). Please check Events resource description for more information.
Authorizations:
Request Body schema: application/jsonrequired
List of changes. A maximum of 1000 events can be updated per request, and all of the event IDs must be unique.
required | Array of EventChangeById (object) or EventChangeByExternalId (object) (EventChange) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "update": {
- "externalId": {
- "set": "my.known.id"
}, - "dataSetId": {
- "set": 0
}, - "startTime": {
- "set": 0
}, - "endTime": {
- "set": 0
}, - "description": {
- "set": "string"
}, - "metadata": {
- "set": {
- "key1": "value1",
- "key2": "value2"
}
}, - "assetIds": {
- "set": [
- 0
]
}, - "source": {
- "set": "string"
}, - "type": {
- "set": "string"
}, - "subtype": {
- "set": "string"
}
}, - "id": 1
}
]
}Response samples
- 200
- 400
- 429
{- "items": [
- {
- "externalId": "my.known.id",
- "dataSetId": 1,
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "type": "string",
- "subtype": "string",
- "description": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "source": "string",
- "id": 1,
- "lastUpdatedTime": 1730204346000,
- "createdTime": 1730204346000
}
]
}A file stores a sequence of bytes connected to one or more assets. For example, a file can contain a piping and instrumentation diagram (P&IDs) showing how multiple assets are connected.
Each file is identified by the 'id' field, which is generated internally for each new file. Each file's 'id' field is unique within a project.
The 'externalId' field is optional, but can also be used to identify a file. The 'externalId' (if used) must be unique within a project.
Files are created in two steps; First the metadata is stored in a file object, and then the file contents are uploaded. This means that files can exist in a non-uploaded state. The upload state is reflected in the 'uploaded' field in responses.
Asset references obtained from a file - through asset ids - may be invalid, simply by the non-transactional nature of HTTP. They are maintained in an eventual consistent manner.
Both the rate of requests (denoted as request per second, or ‘rps’) and the number of concurrent (parallel) requests are governed by limits,
for all CDF API endpoints. If a request exceeds one of the limits,
it will be throttled with a 429: Too Many Requests response. More on limit types
and how to avoid being throttled is described
here.
Limits are defined at both the overall API service level, and on the API endpoints belonging to the service. Some types of requests consume more resources (compute, storage IO) than others, and where a service handles multiple concurrent requests with varying resource consumption. For example, ‘CRUD’ type requests (Create, Retrieve, Request ByIDs, Update and Delete and similar) are far less resource intensive than ‘Analytical’ type requests (List, Search and Filter) and in addition, the most resource intensive Analytical endpoint of all, Aggregates, receives its own request budget within the overall Analytical request budget. The version 1.0 limits for the overall API service and its constituent endpoints are illustrated in the diagram below. These limits are subject to change, pending review of changing consumption patterns and resource availability over time:
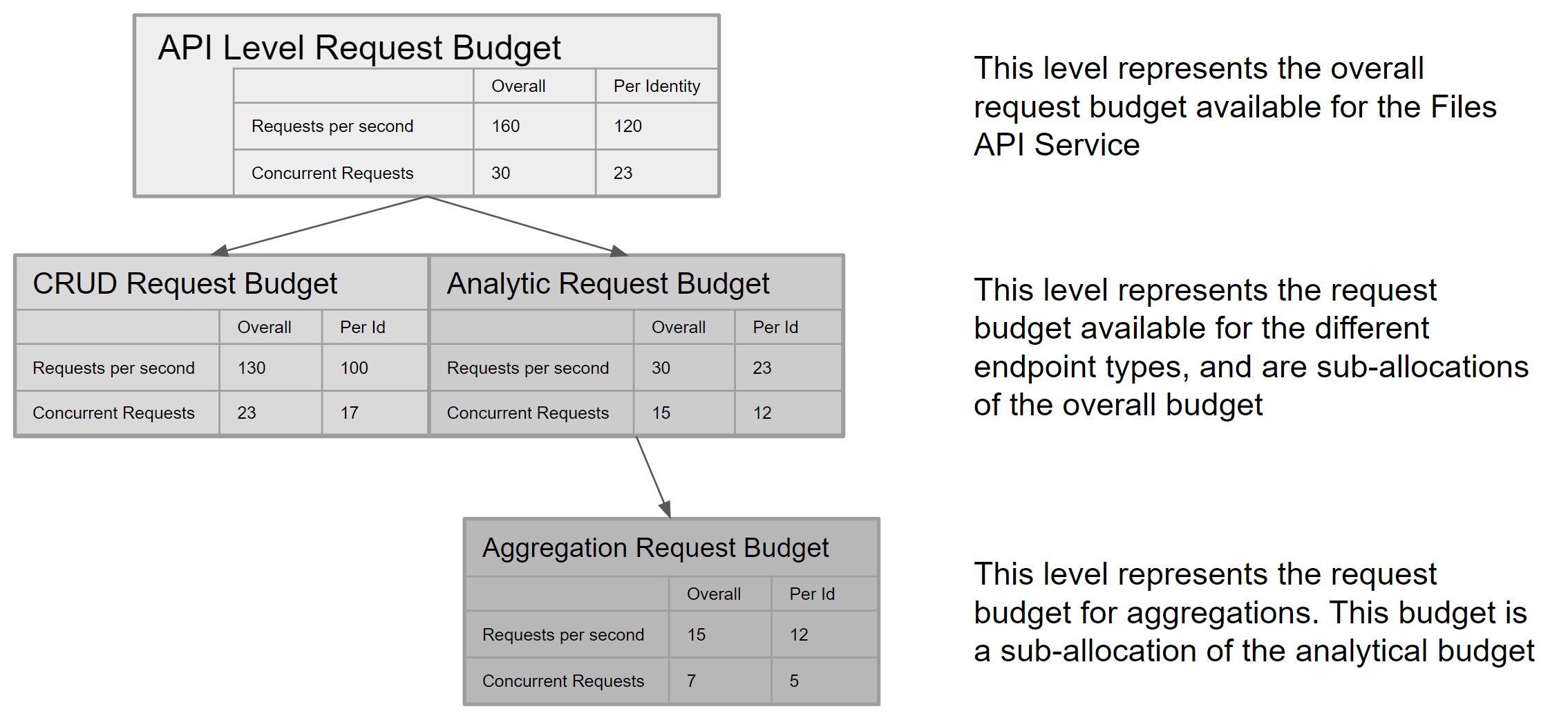
Translating RPS into data speed
A single request may retrieve up to 1000 items. In the context of Files, 1 item = 1 file record Therefore, the maximum theoretical data speed at the top API service level is 160,000 items per second for all consumers, and 120,000 for a single identity or client in a project.
Use of Partitions / Parallel Retrieval
As a general guidance, Parallel Retrieval is a technique that should be used where due to query complexity, retrieval of data in a single request session turns out to be slow. By parallelizing such requests, data retrieval performance can be tuned to meet the client application needs. Parallel retrieval may also be used where retrieval of large sets of data is required, up to the capacity limits defined for a given API service. For example (using the Files API request budget):
- A single request may retrieve up to 1000 items
- Up to 23 requests per second may be issued for an analytical query (per identity), such as when using /list or /filter API endpoints
- This provides a theoretical maximum of 23,000 items read per second per identity
- The query complexity may result in it taking longer than 1s to read or write 1000 items in a single request
- Therefore, it is appropriate to specify the query to retrieve a lower number of items per request, and retrieve more items in parallel, up to the theoretical maximum performance of 23,000 items per second.
Important Note: Parallel retrieval should be only used in situations where, due to query complexity, a single request flow provides data retrieval speeds that are significantly less than the theoretical maximum. Parallel retrieval does not act as a speed multiplier on optimally running queries. Regardless of the number of concurrent requests issued, the overall requests per second limit still applies. So for example, a single request returning data at approximately 18,000 items per second will only benefit from adding a second parallel request, the capacity of which goes somewhat wasted as only an additional 5,000 items per second will return before the request rate budget limit is reached.
Aggregate files
Calculate aggregates for files, based on optional filter specification.
Returns the following aggregates: count
Request throttling
This endpoint is intended for data analytics and exploration purposes. It is not designed to support high-throughput data retrieval. Please note that this endpoint is subject to the new throttling policy, which imposes limits on both request rate and concurrency. For more details, please refer to the Files resource documentation.
Authorizations:
Request Body schema: application/jsonrequired
Files aggregate request body
object |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "filter": {
- "name": "string",
- "directoryPrefix": "/my/known/directory",
- "mimeType": "image/jpeg",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 363848954441724,
- 793045462540095,
- 1261042166839739
], - "assetExternalIds": [
- "externalId1",
- "externalId2",
- "externalId3"
], - "rootAssetIds": [
- {
- "id": 123456789
}, - {
- "externalId": "system 99 external Id 1234"
}
], - "dataSetIds": [
- {
- "id": 1
}
], - "assetSubtreeIds": [
- {
- "id": 123456789
}, - {
- "externalId": "system 99 external Id 1234"
}
], - "source": "string",
- "createdTime": {
- "max": 0,
- "min": 0
}, - "lastUpdatedTime": {
- "max": 0,
- "min": 0
}, - "uploadedTime": {
- "max": 0,
- "min": 0
}, - "sourceCreatedTime": {
- "max": 0,
- "min": 0
}, - "sourceModifiedTime": {
- "max": 0,
- "min": 0
}, - "externalIdPrefix": "my.known.prefix",
- "space": "string",
- "instanceExternalIdPrefix": "my.known.prefix",
- "pendingInstanceSpace": "string",
- "pendingInstanceExternalIdPrefix": "my.known.prefix",
- "uploaded": true,
- "labels": {
- "containsAny": [
- {
- "externalId": "my.known.id"
}
]
}, - "geoLocation": {
- "relation": "INTERSECTS",
- "shape": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}
}
}
}Response samples
- 200
- 400
{- "items": [
- {
- "count": 0
}
]
}Complete multipart upload
Completes a multipart file upload.
This endpoint must be called by the client when an 'initMultiPartUpload' operation (POST /files/initmultipartupload) was called,
and all file content parts have been successfully uploaded using PUT for all upload URLs.
Either id or externalId must be specified in the request body, but not both. The uploadId is also required.
The values for these properties can be retrieved from the response of the initMultiPartUpload operation.
Request throttling
Please note that this endpoint is subject to the new throttling policy, which imposes limits on both request rate and concurrency. For more details, please refer to the Files resource documentation.
Authorizations:
Request Body schema: application/jsonrequired
The JSON request body which specifies which file id/externalId and uploadId to complete the multipart upload for.
| id | integer <int64> (CogniteInternalId) [ 1 .. 9007199254740991 ] A server-generated ID for the object. |
| uploadId required | string A server-generated identifier returned by 'files/initmultipartupload', used by 'files/completemultipartupload' for validation purposes. |
Responses
Request samples
- Payload
{- "id": 1,
- "uploadId": "string"
}Response samples
- 200
- 400
{ }Delete files
Deletes the files with the given ids.
A maximum of 1000 files can be deleted per request.
Request throttling
Please note that this endpoint is subject to the new throttling policy, which imposes limits on both request rate and concurrency. For more details, please refer to the Files resource documentation.
Authorizations:
Request Body schema: application/jsonrequired
List of IDs of files to delete.
required | Array of FileInternalId (object) or FileExternalId (object) (FileDeleteByIdEither) [ 1 .. 1000 ] items |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1
}
], - "ignoreUnknownIds": false
}Response samples
- 200
- 400
{ }Download files
Retrieves a list of download URLs for the specified list of file IDs. After getting the download links, the client has to issue a GET request to the returned URLs, which will respond with the contents of the file. The links will by default expire after 30 seconds. If providing the query parameter extendedExpiration the links will expire after 1 hour.
Request throttling
Please note that this endpoint is subject to the new throttling policy, which imposes limits on both request rate and concurrency. For more details, please refer to the Files resource documentation.
Authorizations:
query Parameters
| extendedExpiration | boolean Default: false if set to true, will extend the expiration period of the link to 1 hour. |
Request Body schema: application/jsonrequired
List of file IDs to retrieve the download URL for.
Array of FileInternalId (object) or FileExternalId (object) or FileInstanceId (object) (FileIdEither) [ 1 .. 100 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "downloadUrl": "string",
- "id": 1
}
]
}Filter files
Retrieves a list of all files in a project. Criteria can be supplied to select a subset of files. This operation supports pagination with cursors.
Request throttling
This endpoint is intended for data analytics and exploration purposes. It is not designed to support high-throughput data retrieval. Please note that this endpoint is subject to the new throttling policy, which imposes limits on both request rate and concurrency. For more details, please refer to the Files resource documentation.
Authorizations:
Request Body schema: application/jsonrequired
The project name
object | |
| partition | string (PartitionLimited10) Splits the data set into The maximum number of allowed partitions ( Cognite rejects requests if you specify more than 10 partitions. When Cognite enforces this behavior, the requests result in a 400 Bad Request status. |
| limit | integer <int32> [ 1 .. 1000 ] Default: 100 <- Maximum number of items that the client want to get back. |
| cursor | string |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "filter": {
- "name": "string",
- "directoryPrefix": "/my/known/directory",
- "mimeType": "image/jpeg",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 363848954441724,
- 793045462540095,
- 1261042166839739
], - "assetExternalIds": [
- "externalId1",
- "externalId2",
- "externalId3"
], - "rootAssetIds": [
- {
- "id": 123456789
}, - {
- "externalId": "system 99 external Id 1234"
}
], - "dataSetIds": [
- {
- "id": 1
}
], - "assetSubtreeIds": [
- {
- "id": 123456789
}, - {
- "externalId": "system 99 external Id 1234"
}
], - "source": "string",
- "createdTime": {
- "max": 0,
- "min": 0
}, - "lastUpdatedTime": {
- "max": 0,
- "min": 0
}, - "uploadedTime": {
- "max": 0,
- "min": 0
}, - "sourceCreatedTime": {
- "max": 0,
- "min": 0
}, - "sourceModifiedTime": {
- "max": 0,
- "min": 0
}, - "externalIdPrefix": "my.known.prefix",
- "space": "string",
- "instanceExternalIdPrefix": "my.known.prefix",
- "pendingInstanceSpace": "string",
- "pendingInstanceExternalIdPrefix": "my.known.prefix",
- "uploaded": true,
- "labels": {
- "containsAny": [
- {
- "externalId": "my.known.id"
}
]
}, - "geoLocation": {
- "relation": "INTERSECTS",
- "shape": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}
}
}, - "partition": "1/3",
- "limit": 100,
- "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo"
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "directory": "string",
- "source": "string",
- "mimeType": "image/jpeg",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "dataSetId": 1,
- "sourceCreatedTime": 1730204346000,
- "sourceModifiedTime": 1730204346000,
- "securityCategories": [
- 1
], - "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1,
- "uploaded": true,
- "uploadedTime": 1730204346000,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "pendingInstanceId": {
- "space": "string",
- "externalId": "string"
}
}
], - "nextCursor": "string"
}Get icon
The GET /files/icon operation can be used to get an image representation of a file.
Either id or externalId must be provided as a query parameter (but not both). Supported file formats:
- Normal jpeg and png files are currently fully supported.
- Other image file formats might work, but continued support for these are not guaranteed.
- Currently only supporting thumbnails for image files. Attempts to get icon for unsupported files will result in status 400.
Request throttling
Please note that this endpoint is subject to the new throttling policy, which imposes limits on both request rate and concurrency. For more details, please refer to the Files resource documentation.
Authorizations:
query Parameters
| id | integer <int64> (CogniteInternalId) [ 1 .. 9007199254740991 ] A server-generated ID for the object. |
| externalId | string (CogniteExternalId) <= 255 characters Example: externalId=my.known.id The external ID provided by the client. Must be unique for the resource type. |
| space | string (InstanceSpace) [ 1 .. 43 ] characters ^[a-zA-Z][a-zA-Z0-9_-]{0,41}[a-zA-Z0-9]?$ |
| instanceExternalId | string (InstanceExternalId) [ 1 .. 255 ] characters ^[a-zA-Z]([a-zA-Z0-9_]{0,253}[a-zA-Z0-9])?$ |
Responses
Response samples
- 400
{- "error": {
- "code": 401,
- "message": "Could not authenticate.",
- "missing": [
- { }
], - "duplicated": [
- { }
]
}
}Get multipart file upload link
Multipart file upload enables upload of files larger than 5 GiB, using a uniform API on all cloud environments for CDF.
Each file part must be larger than 5 MiB, and smaller than 4000 MiB. The file part for the last uploadURL can be smaller than 5 MiB. Maximum 250 upload URLs can be requested.
The supported maximum size for each file uploaded with the multi-part upload API is therefore 1000 GiB (1.073 TB / 0.976 TiB).
The client should calculate the ideal number of parts depending on predetermined or estimated file size, between 1 and the maximum.
Specify the number of parts in the parts URL query parameter. The parts parameter is required.
The request returns in addition to the file id, also a uploadId, and a list of uploadUrls for uploading the file contents.
To upload a file, send an HTTP PUT request to each of the uploadUrls, with the corresponding part of the file in the request body.
You may use a 'Content-Length' header in the PUT request for each part, but this is not required.
A failed part PUT upload can be retried.
The client must ensure that the parts of the source file are stored in the correct order, using the order of the uploadUrls as specified in the response.
This to avoid ending up with a corrupt final file.
The parts can optionally be uploaded in parallel, preferably on a subset of parts at a time, for example maximum 3 concurrent PUT operations.
Once all file parts have been uploaded, the client should call the 'files/completemultipartupload' endpoint,
with the required file ID (as id or externalId) and uploadId fields in the request body. This will assemble the parts into one file.
The file's uploaded flag will then eventually be set to true.
A standard sequence of calls to upload a large file with multipart upload would be for example as follows:
- POST files/initmultipartupload?parts=8, to start a multipart upload session with 8 parts. Expect a 201 CREATED response code, and a response body with information to be used in the part uploads and completemultipartupload requests.
- PUT
uploadUrl, for each of theuploadUrlsin the response from files/initmultipartupload. Expect a 200 OK or 201 CREATED response for each PUT request. - POST files/completemultipartupload, with request body '{ "id":123456789, "uploadId":"ABCD4321EFGH" }'. This will assemble the file. Expect a 200 OK response.
Consider verifying that the file is eventually marked as uploaded with a call to the getFileByInternalId endpoint.
NOTE: The uploadUrls expires after one week. A file that does not have the file content parts uploaded and completed within one week will be automatically deleted.
Request throttling
Please note that this endpoint is subject to the new throttling policy, which imposes limits on both request rate and concurrency. For more details, please refer to the Files resource documentation.
Authorizations:
query Parameters
| parts required | integer <int32> [ 1 .. 250 ] The 'parts' parameter specifies how many uploadURLs should be returned, for uploading the file contents in parts. See main endpoint description for more details. |
Request Body schema: application/jsonrequired
Fields to be set for the file.
required | Array of FileExternalId (object) or FileInstanceId (object) (FileExternalIdEither) = 1 items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
]
}Response samples
- 201
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "directory": "string",
- "source": "string",
- "mimeType": "image/jpeg",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "dataSetId": 1,
- "sourceCreatedTime": 1730204346000,
- "sourceModifiedTime": 1730204346000,
- "securityCategories": [
- 1
], - "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1,
- "uploaded": true,
- "uploadedTime": 1730204346000,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "pendingInstanceId": {
- "space": "string",
- "externalId": "string"
}, - "uploadId": "string",
- "uploadUrls": [
- "uploadURL_for_part_1",
- "uploadURL_for_part_2",
- "uploadURL_for_part_3"
]
}
]
}Get upload file link
Get an uploadUrl for a file.
To upload the file, send an HTTP PUT request to the uploadUrl from the response, with the relevant 'Content-Type' and 'Content-Length' headers.
If the uploadUrl contains the string '/v1/files/gcs_proxy/', you can make a Google Cloud Storage (GCS) resumable upload request as documented in https://cloud.google.com/storage/docs/json_api/v1/how-tos/resumable-upload.
The uploadUrl expires after one week. Any file info entry that does not have the actual file uploaded within one week will be automatically deleted.
Note: The uploadUrl from getUploadLink supports files smaller than 5 GiB.
The getMultiPartUploadLink and completeMultiPartUpload endpoints provides an alternative way to upload files, both small and large, up to 1 TiB in size. These endpoints exposes a uniform multipart upload API for all cloud vendor environments for CDF. Optionally parallel part uploads can be used, for faster uploads.
Request throttling
Please note that this endpoint is subject to the new throttling policy, which imposes limits on both request rate and concurrency. For more details, please refer to the Files resource documentation.
Authorizations:
header Parameters
| Origin | string The 'Origin' header parameter is required if there is a Cross Origin issue. |
Request Body schema: application/jsonrequired
Fields to be set for the file.
required | Array of FileExternalId (object) or FileInstanceId (object) (FileExternalIdEither) = 1 items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
]
}Response samples
- 201
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "directory": "string",
- "source": "string",
- "mimeType": "image/jpeg",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "dataSetId": 1,
- "sourceCreatedTime": 1730204346000,
- "sourceModifiedTime": 1730204346000,
- "securityCategories": [
- 1
], - "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1,
- "uploaded": true,
- "uploadedTime": 1730204346000,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "pendingInstanceId": {
- "space": "string",
- "externalId": "string"
}, - "uploadUrl": "string"
}
]
}List files
The GET /files operation can be used to return information for all files in a project.
Optionally you can add one or more of the following query parameters. The filter query parameters will filter the results to only include files that match all filter parameters.
Request throttling
This endpoint is intended for data analytics and exploration purposes. It is not designed to support high-throughput data retrieval. Please note that this endpoint is subject to the new throttling policy, which imposes limits on both request rate and concurrency. For more details, please refer to the Files resource documentation.
Authorizations:
query Parameters
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 1000 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| name | string (FileName) <= 256 characters Name of the file. |
| mimeType | string (MimeType) <= 256 characters Example: mimeType=image/jpeg File type. E.g. text/plain, application/pdf, .. |
| source | string (FileSource) <= 128 characters The source of the file. |
| assetIds | Array of integers <int64> (AssetIds) [ 1 .. 100 ] items unique [ items <int64 > [ 1 .. 9007199254740991 ] ] Example: assetIds=363848954441724&assetIds=793045462540095&assetIds=1261042166839739 Only include files that reference these specific asset IDs. |
| assetExternalIds | string <jsonArray(string)> (JsonArrayString) Example: assetExternalIds=["externalId1", "externalId2", "externalId3"] Asset external IDs of related equipment that this file relates to. Takes 1..100 unique items. |
Array of DataSetInternalId (object) or DataSetExternalId (object) (DataSetIdEithers) | |
| rootAssetIds | string <jsonArray(int64)> (JsonArrayInt64) Example: rootAssetIds=[363848954441724, 793045462540095, 1261042166839739] Only include files that have a related asset in a tree rooted at any of these root assetIds. |
| assetSubtreeIds | string <jsonArray(int64)> (JsonArrayInt64) Example: assetSubtreeIds=[363848954441724, 793045462540095, 1261042166839739] Only include files that have a related asset in a subtree rooted at any of these assetIds (including the roots given). If the total size of the given subtrees exceeds 100,000 assets, an error will be returned. |
| assetSubtreeExternalIds | string <jsonArray(string)> (JsonArrayString) Example: assetSubtreeExternalIds=["externalId1", "externalId2", "externalId3"] Only include files that have a related asset in a subtree rooted at any of these assetExternalIds (including the roots given). If the total size of the given subtrees exceeds 100,000 assets, an error will be returned. |
| minCreatedTime | integer <int64> (EpochTimestamp) >= 0 Example: minCreatedTime=1730204346000 The number of milliseconds since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| maxCreatedTime | integer <int64> (EpochTimestamp) >= 0 Example: maxCreatedTime=1730204346000 The number of milliseconds since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| minLastUpdatedTime | integer <int64> (EpochTimestamp) >= 0 Example: minLastUpdatedTime=1730204346000 The number of milliseconds since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| maxLastUpdatedTime | integer <int64> (EpochTimestamp) >= 0 Example: maxLastUpdatedTime=1730204346000 The number of milliseconds since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| minUploadedTime | integer <int64> (EpochTimestamp) >= 0 Example: minUploadedTime=1730204346000 The number of milliseconds since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| maxUploadedTime | integer <int64> (EpochTimestamp) >= 0 Example: maxUploadedTime=1730204346000 The number of milliseconds since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| minSourceCreatedTime | integer <int64> (EpochTimestamp) >= 0 Example: minSourceCreatedTime=1730204346000 Include files that have sourceCreatedTime set and with minimum this value. |
| maxSourceCreatedTime | integer <int64> (EpochTimestamp) >= 0 Example: maxSourceCreatedTime=1730204346000 Include files that have sourceCreatedTime set and with maximum this value. |
| minSourceModifiedTime | integer <int64> (EpochTimestamp) >= 0 Example: minSourceModifiedTime=1730204346000 Include files that have sourceModifiedTime set and with minimum this value. |
| maxSourceModifiedTime | integer <int64> (EpochTimestamp) >= 0 Example: maxSourceModifiedTime=1730204346000 Include files that have sourceModifiedTime set and with maximum this value. |
| externalIdPrefix | string (CogniteExternalIdPrefix) <= 255 characters Example: externalIdPrefix=my.known.prefix Filter by this (case-sensitive) prefix for the external ID. |
| space | string (InstanceSpace) [ 1 .. 43 ] characters ^[a-zA-Z][a-zA-Z0-9_-]{0,41}[a-zA-Z0-9]?$ |
| instanceExternalIdPrefix | string (CogniteExternalIdPrefix) <= 255 characters Example: instanceExternalIdPrefix=my.known.prefix Filter by this (case-sensitive) prefix for the external ID. |
| pendingInstanceSpace | string (InstanceSpace) [ 1 .. 43 ] characters ^[a-zA-Z][a-zA-Z0-9_-]{0,41}[a-zA-Z0-9]?$ |
| pendingInstanceExternalIdPrefix | string (CogniteExternalIdPrefix) <= 255 characters Example: pendingInstanceExternalIdPrefix=my.known.prefix Filter by this (case-sensitive) prefix for the external ID. |
| uploaded | boolean Example: uploaded=true Whether or not the actual file is uploaded. This field is returned only by the API, it has no effect in a post body. |
| partition | string Example: partition=1/3 Splits the data set into The maximum number of allowed partitions ( Cognite rejects requests if you specify more than 10 partitions. When Cognite enforces this behavior, the requests result in a 400 Bad Request status. |
Responses
Request samples
- JavaScript SDK
- Python SDK
const files = await client.files.list({filter: {mimeType: 'image/png'}});
Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "directory": "string",
- "source": "string",
- "mimeType": "image/jpeg",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "dataSetId": 1,
- "sourceCreatedTime": 1730204346000,
- "sourceModifiedTime": 1730204346000,
- "securityCategories": [
- 1
], - "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1,
- "uploaded": true,
- "uploadedTime": 1730204346000,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "pendingInstanceId": {
- "space": "string",
- "externalId": "string"
}
}
], - "nextCursor": "string"
}Retrieve a file by its ID
Returns file info for the file ID
Request throttling
Please note that this endpoint is subject to the new throttling policy, which imposes limits on both request rate and concurrency. For more details, please refer to the Files resource documentation.
Authorizations:
path Parameters
| id required | integer <int64> (CogniteInternalId) [ 1 .. 9007199254740991 ] A server-generated ID for the object. |
Responses
Request samples
- JavaScript SDK
- Python SDK
const files = await client.files.retrieve([{id: 123}, {externalId: 'abc'}]);
Response samples
- 200
- 400
{- "externalId": "my.known.id",
- "name": "string",
- "directory": "string",
- "source": "string",
- "mimeType": "image/jpeg",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "dataSetId": 1,
- "sourceCreatedTime": 1730204346000,
- "sourceModifiedTime": 1730204346000,
- "securityCategories": [
- 1
], - "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1,
- "uploaded": true,
- "uploadedTime": 1730204346000,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "pendingInstanceId": {
- "space": "string",
- "externalId": "string"
}
}Retrieve files
Retrieves metadata information about multiple specific files in the same project. Results are returned in the same order as in the request. This operation does not return the file contents.
Request throttling
Please note that this endpoint is subject to the new throttling policy, which imposes limits on both request rate and concurrency. For more details, please refer to the Files resource documentation.
Authorizations:
Request Body schema: application/jsonrequired
List of IDs of files to retrieve. Must be up to a maximum of 1000 IDs, and all of them must be unique.
required | Array of Select by Id (object) or Select by ExternalId (object) or Select by InstanceId (object) (FileSelectEither) [ 1 .. 1000 ] items |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1
}
], - "ignoreUnknownIds": false
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "directory": "string",
- "source": "string",
- "mimeType": "image/jpeg",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "dataSetId": 1,
- "sourceCreatedTime": 1730204346000,
- "sourceModifiedTime": 1730204346000,
- "securityCategories": [
- 1
], - "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1,
- "uploaded": true,
- "uploadedTime": 1730204346000,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "pendingInstanceId": {
- "space": "string",
- "externalId": "string"
}
}
]
}Search files
Search for files based on relevance. You can also supply a strict match filter as in Filter files, and search in the results from the filter. Returns first 1000 results based on relevance. This operation does not support pagination.
Request throttling
This endpoint is intended for data analytics and exploration purposes. It is not designed to support high-throughput data retrieval. Please note that this endpoint is subject to the new throttling policy, which imposes limits on both request rate and concurrency. For more details, please refer to the Files resource documentation.
Authorizations:
Request Body schema: application/json
object | |
object |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
{- "filter": {
- "name": "string",
- "directoryPrefix": "/my/known/directory",
- "mimeType": "image/jpeg",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 363848954441724,
- 793045462540095,
- 1261042166839739
], - "assetExternalIds": [
- "externalId1",
- "externalId2",
- "externalId3"
], - "rootAssetIds": [
- {
- "id": 123456789
}, - {
- "externalId": "system 99 external Id 1234"
}
], - "dataSetIds": [
- {
- "id": 1
}
], - "assetSubtreeIds": [
- {
- "id": 123456789
}, - {
- "externalId": "system 99 external Id 1234"
}
], - "source": "string",
- "createdTime": {
- "max": 0,
- "min": 0
}, - "lastUpdatedTime": {
- "max": 0,
- "min": 0
}, - "uploadedTime": {
- "max": 0,
- "min": 0
}, - "sourceCreatedTime": {
- "max": 0,
- "min": 0
}, - "sourceModifiedTime": {
- "max": 0,
- "min": 0
}, - "externalIdPrefix": "my.known.prefix",
- "space": "string",
- "instanceExternalIdPrefix": "my.known.prefix",
- "pendingInstanceSpace": "string",
- "pendingInstanceExternalIdPrefix": "my.known.prefix",
- "uploaded": true,
- "labels": {
- "containsAny": [
- {
- "externalId": "my.known.id"
}
]
}, - "geoLocation": {
- "relation": "INTERSECTS",
- "shape": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}
}
}, - "search": {
- "name": "string"
}
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "directory": "string",
- "source": "string",
- "mimeType": "image/jpeg",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "dataSetId": 1,
- "sourceCreatedTime": 1730204346000,
- "sourceModifiedTime": 1730204346000,
- "securityCategories": [
- 1
], - "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1,
- "uploaded": true,
- "uploadedTime": 1730204346000,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "pendingInstanceId": {
- "space": "string",
- "externalId": "string"
}
}
]
}Update files
Updates the information for the files specified in the request body.
If you want to update the file content, uploaded using the uploadUrl, please use the initFileUpload request with the query parameter 'overwrite=true'. Alternatively, delete and recreate the file.
For primitive fields (String, Long, Int), use 'set': 'value' to update value; use 'setNull': true to set that field to null.
For the Json Array field (e.g. assetIds and securityCategories): Use either only 'set', or a combination of 'add' and/or 'remove'.
AssetIds update examples:
Example request body to overwrite assetIds with a new set, asset ID 1 and 2.
{
"items": [
{
"id": 1,
"update": {
"assetIds" : {
"set" : [ 1, 2 ]
}
}
}
]
}
Example request body to add one asset Id, and remove another asset ID.
{
"items": [
{
"id": 1,
"update": {
"assetIds" : {
"add" : [ 3 ],
"remove": [ 2 ]
}
}
}
]
}
Metadata update examples:
Example request body to overwrite metadata with a new set.
{
"items": [
{
"id": 1,
"update": {
"metadata": {
"set": {
"key1": "value1",
"key2": "value2"
}
}
}
}
]
}
Example request body to add two key-value pairs and remove two other key-value pairs by key for the metadata field.
{
"items": [
{
"id": 1,
"update": {
"metadata": {
"add": {
"key3": "value3",
"key4": "value4"
},
"remove": [
"key1",
"key2"
]
}
}
}
]
}
Request throttling
Please note that this endpoint is subject to the new throttling policy, which imposes limits on both request rate and concurrency. For more details, please refer to the Files resource documentation.
Authorizations:
Request Body schema: application/jsonrequired
The JSON request body which specifies which files and fields to update.
required | Array of FileChangeUpdateById (object) or FileChangeUpdateByExternalId (object) or FileChangeUpdateByInstanceId (object) (FileChangeUpdate) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1,
- "update": {
- "externalId": {
- "set": "string"
}, - "directory": {
- "set": "string"
}, - "source": {
- "set": "string"
}, - "mimeType": {
- "set": "string"
}, - "metadata": {
- "set": {
- "key1": "value1",
- "key2": "value2"
}
}, - "assetIds": {
- "set": [
- 0
]
}, - "sourceCreatedTime": {
- "set": 0
}, - "sourceModifiedTime": {
- "set": 0
}, - "dataSetId": {
- "set": 0
}, - "securityCategories": {
- "set": [
- 0
]
}, - "labels": {
- "add": [
- {
- "externalId": "my.known.id"
}
], - "remove": [
- {
- "externalId": "my.known.id"
}
]
}, - "geoLocation": {
- "set": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}
}
}
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "directory": "string",
- "source": "string",
- "mimeType": "image/jpeg",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "dataSetId": 1,
- "sourceCreatedTime": 1730204346000,
- "sourceModifiedTime": 1730204346000,
- "securityCategories": [
- 1
], - "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1,
- "uploaded": true,
- "uploadedTime": 1730204346000,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "pendingInstanceId": {
- "space": "string",
- "externalId": "string"
}
}
]
}Upload file
Create metadata information and get an uploadUrl for a file.
To upload the file, send an HTTP PUT request to the uploadUrl from the response, with the relevant 'Content-Type' and 'Content-Length' headers.
If the uploadUrl contains the string '/v1/files/gcs_proxy/', you can make a Google Cloud Storage (GCS) resumable upload request as documented in https://cloud.google.com/storage/docs/json_api/v1/how-tos/resumable-upload.
The uploadUrl expires after one week. Any file info entry that does not have the actual file uploaded within one week will be automatically deleted.
Note: The uploadUrl from initFileUpload supports files smaller than 5 GiB.
The initMultiPartUpload and completeMultiPartUpload endpoints provides an alternative way to upload files, both small and large, up to 1 TiB in size. These endpoints exposes a uniform multipart upload API for all cloud vendor environments for CDF. Optionally parallel part uploads can be used, for faster uploads.
Request throttling
This endpoint is subject to the new throttling policy, which enforces limits on both request rate and concurrency. For more details, please refer to the Files resource documentation.
Authorizations:
query Parameters
| overwrite | boolean Default: false If 'overwrite' is set to true, and the POST body content specifies a 'externalId' field, fields for the file found for externalId can be overwritten. The default setting is false. If metadata is included in the request body, all of the original metadata will be overwritten. The actual file will be overwritten after a successful upload with the uploadUrl from the response. If there is no successful upload, the current file contents will be kept. File-Asset mappings only change if explicitly stated in the assetIds field of the POST json body. Do not set assetIds in request body if you want to keep the current file-asset mappings. |
header Parameters
| Origin | string The 'Origin' header parameter is required if there is a Cross Origin issue. |
Request Body schema: application/jsonrequired
Fields to be set for the file.
| externalId | string (CogniteExternalId) <= 255 characters The external ID provided by the client. Must be unique for the resource type. |
| name required | string (FileName) <= 256 characters Name of the file. |
| directory | string (FileDirectory) <= 512 characters Directory containing the file. Must be an absolute, unix-style path. |
| source | string (FileSource) <= 128 characters The source of the file. |
| mimeType | string (MimeType) <= 256 characters File type. E.g. text/plain, application/pdf, .. |
object (FilesMetadataField) Custom, application specific metadata. String key -> String value. Limits: Maximum length of key is 128 bytes, value 10240 bytes, up to 256 key-value pairs, of total size at most 10240. | |
| assetIds | Array of integers <int64> (CogniteInternalId) [ 1 .. 1000 ] items [ items <int64 > [ 1 .. 9007199254740991 ] ] |
| dataSetId | integer <int64> (DataSetId) [ 1 .. 9007199254740991 ] The dataSet Id for the item. |
| sourceCreatedTime | integer <int64> >= 0 The timestamp for when the file was originally created in the source system, specified in milliseconds since the epoch. |
| sourceModifiedTime | integer <int64> >= 0 The timestamp for when the file was last modified in the source system, specified in milliseconds since the epoch. |
| securityCategories | Array of integers <int64> (CogniteInternalId) [ 0 .. 100 ] items [ items <int64 > [ 1 .. 9007199254740991 ] ] The security category IDs required to access this file. |
Array of objects (LabelList) [ 0 .. 10 ] items unique A list of the labels associated with this resource item. | |
object (GeoLocation) Geographic metadata. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "externalId": "my.known.id",
- "name": "string",
- "directory": "string",
- "source": "string",
- "mimeType": "image/jpeg",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "dataSetId": 1,
- "sourceCreatedTime": 1730204346000,
- "sourceModifiedTime": 1730204346000,
- "securityCategories": [
- 1
], - "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}
}Response samples
- 201
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "directory": "string",
- "source": "string",
- "mimeType": "image/jpeg",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "dataSetId": 1,
- "sourceCreatedTime": 1730204346000,
- "sourceModifiedTime": 1730204346000,
- "securityCategories": [
- 1
], - "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1,
- "uploaded": true,
- "uploadedTime": 1730204346000,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "pendingInstanceId": {
- "space": "string",
- "externalId": "string"
}, - "uploadUrl": "string"
}
]
}Upload multipart file
Multipart file upload enables upload of files larger than 5 GiB, using a uniform API on all cloud environments for CDF.
Each file part must be larger than 5 MiB, and smaller than 4000 MiB. The file part for the last uploadURL can be smaller than 5 MiB. Maximum 250 upload URLs can be requested.
The supported maximum size for each file uploaded with the multi-part upload API is therefore 1000 GiB (1.073 TB / 0.976 TiB).
The client should calculate the ideal number of parts depending on predetermined or estimated file size, between 1 and the maximum.
Specify the number of parts in the parts URL query parameter. The parts parameter is required.
The request creates metadata information for a new file, and returns in addition to the file id, also a uploadId, and a list of uploadUrls for uploading the file contents.
To upload a file, send an HTTP PUT request to each of the uploadUrls, with the corresponding part of the file in the request body.
You may use a 'Content-Length' header in the PUT request for each part, but this is not required.
A failed part PUT upload can be retried.
The client must ensure that the parts of the source file are stored in the correct order, using the order of the uploadUrls as specified in the response.
This to avoid ending up with a corrupt final file.
The parts can optionally be uploaded in parallel, preferably on a subset of parts at a time, for example maximum 3 concurrent PUT operations.
Once all file parts have been uploaded, the client should call the 'files/completemultipartupload' endpoint,
with the required file ID (as id or externalId) and uploadId fields in the request body. This will assemble the parts into one file.
The file's uploaded flag will then eventually be set to true.
A standard sequence of calls to upload a large file with multipart upload would be for example as follows:
- POST files/initmultipartupload?parts=8, to start a multipart upload session with 8 parts. Expect a 201 CREATED response code, and a response body with information to be used in the part uploads and completemultipartupload requests.
- PUT
uploadUrl, for each of theuploadUrlsin the response from files/initmultipartupload. Expect a 200 OK or 201 CREATED response for each PUT request. - POST files/completemultipartupload, with request body '{ "id":123456789, "uploadId":"ABCD4321EFGH" }'. This will assemble the file. Expect a 200 OK response.
Consider verifying that the file is eventually marked as uploaded with a call to the getFileByInternalId endpoint.
NOTE: The uploadUrls expires after one week. A file that does not have the file content parts uploaded and completed within one week will be automatically deleted.
Request throttling
Please note that this endpoint is subject to the new throttling policy, which imposes limits on both request rate and concurrency. For more details, please refer to the Files resource documentation.
Authorizations:
query Parameters
| overwrite | boolean Default: false If 'overwrite' is set to true, and the POST body content specifies a 'externalId' field, fields for the file found for externalId can be overwritten. The default setting is false. If metadata is included in the request body, all of the original metadata will be overwritten. The actual file will be overwritten after a successful upload with the uploadUrls from the response. If there is no successful upload, the current file contents will be kept. File-Asset mappings only change if explicitly stated in the assetIds field of the POST json body. Do not set assetIds in request body if you want to keep the current file-asset mappings. |
| parts required | integer <int32> [ 1 .. 250 ] The 'parts' parameter specifies how many uploadURLs should be returned, for uploading the file contents in parts. See main endpoint description for more details. |
Request Body schema: application/jsonrequired
Fields to be set for the file.
| externalId | string (CogniteExternalId) <= 255 characters The external ID provided by the client. Must be unique for the resource type. |
| name required | string (FileName) <= 256 characters Name of the file. |
| directory | string (FileDirectory) <= 512 characters Directory containing the file. Must be an absolute, unix-style path. |
| source | string (FileSource) <= 128 characters The source of the file. |
| mimeType | string (MimeType) <= 256 characters File type. E.g. text/plain, application/pdf, .. |
object (FilesMetadataField) Custom, application specific metadata. String key -> String value. Limits: Maximum length of key is 128 bytes, value 10240 bytes, up to 256 key-value pairs, of total size at most 10240. | |
| assetIds | Array of integers <int64> (CogniteInternalId) [ 1 .. 1000 ] items [ items <int64 > [ 1 .. 9007199254740991 ] ] |
| dataSetId | integer <int64> (DataSetId) [ 1 .. 9007199254740991 ] The dataSet Id for the item. |
| sourceCreatedTime | integer <int64> >= 0 The timestamp for when the file was originally created in the source system, specified in milliseconds since the epoch. |
| sourceModifiedTime | integer <int64> >= 0 The timestamp for when the file was last modified in the source system, specified in milliseconds since the epoch. |
| securityCategories | Array of integers <int64> (CogniteInternalId) [ 0 .. 100 ] items [ items <int64 > [ 1 .. 9007199254740991 ] ] The security category IDs required to access this file. |
Array of objects (LabelList) [ 0 .. 10 ] items unique A list of the labels associated with this resource item. | |
object (GeoLocation) Geographic metadata. |
Responses
Request samples
- Payload
{- "externalId": "my.known.id",
- "name": "string",
- "directory": "string",
- "source": "string",
- "mimeType": "image/jpeg",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "dataSetId": 1,
- "sourceCreatedTime": 1730204346000,
- "sourceModifiedTime": 1730204346000,
- "securityCategories": [
- 1
], - "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}
}Response samples
- 201
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "directory": "string",
- "source": "string",
- "mimeType": "image/jpeg",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "assetIds": [
- 1
], - "dataSetId": 1,
- "sourceCreatedTime": 1730204346000,
- "sourceModifiedTime": 1730204346000,
- "securityCategories": [
- 1
], - "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1,
- "uploaded": true,
- "uploadedTime": 1730204346000,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "pendingInstanceId": {
- "space": "string",
- "externalId": "string"
}, - "uploadId": "string",
- "uploadUrls": [
- "uploadURL_for_part_1",
- "uploadURL_for_part_2",
- "uploadURL_for_part_3"
]
}
]
}A sequence stores a table with up to 400 columns indexed by row number. There can be at most 400 numeric columns and 200 string columns. Each of the columns has a pre-defined type: a string, integer, or floating point number.
For example, a sequence can represent a curve, either with the dependent variable x as the row number and a single value column y, or can simply store (x,y) pairs in the rows directly. Other potential applications include data logs in which the index isn't time-based. To learn more about sequences, see the concept guide.
Aggregate sequences
The aggregation API allows you to compute aggregated results from a set of sequences, such as
getting the number of sequences in a project or checking what assets the different sequences
in your project are associated with (along with the number of sequences for each asset).
By specifying filter and/or advancedFilter, the aggregation will take place only over those
sequences that match the filters. filter and advancedFilter behave the same way as in the
list endpoint.
The default behavior, when the aggregate field is not specified the request body, is to return the
number of sequences that match the filters (if any), which is the same behavior as when the
aggregate field is set to count.
The following requests will both return the total number of
sequences whose name begins with pump:
{
"advancedFilter": {"prefix": {"property": ["name"], "value": "pump"}}
}
and
{
"aggregate": "count",
"advancedFilter": {"prefix": {"property": ["name"], "value": "pump"}}
}
The response might be:
{"items": [{"count": 42}]}
Setting aggregate to uniqueValues and specifying a property in properties (this field is an array, but currently only supports one property) will
return all unique values (up to a maximum of 1000) that are taken on by that property
across all the sequences that match the filters, as well as the number of sequences that
have each of those property values.
This example request finds all the unique asset ids that are
referenced by the sequences in your project whose name begins with pump:
{
"aggregate": "uniqueValues",
"properties": [{"property": ["assetId"]}],
"advancedFilter": {"prefix": {"property": ["name"], "value": "pump"}}
}
The response might be the following, saying that 23 sequences are associated with asset 18 and 107 sequences are associated with asset 76:
{
"items": [
{"values": ["18"], "count": 23},
{"values": ["76"], "count": 107}
]
}
Setting aggregate to cardinalityValues will instead return the approximate number of
distinct values that are taken on by the given property among the matching sequences.
Example request:
{
"aggregate": "cardinalityValues",
"properties": [{"property": ["assetId"]}],
"advancedFilter": {"prefix": {"property": ["name"], "value": "pump"}}
}
The result is likely exact when the set of unique values is small. In this example, there are likely two distinct asset ids among the matching sequences:
{"items": [{"count": 2}]}
Setting aggregate to uniqueProperties will return the set of unique properties whose property
path begins with path (which can currently only be ["metadata"]) that are contained in the sequences that match the filters.
Example request:
{
"aggregate": "uniqueProperties",
"path": ["metadata"],
"advancedFilter": {"prefix": {"property": ["name"], "value": "pump"}}
}
The result contains all the unique metadata keys in the sequences whose name begins with
pump, and the number of sequences that contains each metadata key:
{
"items": [
{"values": [{"property": ["metadata", "tag"]}], "count": 43},
{"values": [{"property": ["metadata", "installationDate"]}], "count": 97}
]
}
Setting aggregate to cardinalityProperties will instead return the approximate number of
different property keys whose path begins with path (which can currently only be ["metadata"], meaning that this can only be used to count the approximate number of distinct metadata keys among the matching sequences).
Example request:
{
"aggregate": "cardinalityProperties",
"path": ["metadata"],
"advancedFilter": {"prefix": {"property": ["name"], "value": "pump"}}
}
The result is likely exact when the set of unique values is small. In this example, there are likely two distinct metadata keys among the matching sequences:
{"items": [{"count": 2}]}
The aggregateFilter field may be specified if aggregate is set to cardinalityProperties or uniqueProperties. The structure of this field is similar to that of advancedFilter, except that the set of leaf filters is smaller (in, prefix, and range), and that none of the leaf filters specify a property. Unlike advancedFilter, which is applied before the aggregation (in order to restrict the set of sequences that the aggregation operation should be applied to), aggregateFilter is applied after the initial aggregation has been performed, in order to restrict the set of results.
Click here for more details about aggregateFilter.
When aggregate is set to uniqueProperties, the result set contains a number of property paths, each with an associated count that shows how many sequences contained that property (among those sequences that matched the filter and advancedFilter, if they were specified) . If aggregateFilter is specified, it will restrict the property paths included in the output. Let us add an aggregateFilter to the uniqueProperties example from above:
{
"aggregate": "uniqueProperties",
"path": ["metadata"],
"advancedFilter": {"prefix": {"property": ["name"], "value": "pump"}},
"aggregateFilter": {"prefix": {"value": "t"}}
}
Now, the result only contains those metadata properties whose key begins with t (but it will be the same set of metadata properties that begin with t as in the original query without aggregateFilter, and the counts will be the same):
{
"items": [
{"values": [{"property": ["metadata", "tag"]}], "count": 43}
]
}
Similarly, adding aggregateFilter to cardinalityProperties will return the approximate number of properties whose property key matches aggregateFilter from those sequences matching the filter and advancedFilter (or from all sequences if neither filter nor aggregateFilter are specified):
{
"aggregate": "cardinalityProperties",
"path": ["metadata"],
"advancedFilter": {"prefix": {"property": ["name"], "value": "pump"}},
"aggregateFilter": {"prefix": {"value": "t"}}
}
As we saw above, only one property matches:
{"items": [{"count": 1}]}
Note that aggregateFilter is also accepted when aggregate is set to cardinalityValues or cardinalityProperties. For those aggregations, the effect of any aggregateFilter could also be achieved via a similar advancedFilter. However, aggregateFilter is not accepted when aggregate is omitted or set to count.
Rate and concurrency limits
Rate and concurrency limits apply this endpoint. If a request exceeds one of the limits,
it will be throttled with a 429: Too Many Requests response. More on limit types
and how to avoid being throttled is described
here.
| Limit | Per project | Per user (identity) |
|---|---|---|
| Rate | 15 requests per second | 10 requests per second |
| Concurrency | 6 concurrent requests | 4 concurrent requests |
Authorizations:
Request Body schema: application/json
Aggregates the sequences that match the given criteria.
(Boolean filter (and (object) or or (object) or not (object))) or (Leaf filter (equals (object) or in (object) or range (object) or prefix (object) or exists (object) or containsAny (object) or containsAll (object) or search (object))) (SequencesFilterLanguage) | |
(Boolean filter (and (object) or or (object) or not (object))) or (Leaf filter (in (object) or range (object) or prefix (object))) (SequencesAggregateFilter) | |
object (SequenceFilter) | |
| aggregate | string Value: "count" The |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "advancedFilter": {
- "or": [
- {
- "not": {
- "and": [
- {
- "equals": {
- "property": [
- "metadata",
- "manufacturer"
], - "value": "acme"
}
}, - {
- "in": {
- "property": [
- "name"
], - "values": [
- "pump-1-temperature",
- "motor-9-temperature"
]
}
}, - {
- "range": {
- "property": [
- "dataSetId"
], - "gte": 1,
- "lt": 10
}
}
]
}
}, - {
- "and": [
- {
- "equals": {
- "property": [
- "assetId"
], - "value": 1234
}
}, - {
- "equals": {
- "property": [
- "description"
], - "value": "Temperature in Celsius"
}
}
]
}
]
}, - "aggregateFilter": {
- "and": [
- { }
]
}, - "filter": {
- "name": "string",
- "externalIdPrefix": "my.known.prefix",
- "metadata": {
- "key1": "value1",
- "key2": "value2"
}, - "assetIds": [
- 363848954441724,
- 793045462540095,
- 1261042166839739
], - "rootAssetIds": [
- 363848954441724,
- 793045462540095,
- 1261042166839739
], - "assetSubtreeIds": [
- {
- "id": 1234567890
}, - {
- "externalId": "externalId123"
}
], - "createdTime": {
- "max": 0,
- "min": 0
}, - "lastUpdatedTime": {
- "max": 0,
- "min": 0
}, - "dataSetIds": [
- {
- "id": 1
}
]
}, - "aggregate": "count"
}Response samples
- 200
- 400
{- "items": [
- {
- "count": 0
}
]
}Create sequences
Create one or more sequences.
Authorizations:
Request Body schema: application/jsonrequired
Sequence to be stored.
required | Array of objects (PostSequenceDTO) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "name": "Any relevant name",
- "description": "Optional description",
- "assetId": 1221123111,
- "externalId": "my.known.id",
- "metadata": {
- "extracted-by": "cognite"
}, - "columns": [
- {
- "name": "depth",
- "externalId": "DPS1",
- "description": "Optional description",
- "valueType": "STRING",
- "metadata": {
- "extracted-by": "cognite"
}
}
], - "dataSetId": 1
}
]
}Response samples
- 201
- 400
{- "items": [
- {
- "id": 1,
- "name": "Any relevant name",
- "description": "Optional description",
- "assetId": 1221123111,
- "externalId": "my.known.id",
- "metadata": {
- "extracted-by": "cognite"
}, - "columns": [
- {
- "name": "depth",
- "externalId": "DPS1",
- "description": "Optional description",
- "valueType": "STRING",
- "metadata": {
- "extracted-by": "cognite"
}, - "createdTime": 100000000000,
- "lastUpdatedTime": 100000000000
}
], - "createdTime": 100000000000,
- "lastUpdatedTime": 100000000000,
- "dataSetId": 2718281828459
}
]
}Delete rows
Deletes the given rows of the sequence. All columns are affected.
Authorizations:
Request Body schema: application/jsonrequired
Indicate the sequences and the rows where data should be deleted.
required | Array of Select by Id (object) or Select by ExternalId (object) (SequenceDeleteDataRequest) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "rows": [
- 1
], - "id": 1
}
]
}Response samples
- 200
{ }Delete sequences
Deletes the sequences with the specified IDs. If one or more of the sequences do not exist, the ignoreUnknownIds parameter controls what will happen: if it is true, the sequences that do exist will be deleted, and the request succeeds; if it is false or absent, nothing will be deleted, and the request fails.
Authorizations:
Request Body schema: application/jsonrequired
Ids of the sequences to delete.
required | Array of Select by Id (object) or Select by ExternalId (object) [ 1 .. 1000 ] items |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1
}
], - "ignoreUnknownIds": false
}Response samples
- 200
{ }Filter sequences
Retrieves a list of sequences that match the given criteria.
Advanced filtering
The advancedFilter
field lets you create complex filtering expressions that combine simple operations,
such as equals, prefix, and exists, by using the Boolean operators and, or, and not.
Filtering applies to basic fields as well as metadata. See the advancedFilter syntax in the request example.
Supported leaf filters
| Leaf filter | Supported fields | Description and example |
|---|---|---|
containsAll |
Array type fields | Only includes results which contain all of the specified values. {"containsAll": {"property": ["property"], "values": [1, 2, 3]}} |
containsAny |
Array type fields | Only includes results which contain at least one of the specified values. {"containsAny": {"property": ["property"], "values": [1, 2, 3]}} |
equals |
Non-array type fields | Only includes results that are equal to the specified value. {"equals": {"property": ["property"], "value": "example"}} |
exists |
All fields | Only includes results where the specified property exists (has a value). {"exists": {"property": ["property"]}} |
in |
Non-array type fields | Only includes results that are equal to one of the specified values. {"in": {"property": ["property"], "values": [1, 2, 3]}} |
prefix |
String type fields | Only includes results which start with the specified text. {"prefix": {"property": ["property"], "value": "example"}} |
range |
Non-array type fields | Only includes results that fall within the specified range. {"range": {"property": ["property"], "gt": 1, "lte": 5}} Supported operators: gt, lt, gte, lte |
search |
["name"] and ["description"] |
Introduced to provide functional parity with the /sequences/search endpoint. {"search": {"property": ["property"], "value": "example"}} |
Supported properties
| Property | Type |
|---|---|
["description"] |
string |
["externalId"] |
string |
["metadata", "<someCustomKey>"] |
string |
["name"] |
string |
["assetId"] |
number |
["assetRootId"] |
number |
["createdTime"] |
number |
["dataSetId"] |
number |
["id"] |
number |
["lastUpdatedTime"] |
number |
Limits
- Filter query max depth: 10.
- Filter query max number of clauses: 100.
andandorclauses must have at least one element (and at most 99, since each element counts towards the total clause limit, and so does theand/orclause itself).- The
propertyarray of each leaf filter has the following limitations:- Number of elements in the array is 1 or 2.
- Elements must not be null or blank.
- Each element max length is 256 characters.
- The
propertyarray must match one of the existing properties (static top-level property or dynamic metadata property).
containsAll,containsAny, andinfiltervaluesarray size must be in the range [1, 100].containsAll,containsAny, andinfiltervaluesarray must contain elements of number or string type (matching the type of the given property).rangefilter must have at lest one ofgt,gte,lt,lteattributes. Butgtis mutually exclusive togte, whileltis mutually exclusive tolte.gt,gte,lt,ltein therangefilter must be of number or string type (matching the type of the given property).searchfiltervaluemust not be blank, and the length must be in the range [1, 128], and there may be at most twosearchfilters in the entire filter query.- The maximum length of the
valueof a leaf filter that is applied to a string property is 256.
Sorting
By default, sequences are sorted by their creation time in ascending order.
Sorting by another property or by several other properties can be explicitly requested via the
sort field, which must contain a list
of one or more sort specifications. Each sort specification indicates the property to sort on
and, optionally, the order in which to sort (defaults to asc). If multiple sort specifications are
supplied, the results are sorted on the first property, and those with the same value for the first
property are sorted on the second property, and so on.
Partitioning is done independently of sorting; there is no guarantee of sort order between elements from different partitions.
Null values
In case the nulls field has the auto value, or the field isn't specified, null (missing) values
are considered bigger than any other values. They are placed last when sorting in the asc
order and first in the desc order. Otherwise, missing values are placed according to
the nulls field (last or first), and their placement won't depend on the order
field. Note that the number zero, empty strings, and empty lists are all considered
not null.
Example
{
"sort": [
{
"property" : ["createdTime"],
"order": "desc",
"nulls": "last"
},
{
"property" : ["metadata", "<someCustomKey>"]
}
]
}
Properties
You can sort on the following properties:
| Property |
|---|
["assetId"] |
["createdTime"] |
["dataSetId"] |
["description"] |
["externalId"] |
["lastUpdatedTime"] |
["metadata", "<someCustomKey>"] |
["name"] |
Limits
The sort array must contain 1 to 2 elements.
Authorizations:
Request Body schema: application/json
Retrieves a list of sequences matching the given criteria.
object (SequenceFilter) | |
(Boolean filter (and (object) or or (object) or not (object))) or (Leaf filter (equals (object) or in (object) or range (object) or prefix (object) or exists (object) or containsAny (object) or containsAll (object) or search (object))) (SequencesFilterLanguage) | |
| limit | integer <int32> [ 1 .. 1000 ] Default: 100 Returns up to this many results per page. |
| cursor | string |
| partition | string (Partition) Splits the data set into To prevent unexpected problems and maximize read throughput, you should at most use 10 (N <= 10) partitions. When using more than 10 partitions, CDF may reduce the number of partitions silently.
For example, CDF may reduce the number of partitions to In future releases of the resource APIs, Cognite may reject requests if you specify more than 10 partitions. When Cognite enforces this behavior, the requests will result in a 400 Bad Request status. |
Array of objects (SequencesSortItem) [ 1 .. 2 ] items Sort by array of selected properties. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "filter": {
- "name": "string",
- "externalIdPrefix": "my.known.prefix",
- "metadata": {
- "key1": "value1",
- "key2": "value2"
}, - "assetIds": [
- 363848954441724,
- 793045462540095,
- 1261042166839739
], - "rootAssetIds": [
- 363848954441724,
- 793045462540095,
- 1261042166839739
], - "assetSubtreeIds": [
- {
- "id": 1234567890
}, - {
- "externalId": "externalId123"
}
], - "createdTime": {
- "max": 0,
- "min": 0
}, - "lastUpdatedTime": {
- "max": 0,
- "min": 0
}, - "dataSetIds": [
- {
- "id": 1
}
]
}, - "advancedFilter": {
- "or": [
- {
- "not": {
- "and": [
- {
- "equals": {
- "property": [
- "metadata",
- "manufacturer"
], - "value": "acme"
}
}, - {
- "in": {
- "property": [
- "name"
], - "values": [
- "pump-1-temperature",
- "motor-9-temperature"
]
}
}, - {
- "range": {
- "property": [
- "dataSetId"
], - "gte": 1,
- "lt": 10
}
}
]
}
}, - {
- "and": [
- {
- "equals": {
- "property": [
- "assetId"
], - "value": 1234
}
}, - {
- "equals": {
- "property": [
- "description"
], - "value": "Temperature in Celsius"
}
}
]
}
]
}, - "limit": 100,
- "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo",
- "partition": "1/10",
- "sort": [
- {
- "property": [
- "string"
], - "order": "asc",
- "nulls": "first"
}
]
}Response samples
- 200
{- "items": [
- {
- "id": 1,
- "name": "Any relevant name",
- "description": "Optional description",
- "assetId": 1221123111,
- "externalId": "my.known.id",
- "metadata": {
- "extracted-by": "cognite"
}, - "columns": [
- {
- "name": "depth",
- "externalId": "DPS1",
- "description": "Optional description",
- "valueType": "STRING",
- "metadata": {
- "extracted-by": "cognite"
}, - "createdTime": 100000000000,
- "lastUpdatedTime": 100000000000
}
], - "createdTime": 100000000000,
- "lastUpdatedTime": 100000000000,
- "dataSetId": 2718281828459
}
], - "nextCursor": "string"
}Insert rows
Inserts rows into a sequence. This overwrites data in rows and columns that exist.
Authorizations:
Request Body schema: application/jsonrequired
Data posted.
required | Array of Select by Id (object) or Select by ExternalId (object) (SequencePostData) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "externalId": "DL/DRILL412/20190103/T3",
- "columns": [
- "Depth",
- "DepthSource",
- "PowerSetting"
], - "rows": [
- {
- "rowNumber": 1,
- "values": [
- 23331.3,
- "s2",
- 61
]
}
]
}
]
}Response samples
- 200
{ }List sequences
List sequences. Use nextCursor to paginate through the results.
Authorizations:
query Parameters
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| partition | string Example: partition=1/10 Splits the data set into To prevent unexpected problems and maximize read throughput, you should at most use 10 (N <= 10) partitions. When using more than 10 partitions, CDF may reduce the number of partitions silently.
For example, CDF may reduce the number of partitions to In future releases of the resource APIs, Cognite may reject requests if you specify more than 10 partitions. When Cognite enforces this behavior, the requests will result in a 400 Bad Request status. |
| limit | integer [ 1 .. 1000 ] Default: 25 Limits the number of results to be returned. The server returns a maximum of 1000 results even if you specify a higher limit. |
Responses
Request samples
- JavaScript SDK
- Python SDK
const sequences = await client.sequences.list({ filter: { name: 'sequence_name' } });
Response samples
- 200
{- "items": [
- {
- "id": 1,
- "name": "Any relevant name",
- "description": "Optional description",
- "assetId": 1221123111,
- "externalId": "my.known.id",
- "metadata": {
- "extracted-by": "cognite"
}, - "columns": [
- {
- "name": "depth",
- "externalId": "DPS1",
- "description": "Optional description",
- "valueType": "STRING",
- "metadata": {
- "extracted-by": "cognite"
}, - "createdTime": 100000000000,
- "lastUpdatedTime": 100000000000
}
], - "createdTime": 100000000000,
- "lastUpdatedTime": 100000000000,
- "dataSetId": 2718281828459
}
], - "nextCursor": "string"
}Retrieve last row
Retrieves the last row in one or more sequences. Note that the last row in a sequence is the one with the highest row number, which is not necessarily the one that was ingested most recently.
Authorizations:
Request Body schema: application/jsonrequired
Description of data requested.
| columns | Array of strings [ 1 .. 400 ] items Columns to include. Specified as a list of the |
| before | integer <int64> >= 1 Get rows up to, but not including, this row number. |
| id required | integer <int64> (CogniteInternalId) [ 1 .. 9007199254740991 ] A server-generated ID for the object. |
Responses
Request samples
- Payload
- Python SDK
{- "columns": [
- "string"
], - "before": 1,
- "id": 1
}Response samples
- 200
{- "id": 1112,
- "externalId": "DL/DRILL412/20190103/T3",
- "columns": [
- {
- "externalId": "Depth"
}, - {
- "externalId": "DepthSource"
}, - {
- "externalId": "PowerSetting"
}
], - "rows": [
- {
- "rowNumber": 1,
- "values": [
- 23331.3,
- "s2",
- 61
]
}
]
}Retrieve rows
Processes data requests and returns the result. Note that this operation uses a dynamic limit on the number of rows returned based on the number and type of columns; use the provided cursor to paginate and retrieve all data.
Authorizations:
Request Body schema: application/jsonrequired
Description of data requested.
| start | integer <int64> Default: 0 Lowest row number included. |
| end | integer <int64> Get rows up to, but excluding, this row number. Default - No limit. |
| limit | integer <int32> [ 1 .. 10000 ] Default: 100 Maximum number of rows returned in one request. API might return less even if there's more data, but it will provide a cursor for continuation. If there's more data beyond this limit, a cursor will be returned to simplify further fetching of data. |
| cursor | string Cursor for pagination returned from a previous request. Apart from this cursor, the rest of the request object is the same as for the original request. |
| columns | Array of strings [ 1 .. 400 ] items Columns to include. Specified as a list of the |
| id required | integer <int64> (CogniteInternalId) [ 1 .. 9007199254740991 ] A server-generated ID for the object. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "start": 0,
- "end": 1,
- "limit": 1,
- "cursor": "string",
- "columns": [
- "string"
], - "id": 1
}Response samples
- 200
{- "id": 1112,
- "externalId": "DL/DRILL412/20190103/T3",
- "columns": [
- {
- "externalId": "Depth"
}, - {
- "externalId": "DepthSource"
}, - {
- "externalId": "PowerSetting"
}
], - "rows": [
- {
- "rowNumber": 1,
- "values": [
- 23331.3,
- "s2",
- 61
]
}
], - "nextCursor": "string"
}Retrieve sequences
Retrieves one or more sequences by ID or external ID. The response returns the sequences in the same order as in the request.
Authorizations:
Request Body schema: application/jsonrequired
Ids of the sequences
required | Array of Select by Id (object) or Select by ExternalId (object) [ 1 .. 1000 ] items |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1
}
], - "ignoreUnknownIds": false
}Response samples
- 200
{- "items": [
- {
- "id": 1,
- "name": "Any relevant name",
- "description": "Optional description",
- "assetId": 1221123111,
- "externalId": "my.known.id",
- "metadata": {
- "extracted-by": "cognite"
}, - "columns": [
- {
- "name": "depth",
- "externalId": "DPS1",
- "description": "Optional description",
- "valueType": "STRING",
- "metadata": {
- "extracted-by": "cognite"
}, - "createdTime": 100000000000,
- "lastUpdatedTime": 100000000000
}
], - "createdTime": 100000000000,
- "lastUpdatedTime": 100000000000,
- "dataSetId": 2718281828459
}
]
}Search sequences
Retrieves a list of sequences matching the given criteria. This operation doesn't support pagination.
Authorizations:
Request Body schema: application/json
Retrieves a list of sequences matching the given criteria. This operation doesn't support pagination.
object (SequenceFilter) | |
object (SequenceSearch) | |
| limit | integer <int32> [ 1 .. 1000 ] Default: 100 Returns up to this many results. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
{- "filter": {
- "name": "string",
- "externalIdPrefix": "my.known.prefix",
- "metadata": {
- "key1": "value1",
- "key2": "value2"
}, - "assetIds": [
- 363848954441724,
- 793045462540095,
- 1261042166839739
], - "rootAssetIds": [
- 363848954441724,
- 793045462540095,
- 1261042166839739
], - "assetSubtreeIds": [
- {
- "id": 1234567890
}, - {
- "externalId": "externalId123"
}
], - "createdTime": {
- "max": 0,
- "min": 0
}, - "lastUpdatedTime": {
- "max": 0,
- "min": 0
}, - "dataSetIds": [
- {
- "id": 1
}
]
}, - "search": {
- "name": "string",
- "description": "string",
- "query": "string"
}, - "limit": 100
}Response samples
- 200
{- "items": [
- {
- "id": 1,
- "name": "Any relevant name",
- "description": "Optional description",
- "assetId": 1221123111,
- "externalId": "my.known.id",
- "metadata": {
- "extracted-by": "cognite"
}, - "columns": [
- {
- "name": "depth",
- "externalId": "DPS1",
- "description": "Optional description",
- "valueType": "STRING",
- "metadata": {
- "extracted-by": "cognite"
}, - "createdTime": 100000000000,
- "lastUpdatedTime": 100000000000
}
], - "createdTime": 100000000000,
- "lastUpdatedTime": 100000000000,
- "dataSetId": 2718281828459
}
]
}Update sequences
Updates one or more sequences. Fields outside of the request remain unchanged.
Authorizations:
Request Body schema: application/jsonrequired
Patch definition
required | Array of Select by Id (object) or Select by ExternalId (object) (SequencesUpdate) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "update": {
- "name": {
- "set": "string"
}, - "description": {
- "set": "string"
}, - "assetId": {
- "set": 0
}, - "externalId": {
- "set": "string"
}, - "metadata": {
- "set": {
- "key1": "value1",
- "key2": "value2"
}
}, - "dataSetId": {
- "set": 0
}, - "columns": {
- "modify": [
- {
- "externalId": "my.known.id",
- "update": {
- "description": {
- "set": "string"
}, - "externalId": {
- "set": "string"
}, - "name": {
- "set": "string"
}, - "metadata": {
- "set": {
- "key1": "value1",
- "key2": "value2"
}
}
}
}
], - "add": [
- {
- "name": "depth",
- "externalId": "DPS1",
- "description": "Optional description",
- "valueType": "STRING",
- "metadata": {
- "extracted-by": "cognite"
}
}
], - "remove": [
- {
- "externalId": "my.known.id"
}
]
}
}, - "id": 1
}
]
}Response samples
- 200
{- "items": [
- {
- "id": 1,
- "name": "Any relevant name",
- "description": "Optional description",
- "assetId": 1221123111,
- "externalId": "my.known.id",
- "metadata": {
- "extracted-by": "cognite"
}, - "columns": [
- {
- "name": "depth",
- "externalId": "DPS1",
- "description": "Optional description",
- "valueType": "STRING",
- "metadata": {
- "extracted-by": "cognite"
}, - "createdTime": 100000000000,
- "lastUpdatedTime": 100000000000
}
], - "createdTime": 100000000000,
- "lastUpdatedTime": 100000000000,
- "dataSetId": 2718281828459
}
]
}The Geospatial API allows to model a problem domain when data has a geometric or geographic nature. The geospatial data is organized in feature types that are homogeneous collections of features (geospatial items), each having the same spatial representation, such as points, lines, or polygons, and a common set of typed properties. The Geospatial API is aware of Coordinate Reference Systems, and allows transformations. To learn more about geospatial concepts, see the concept guide.
Aggregate features
Search for features based on the feature property filter and perform requested aggregations on a given property. Aggregations are supported for all filters that do not contain stWithin, stWithinProperly, stContains and stContainsProperly search in 3D geometries.
Authorizations:
path Parameters
| featureTypeExternalId required | string <= 32 characters ^[A-Za-z][A-Za-z0-9_]{0,31}$ Example: ocean_measures External Id of the feature type provided by client. Must be unique among all feature type external ids within a CDF project. |
Request Body schema: application/json
| allowDimensionalityMismatch | boolean (GeospatialAllowDimensionalityMismatch) Optional parameter indicating if the spatial filter operators allow input geometries with a different dimensionality than the properties they are applied to. For instance, when set to true, if a feature type has a property of type POLYGONZM (4D), its features can be filtered using the |
GeospatialFeatureNotFilter (object) or GeospatialFeatureAndFilter (object) or GeospatialFeatureOrFilter (object) or GeospatialFeatureEqualsFilter (object) or GeospatialFeatureMissingFilter (object) or GeospatialFeatureLikeFilter (object) or GeospatialFeatureRegexFilter (object) or GeospatialFeatureRangeFilter (object) or GeospatialFeatureContainsAnyFilter (object) or GeospatialFeatureInFilter (object) or GeospatialFeatureStIntersectsFilter (object) or GeospatialFeatureStIntersects3dFilter (object) or GeospatialFeatureStWithinFilter (object) or GeospatialFeatureStWithinProperlyFilter (object) or GeospatialFeatureStContainsFilter (object) or GeospatialFeatureStContainsProperlyFilter (object) or GeospatialFeatureStWithinDistanceFilter (object) or GeospatialFeatureStWithinDistance3dFilter (object) (GeospatialFeatureFilter) | |
| aggregates | Array of strings Deprecated Items Enum: "avg" "count" "max" "min" "stCentroid" "stCollect" "stConvexHull" "stIntersection" "stUnion" "sum" "variance" This parameter is deprecated. Use |
| property | string Deprecated This parameter is deprecated. Use |
| outputSrid | integer (GeospatialReferenceId) [ 0 .. 1000000 ] EPSG code, e.g. 4326. Only valid for geometry types. See https://en.wikipedia.org/wiki/Spatial_reference_system |
| groupBy | Array of strings names of properties to be used for grouping by |
| sort | Array of strings Sort result by the selected fields (properties or aggregates). Default sort order is ascending if not specified. Available sort direction: ASC, DESC, ASC_NULLS_FIRST, DESC_NULLS_FIRST, ASC_NULLS_LAST, DESC_NULLS_LAST. |
object (GeospatialAggregateOutput) A list of aggregations which are requested. |
Responses
Request samples
- Payload
- JavaScript SDK
{- "filter": {
- "and": [
- {
- "range": {
- "property": "temperature",
- "gt": 4.54
}
}, - {
- "stWithin": {
- "property": "location",
- "value": {
- "wkt": "POLYGON((60.547602 -5.423433, 60.547602 -6.474416, 60.585858 -6.474416, 60.585858 -5.423433, 60.547602 -5.423433))"
}
}
}
]
}, - "groupBy": [
- "category"
], - "sort": [
- "average:ASC",
- "category:DESC"
], - "output": {
- "min_temperature": {
- "min": {
- "property": "temperature"
}
}, - "max_speed": {
- "max": {
- "property": "speed"
}
}
}
}Response samples
- 200
- 400
{- "items": [
- {
- "category": "first category",
- "max": 12.3,
- "min": 0.5,
- "average": 5.32
}, - {
- "category": "second category",
- "max": 14.3,
- "min": 0.7,
- "average": 8.32
}
]
}Compute
Compute custom json output structures or well known binary format responses based on calculation or selection of feature properties or direct values given in the request.
Authorizations:
Request Body schema: application/json
required | object |
Responses
Request samples
- Payload
- JavaScript SDK
{- "output": {
- "value": {
- "stTransform": {
- "geometry": {
- "ewkt": "SRID=4326;POLYGON((0 0,10 0,10 10,0 10,0 0))"
}, - "srid": 23031
}
}
}
}Response samples
- 200
{- "items": [
- {
- "value": {
- "wkt": "POLYGON((0 0,10.5 0,10.5 10.5,0 10.5,0 0))",
- "srid": 23031
}
}
]
}Create Coordinate Reference Systems
Creates custom Coordinate Reference Systems.
Authorizations:
Request Body schema: application/jsonrequired
List of custom Coordinate Reference Systems to be created.
required | Array of objects (GeospatialCoordinateReferenceSystem) |
Responses
Request samples
- Payload
- JavaScript SDK
{- "items": [
- {
- "srid": 456789,
- "wkt": "GEOGCS[\"WGS 84\",DATUM[\"WGS_1984\",SPHEROID[\"WGS 84\",6378137,298.257223563,AUTHORITY[\"EPSG\",\"7030\"]],AUTHORITY[\"EPSG\",\"6326\"]],PRIMEM[\"Greenwich\",0,AUTHORITY[\"EPSG\",\"8901\"]],UNIT[\"degree\",0.0174532925199433,AUTHORITY[\"EPSG\",\"9122\"]],AUTHORITY[\"EPSG\",\"4326\"]]",
- "projString": "+proj=longlat +datum=WGS84 +no_defs \"\""
}
]
}Response samples
- 201
- 400
{- "items": [
- {
- "srid": 4326,
- "wkt": "POINT (0 0)",
- "projString": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Create feature types
Creates feature types. Each tenant can have up to 100 feature types.
Authorizations:
Request Body schema: application/jsonrequired
List of feature types to be created. It is possible to create up to 100 feature types in one request provided the total number of feature types on the tenant will not exceed 100.
required | Array of objects (GeospatialFeatureTypeSpec) [ 1 .. 100 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
{- "items": [
- {
- "externalId": "ocean_temperature",
- "properties": {
- "temperature": {
- "type": "DOUBLE"
}, - "location": {
- "type": "POINT",
- "srid": 4326
}
}, - "searchSpec": {
- "location_idx": {
- "properties": [
- "location"
]
}
}
}
]
}Response samples
- 201
- 400
{- "items": [
- {
- "externalId": "ocean_temperature",
- "dataSetId": 1278028,
- "createdTime": 1629784673505,
- "lastUpdatedTime": 1629784673505,
- "properties": {
- "temperature": {
- "type": "DOUBLE"
}, - "location": {
- "type": "POINT",
- "srid": 4326
}, - "createdTime": {
- "type": "LONG"
}, - "lastUpdatedTime": {
- "type": "LONG"
}, - "externalId": {
- "type": "STRING",
- "size": 32
}
}, - "searchSpec": {
- "location_idx": {
- "properties": [
- "location"
]
}, - "createdTimeIdx": {
- "properties": [
- "createdTime"
]
}, - "lastUpdatedTimeIdx": {
- "properties": [
- "lastUpdatedTime"
]
}, - "externalIdIdx": {
- "properties": [
- "externalId"
]
}
}
}
]
}Create features
Create features
Authorizations:
path Parameters
| featureTypeExternalId required | string <= 32 characters ^[A-Za-z][A-Za-z0-9_]{0,31}$ Example: ocean_measures External Id of the feature type provided by client. Must be unique among all feature type external ids within a CDF project. |
Request Body schema: application/jsonrequired
| allowCrsTransformation | boolean (GeospatialAllowCrsTransformation) Optional parameter indicating if input geometry properties should be transformed into the respective Coordinate Reference Systems defined in the feature type specification. If the parameter is true, then input geometries will be transformed when the input and output Coordinate Reference Systems differ. When it is false, then requests with geometries in Coordinate Reference System different from the ones defined in the feature type will result in bad request response code. Transformations apply to property geometries in case of create and update feature, as well as to geometries in spatial filters in search endpoints. |
required | Array of objects (GeospatialFeatureSpec) [ 1 .. 1000 ] items [ items <= 200 properties ] |
Responses
Request samples
- Payload
- JavaScript SDK
{- "items": [
- {
- "externalId": "measurement_point_765",
- "temperature": 5.65,
- "location": {
- "wkt": "POINT(60.547602 -5.423433)"
}
}, - {
- "externalId": "measurement_point_863",
- "temperature": 5.03,
- "location": {
- "wkt": "POINT(60.585858 -6.474416)"
}
}
]
}Response samples
- 201
- 400
{- "items": [
- {
- "externalId": "measurement_point_765",
- "temperature": 5.65,
- "location": {
- "wkt": "POINT(60.547602 -5.423433)"
}, - "createdTime": 1629784673505,
- "lastUpdatedTime": 1629784673505
}, - {
- "externalId": "measurement_point_863",
- "temperature": 5.03,
- "location": {
- "wkt": "POINT(60.585858 -6.474416)"
}, - "createdTime": 1629784673505,
- "lastUpdatedTime": 1629784673505
}
]
}Delete a raster from a feature property
Delete a raster from a feature property. If there is no raster already, the operation is a no-op.
Authorizations:
path Parameters
| featureTypeExternalId required | string <= 32 characters ^[A-Za-z][A-Za-z0-9_]{0,31}$ Example: ocean_measures External Id of the feature type provided by client. Must be unique among all feature type external ids within a CDF project. |
| featureExternalId required | string <= 256 characters ^[A-Za-z][A-Za-z0-9_]{0,255}$ Example: ocean_measure_W87H62 External Id of the type provided by client. Must be unique among all feature external ids within a CDF project and feature type. |
| rasterPropertyName required | string <= 32 characters ^[A-Za-z][A-Za-z0-9_]{0,31}$ Example: bathymetry Raster Id of the raster property provided by client. Must be unique among all feature property names within a feature type. |
Responses
Response samples
- 200
- 400
{ }Delete Coordinate Reference Systems
Delete custom Coordinate Reference Systems.
Authorizations:
Request Body schema: application/json
List of custom Coordinate Reference Systems to be deleted.
required | Array of objects [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
{- "items": [
- {
- "srid": 4326
}
]
}Response samples
- 200
- 400
{ }Delete feature types
Delete feature types.
Authorizations:
Request Body schema: application/jsonrequired
List of feature types to be deleted. It is possible to delete a maximum of 10 feature types per request. Feature types must not have related features. Feature types with related features can be deleted using force flag.
| recursive | boolean (GeospatialRecursiveDelete) Indicates if feature types should be deleted together with all related features. Optional parameter, defaults to false. |
required | Array of objects [ 1 .. 10 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
{- "items": [
- {
- "externalId": "ocean_temperature"
}
]
}Response samples
- 200
- 400
{ }Delete features
Delete features.
Authorizations:
path Parameters
| featureTypeExternalId required | string <= 32 characters ^[A-Za-z][A-Za-z0-9_]{0,31}$ Example: ocean_measures External Id of the feature type provided by client. Must be unique among all feature type external ids within a CDF project. |
Request Body schema: application/jsonrequired
List of features to be deleted. It is possible to post a maximum of 1000 items per request.
required | Array of objects (GeospatialItemExternalId) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "measurement_point_765"
}, - {
- "externalId": "measurement_point_863"
}
]
}Response samples
- 200
- 400
{ }Filter all features
List features based on the feature property filter passed in the body of the request. This operation supports pagination by cursor.
Authorizations:
path Parameters
| featureTypeExternalId required | string <= 32 characters ^[A-Za-z][A-Za-z0-9_]{0,31}$ Example: ocean_measures External Id of the feature type provided by client. Must be unique among all feature type external ids within a CDF project. |
Request Body schema: application/jsonrequired
| allowCrsTransformation | boolean (GeospatialAllowCrsTransformation) Optional parameter indicating if input geometry properties should be transformed into the respective Coordinate Reference Systems defined in the feature type specification. If the parameter is true, then input geometries will be transformed when the input and output Coordinate Reference Systems differ. When it is false, then requests with geometries in Coordinate Reference System different from the ones defined in the feature type will result in bad request response code. Transformations apply to property geometries in case of create and update feature, as well as to geometries in spatial filters in search endpoints. |
| allowDimensionalityMismatch | boolean (GeospatialAllowDimensionalityMismatch) Optional parameter indicating if the spatial filter operators allow input geometries with a different dimensionality than the properties they are applied to. For instance, when set to true, if a feature type has a property of type POLYGONZM (4D), its features can be filtered using the |
GeospatialFeatureNotFilter (object) or GeospatialFeatureAndFilter (object) or GeospatialFeatureOrFilter (object) or GeospatialFeatureEqualsFilter (object) or GeospatialFeatureMissingFilter (object) or GeospatialFeatureLikeFilter (object) or GeospatialFeatureRegexFilter (object) or GeospatialFeatureRangeFilter (object) or GeospatialFeatureContainsAnyFilter (object) or GeospatialFeatureInFilter (object) or GeospatialFeatureStIntersectsFilter (object) or GeospatialFeatureStIntersects3dFilter (object) or GeospatialFeatureStWithinFilter (object) or GeospatialFeatureStWithinProperlyFilter (object) or GeospatialFeatureStContainsFilter (object) or GeospatialFeatureStContainsProperlyFilter (object) or GeospatialFeatureStWithinDistanceFilter (object) or GeospatialFeatureStWithinDistance3dFilter (object) (GeospatialFeatureFilter) | |
| limit | integer (SearchLimit) [ 1 .. 1000 ] Limits the number of results to be returned. |
object (GeospatialOutput) Desired output specification. | |
| cursor | string |
Responses
Request samples
- Payload
- JavaScript SDK
{- "filter": {
- "and": [
- {
- "range": {
- "property": "temperature",
- "gt": 4.54
}
}, - {
- "stWithin": {
- "property": "location",
- "value": {
- "wkt": "POLYGON((60.547602 -5.423433, 60.547602 -6.474416, 60.585858 -6.474416, 60.585858 -5.423433, 60.547602 -5.423433))"
}
}
}
]
}, - "limit": 100,
- "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo"
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "measurement_point_765",
- "temperature": 5.65,
- "location": {
- "wkt": "POINT(60.547602 -5.423433)"
}, - "createdTime": 1629784673505,
- "lastUpdatedTime": 1629784673505
}, - {
- "externalId": "measurement_point_863",
- "temperature": 5.03,
- "location": {
- "wkt": "POINT(60.585858 -6.474416)"
}, - "createdTime": 1629784673505,
- "lastUpdatedTime": 1629784673505
}
], - "nextCursor": "pwGTFXeL-JiWO8CZpgP23g"
}Get a raster from a feature property
Get a raster from a feature property. The feature property must be of type RASTER.
Authorizations:
path Parameters
| featureTypeExternalId required | string <= 32 characters ^[A-Za-z][A-Za-z0-9_]{0,31}$ Example: ocean_measures External Id of the feature type provided by client. Must be unique among all feature type external ids within a CDF project. |
| featureExternalId required | string <= 256 characters ^[A-Za-z][A-Za-z0-9_]{0,255}$ Example: ocean_measure_W87H62 External Id of the type provided by client. Must be unique among all feature external ids within a CDF project and feature type. |
| rasterPropertyName required | string <= 32 characters ^[A-Za-z][A-Za-z0-9_]{0,31}$ Example: bathymetry Raster Id of the raster property provided by client. Must be unique among all feature property names within a feature type. |
Request Body schema: application/json
| srid | integer (GeospatialReferenceId) [ 0 .. 1000000 ] EPSG code, e.g. 4326. Only valid for geometry types. See https://en.wikipedia.org/wiki/Spatial_reference_system |
| scaleX | number <double> |
| scaleY | number <double> |
| format required | string Value: "XYZ" |
object |
Responses
Request samples
- Payload
{- "srid": 4326,
- "scaleX": 0.1,
- "scaleY": 0.1,
- "format": "GTiff",
- "options": {
- "JPEG_QUALITY": 1
}
}Response samples
- 400
{- "error": {
- "code": 401,
- "message": "Could not authenticate.",
- "missing": [
- { }
], - "duplicated": [
- { }
], - "invalid": [
- { }
], - "dependencies": [
- { }
]
}
}Get Coordinate Reference Systems
Get Coordinate Reference Systems by their Spatial Reference IDs
Authorizations:
Request Body schema: application/json
required | Array of objects [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
{- "items": [
- {
- "srid": 4326
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "srid": 4326,
- "wkt": "GEOGCS[\"WGS 84\",DATUM[\"WGS_1984\",SPHEROID[\"WGS 84\",6378137,298.257223563,AUTHORITY[\"EPSG\",\"7030\"]],AUTHORITY[\"EPSG\",\"6326\"]],PRIMEM[\"Greenwich\",0,AUTHORITY[\"EPSG\",\"8901\"]],UNIT[\"degree\",0.0174532925199433,AUTHORITY[\"EPSG\",\"9122\"]],AUTHORITY[\"EPSG\",\"4326\"]]",
- "projString": "+proj=longlat +datum=WGS84 +no_defs \"\"",
- "createdTime": 1633596134000,
- "lastUpdatedTime": 1633596134000
}
]
}Get features
Get features with paging support
Authorizations:
path Parameters
| featureTypeExternalId required | string <= 32 characters ^[A-Za-z][A-Za-z0-9_]{0,31}$ Example: ocean_measures External Id of the feature type provided by client. Must be unique among all feature type external ids within a CDF project. |
query Parameters
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| limit | integer (SearchLimit) [ 1 .. 1000 ] Default: 1000 Limits the number of results to be returned. |
| allowCrsTransformation | boolean (GeospatialAllowCrsTransformation) Example: allowCrsTransformation=true Optional parameter indicating if input geometry properties should be transformed into the respective Coordinate Reference Systems defined in the feature type specification. If the parameter is true, then input geometries will be transformed when the input and output Coordinate Reference Systems differ. When it is false, then requests with geometries in Coordinate Reference System different from the ones defined in the feature type will result in bad request response code. Transformations apply to property geometries in case of create and update feature, as well as to geometries in spatial filters in search endpoints. |
| allowDimensionalityMismatch | boolean (GeospatialAllowDimensionalityMismatch) Example: allowDimensionalityMismatch=true Optional parameter indicating if the spatial filter operators allow input geometries with a different dimensionality than the properties they are applied to. For instance, when set to true, if a feature type has a property of type POLYGONZM (4D), its features can be filtered using the |
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "measurement_point_765",
- "temperature": 5.65,
- "location": {
- "wkt": "POINT(60.547602 -5.423433)"
}, - "createdTime": 1629784673505,
- "lastUpdatedTime": 1629784673505
}, - {
- "externalId": "measurement_point_863",
- "temperature": 5.03,
- "location": {
- "wkt": "POINT(60.585858 -6.474416)"
}, - "createdTime": 1629784673505,
- "lastUpdatedTime": 1629784673505
}
], - "nextCursor": "pwGTFXeL-JiWO8CZpgP23g"
}List Coordinate Reference Systems
List the defined Coordinate Reference Systems. The list can be limited to the custom Coordinate Reference Systems defined for the tenant.
Authorizations:
query Parameters
| filterOnlyCustom | boolean Example: filterOnlyCustom=true Optional parameter to only list custom Coordinate Reference Systems. Defaults to false. |
Responses
Request samples
- JavaScript SDK
const allCRS = await client.geospatial.crs.list({ filterOnlyCustom : true });
Response samples
- 200
- 400
{- "items": [
- {
- "srid": 4326,
- "wkt": "GEOGCS[\"WGS 84\",DATUM[\"WGS_1984\",SPHEROID[\"WGS 84\",6378137,298.257223563,AUTHORITY[\"EPSG\",\"7030\"]],AUTHORITY[\"EPSG\",\"6326\"]],PRIMEM[\"Greenwich\",0,AUTHORITY[\"EPSG\",\"8901\"]],UNIT[\"degree\",0.0174532925199433,AUTHORITY[\"EPSG\",\"9122\"]],AUTHORITY[\"EPSG\",\"4326\"]]",
- "projString": "+proj=longlat +datum=WGS84 +no_defs \"\"",
- "createdTime": 1633596134000,
- "lastUpdatedTime": 1633596134000
}
]
}List feature types
List all feature types
Authorizations:
Responses
Request samples
- JavaScript SDK
const allFeatureTypes = await client.geospatial.featureType.list();
Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "ocean_temperature",
- "dataSetId": 1278028,
- "createdTime": 1629784673505,
- "lastUpdatedTime": 1629784673505,
- "properties": {
- "temperature": {
- "type": "DOUBLE"
}, - "location": {
- "type": "POINT",
- "srid": 4326
}, - "createdTime": {
- "type": "LONG"
}, - "lastUpdatedTime": {
- "type": "LONG"
}, - "externalId": {
- "type": "STRING",
- "size": 32
}
}, - "searchSpec": {
- "location_idx": {
- "properties": [
- "location"
]
}, - "createdTimeIdx": {
- "properties": [
- "createdTime"
]
}, - "lastUpdatedTimeIdx": {
- "properties": [
- "lastUpdatedTime"
]
}, - "externalIdIdx": {
- "properties": [
- "externalId"
]
}
}
}
]
}Put a raster into a feature property
Put a raster into a feature property. The feature property must be of type RASTER.
Authorizations:
path Parameters
| featureTypeExternalId required | string <= 32 characters ^[A-Za-z][A-Za-z0-9_]{0,31}$ Example: ocean_measures External Id of the feature type provided by client. Must be unique among all feature type external ids within a CDF project. |
| featureExternalId required | string <= 256 characters ^[A-Za-z][A-Za-z0-9_]{0,255}$ Example: ocean_measure_W87H62 External Id of the type provided by client. Must be unique among all feature external ids within a CDF project and feature type. |
| rasterPropertyName required | string <= 32 characters ^[A-Za-z][A-Za-z0-9_]{0,31}$ Example: bathymetry Raster Id of the raster property provided by client. Must be unique among all feature property names within a feature type. |
query Parameters
| srid required | integer [ 1 .. 999999 ] Example: srid=3857 mandatory parameter that specifies the SRID of the coordinate reference system of a raster. |
| format required | string Value: "XYZ" Example: format=XYZ mandatory parameter that specifies the format of the input raster. |
| scaleX | number <double> Example: scaleX=2 optional parameter that specifies the pixel scale x in storage. If not specified, the pixel scale remains the same as the input raster. |
| scaleY | number <double> Example: scaleY=2 optional parameter that specifies the pixel scale y in storage. If not specified, the pixel scale remains the same as the input raster. |
| allowCrsTransformation | boolean Example: allowCrsTransformation=true Optional parameter indicating if the input raster coordinates should be transformed into the Coordinate Reference Systems defined for the raster property in the feature type specification. The transformation will typically impact the pixel values. When the parameter is false, requests with rasters in Coordinate Reference System different from the ones defined in the feature type will result in bad request response code. |
Request Body schema: application/octet-stream
Responses
Response samples
- 200
- 400
{- "srid": 3857,
- "width": 4,
- "height": 5,
- "numBands": 1,
- "scaleX": 1,
- "scaleY": 1,
- "skewX": 0,
- "skewY": 0,
- "upperLeftX": -0.5,
- "upperLeftY": -0.5
}Retrieve feature types
Retrieves feature types by external ids. It is possible to retrieve up to 100 items per request, i.e. the maximum number of feature types for a tenant.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
{- "items": [
- {
- "externalId": "ocean_temperature"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "ocean_temperature",
- "dataSetId": 1278028,
- "createdTime": 1629784673505,
- "lastUpdatedTime": 1629784673505,
- "properties": {
- "temperature": {
- "type": "DOUBLE"
}, - "location": {
- "type": "POINT",
- "srid": 4326
}, - "createdTime": {
- "type": "LONG"
}, - "lastUpdatedTime": {
- "type": "LONG"
}, - "externalId": {
- "type": "STRING",
- "size": 32
}
}, - "searchSpec": {
- "location_idx": {
- "properties": [
- "location"
]
}, - "createdTimeIdx": {
- "properties": [
- "createdTime"
]
}, - "lastUpdatedTimeIdx": {
- "properties": [
- "lastUpdatedTime"
]
}, - "externalIdIdx": {
- "properties": [
- "externalId"
]
}
}
}
]
}Retrieve features
Retrieves features by external ids. It is possible to retrieve up to 1000 items per request.
Authorizations:
path Parameters
| featureTypeExternalId required | string <= 32 characters ^[A-Za-z][A-Za-z0-9_]{0,31}$ Example: ocean_measures External Id of the feature type provided by client. Must be unique among all feature type external ids within a CDF project. |
Request Body schema: application/jsonrequired
required | Array of objects (GeospatialItemExternalId) [ 1 .. 1000 ] items |
object (GeospatialOutput) Desired output specification. |
Responses
Request samples
- Payload
- JavaScript SDK
{- "items": [
- {
- "externalId": "measurement_point_765"
}, - {
- "externalId": "measurement_point_863"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "measurement_point_765",
- "temperature": 5.65,
- "location": {
- "wkt": "POINT(60.547602 -5.423433)"
}, - "createdTime": 1629784673505,
- "lastUpdatedTime": 1629784673505
}, - {
- "externalId": "measurement_point_863",
- "temperature": 5.03,
- "location": {
- "wkt": "POINT(60.585858 -6.474416)"
}, - "createdTime": 1629784673505,
- "lastUpdatedTime": 1629784673505
}
]
}Search and stream features
Search for features based on the feature property filter passed in the body of the request. The streaming response format can be length prefixed, new line delimited, record separator delimited or concatenated depending on requested output (see https://en.wikipedia.org/wiki/JSON_streaming).
Authorizations:
path Parameters
| featureTypeExternalId required | string <= 32 characters ^[A-Za-z][A-Za-z0-9_]{0,31}$ Example: ocean_measures External Id of the feature type provided by client. Must be unique among all feature type external ids within a CDF project. |
Request Body schema: application/json
| allowCrsTransformation | boolean (GeospatialAllowCrsTransformation) Optional parameter indicating if input geometry properties should be transformed into the respective Coordinate Reference Systems defined in the feature type specification. If the parameter is true, then input geometries will be transformed when the input and output Coordinate Reference Systems differ. When it is false, then requests with geometries in Coordinate Reference System different from the ones defined in the feature type will result in bad request response code. Transformations apply to property geometries in case of create and update feature, as well as to geometries in spatial filters in search endpoints. |
| allowDimensionalityMismatch | boolean (GeospatialAllowDimensionalityMismatch) Optional parameter indicating if the spatial filter operators allow input geometries with a different dimensionality than the properties they are applied to. For instance, when set to true, if a feature type has a property of type POLYGONZM (4D), its features can be filtered using the |
GeospatialFeatureNotFilter (object) or GeospatialFeatureAndFilter (object) or GeospatialFeatureOrFilter (object) or GeospatialFeatureEqualsFilter (object) or GeospatialFeatureMissingFilter (object) or GeospatialFeatureLikeFilter (object) or GeospatialFeatureRegexFilter (object) or GeospatialFeatureRangeFilter (object) or GeospatialFeatureContainsAnyFilter (object) or GeospatialFeatureInFilter (object) or GeospatialFeatureStIntersectsFilter (object) or GeospatialFeatureStIntersects3dFilter (object) or GeospatialFeatureStWithinFilter (object) or GeospatialFeatureStWithinProperlyFilter (object) or GeospatialFeatureStContainsFilter (object) or GeospatialFeatureStContainsProperlyFilter (object) or GeospatialFeatureStWithinDistanceFilter (object) or GeospatialFeatureStWithinDistance3dFilter (object) (GeospatialFeatureFilter) | |
| limit | number |
object (GeospatialOutputStreaming) Desired output specification for streaming. |
Responses
Request samples
- Payload
- JavaScript SDK
{- "filter": {
- "and": [
- {
- "range": {
- "property": "temperature",
- "gt": 4.54
}
}, - {
- "stWithin": {
- "property": "location",
- "value": {
- "wkt": "POLYGON((60.547602 -5.423433, 60.547602 -6.474416, 60.585858 -6.474416, 60.585858 -5.423433, 60.547602 -5.423433))"
}
}
}
]
}, - "limit": 100,
- "output": {
- "jsonStreamFormat": "NEW_LINE_DELIMITED"
}
}Response samples
- 200
- 400
{- "property1": "string",
- "property2": "string",
- "externalId": "my.known.id",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}Search features
Search for features based on the feature property filter passed in the body of the request. The result of the search is limited to a maximum of 1000 items. Results in excess of the limit are truncated. This means that the complete result set of the search cannot be retrieved with this method. However, for a given unmodified feature collection, the result of the search is deterministic and does not change over time.
Authorizations:
path Parameters
| featureTypeExternalId required | string <= 32 characters ^[A-Za-z][A-Za-z0-9_]{0,31}$ Example: ocean_measures External Id of the feature type provided by client. Must be unique among all feature type external ids within a CDF project. |
Request Body schema: application/json
| allowCrsTransformation | boolean (GeospatialAllowCrsTransformation) Optional parameter indicating if input geometry properties should be transformed into the respective Coordinate Reference Systems defined in the feature type specification. If the parameter is true, then input geometries will be transformed when the input and output Coordinate Reference Systems differ. When it is false, then requests with geometries in Coordinate Reference System different from the ones defined in the feature type will result in bad request response code. Transformations apply to property geometries in case of create and update feature, as well as to geometries in spatial filters in search endpoints. |
| allowDimensionalityMismatch | boolean (GeospatialAllowDimensionalityMismatch) Optional parameter indicating if the spatial filter operators allow input geometries with a different dimensionality than the properties they are applied to. For instance, when set to true, if a feature type has a property of type POLYGONZM (4D), its features can be filtered using the |
GeospatialFeatureNotFilter (object) or GeospatialFeatureAndFilter (object) or GeospatialFeatureOrFilter (object) or GeospatialFeatureEqualsFilter (object) or GeospatialFeatureMissingFilter (object) or GeospatialFeatureLikeFilter (object) or GeospatialFeatureRegexFilter (object) or GeospatialFeatureRangeFilter (object) or GeospatialFeatureContainsAnyFilter (object) or GeospatialFeatureInFilter (object) or GeospatialFeatureStIntersectsFilter (object) or GeospatialFeatureStIntersects3dFilter (object) or GeospatialFeatureStWithinFilter (object) or GeospatialFeatureStWithinProperlyFilter (object) or GeospatialFeatureStContainsFilter (object) or GeospatialFeatureStContainsProperlyFilter (object) or GeospatialFeatureStWithinDistanceFilter (object) or GeospatialFeatureStWithinDistance3dFilter (object) (GeospatialFeatureFilter) | |
| limit | integer (SearchLimit) [ 1 .. 1000 ] Limits the number of results to be returned. |
object (GeospatialOutput) Desired output specification. | |
| sort | Array of strings Sort result by selected fields. Syntax: sort:["field_1","field_2:ASC","field_3:DESC"]. Default sort order is ascending if not specified. Available sort direction: ASC, DESC, ASC_NULLS_FIRST, DESC_NULLS_FIRST, ASC_NULLS_LAST, DESC_NULLS_LAST. |
Responses
Request samples
- Payload
- JavaScript SDK
{- "filter": {
- "and": [
- {
- "range": {
- "property": "temperature",
- "gt": 4.54
}
}, - {
- "stWithin": {
- "property": "location",
- "value": {
- "wkt": "POLYGON((60.547602 -5.423433, 60.547602 -6.474416, 60.585858 -6.474416, 60.585858 -5.423433, 60.547602 -5.423433))"
}
}
}
]
}, - "limit": 100,
- "sort": [
- "temperature:ASC",
- "location"
]
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "measurement_point_765",
- "temperature": 5.65,
- "location": {
- "wkt": "POINT(60.547602 -5.423433)"
}, - "createdTime": 1629784673505,
- "lastUpdatedTime": 1629784673505
}, - {
- "externalId": "measurement_point_863",
- "temperature": 5.03,
- "location": {
- "wkt": "POINT(60.585858 -6.474416)"
}, - "createdTime": 1629784673505,
- "lastUpdatedTime": 1629784673505
}
]
}Update feature types
Update one or more feature types
Authorizations:
Request Body schema: application/jsonrequired
List of feature types to be updated. It is possible to add and remove properties and indexes. WARNING: removing properties will result in data loss in corresponding features.
required | Array of objects (GeospatialUpdateFeatureTypeSpec) [ 1 .. 100 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
{- "items": [
- {
- "externalId": "ocean_temperature",
- "update": {
- "properties": {
- "add": {
- "depth": {
- "type": "DOUBLE"
}
}
}, - "searchSpec": {
- "add": {
- "depth_idx": {
- "properties": [
- "depth"
]
}
}
}
}
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "ocean_temperature",
- "dataSetId": 1278028,
- "createdTime": 1629784673505,
- "lastUpdatedTime": 1629784673505,
- "properties": {
- "temperature": {
- "type": "DOUBLE"
}, - "location": {
- "type": "POINT",
- "srid": 4326
}, - "createdTime": {
- "type": "LONG"
}, - "lastUpdatedTime": {
- "type": "LONG"
}, - "externalId": {
- "type": "STRING",
- "size": 32
}
}, - "searchSpec": {
- "location_idx": {
- "properties": [
- "location"
]
}, - "createdTimeIdx": {
- "properties": [
- "createdTime"
]
}, - "lastUpdatedTimeIdx": {
- "properties": [
- "lastUpdatedTime"
]
}, - "externalIdIdx": {
- "properties": [
- "externalId"
]
}
}
}
]
}Update features
Update features. This is a replace operation, i.e., all feature properties have to be sent in the request body even if their values do not change.
Authorizations:
path Parameters
| featureTypeExternalId required | string <= 32 characters ^[A-Za-z][A-Za-z0-9_]{0,31}$ Example: ocean_measures External Id of the feature type provided by client. Must be unique among all feature type external ids within a CDF project. |
Request Body schema: application/jsonrequired
List of features to update.
| allowCrsTransformation | boolean (GeospatialAllowCrsTransformation) Optional parameter indicating if input geometry properties should be transformed into the respective Coordinate Reference Systems defined in the feature type specification. If the parameter is true, then input geometries will be transformed when the input and output Coordinate Reference Systems differ. When it is false, then requests with geometries in Coordinate Reference System different from the ones defined in the feature type will result in bad request response code. Transformations apply to property geometries in case of create and update feature, as well as to geometries in spatial filters in search endpoints. |
required | Array of objects (GeospatialFeatureSpec) [ 1 .. 1000 ] items [ items <= 200 properties ] |
Responses
Request samples
- Payload
- JavaScript SDK
{- "items": [
- {
- "externalId": "measurement_point_765",
- "temperature": 5.65,
- "location": {
- "wkt": "POINT(60.547602 -5.423433)"
}
}, - {
- "externalId": "measurement_point_863",
- "temperature": 5.03,
- "location": {
- "wkt": "POINT(60.585858 -6.474416)"
}
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "measurement_point_765",
- "temperature": 5.65,
- "location": {
- "wkt": "POINT(60.547602 -5.423433)"
}, - "createdTime": 1629784673505,
- "lastUpdatedTime": 1629784673505
}, - {
- "externalId": "measurement_point_863",
- "temperature": 5.03,
- "location": {
- "wkt": "POINT(60.585858 -6.474416)"
}, - "createdTime": 1629784673505,
- "lastUpdatedTime": 1629784673505
}
]
}A seismic object is a no-copy view into seismic stores. Once you have defined the object, either via a polygon to "cut out" from the origin seismic store or via an explicit trace-by-trace mapping, you cannot modify it. You can assign seismic objects to partitions and restrict user access to each partition. That way, seismic objects are the most granular unit of access control. Each seismic object has one corresponding partition. If a user is restricted to a specific partition, they will only be able to view the seismic objects that have been assigned to that partition.
Download a seismic object as a SEG-Y file
Retrieves a SEG-Y file with all traces contained within the given seismic object.
Authorizations:
path Parameters
| seismicId required | integer The identifier of a seismic object |
Responses
Response samples
- 400
{- "error": {
- "code": 401,
- "message": "Could not authenticate.",
- "missing": [
- { }
], - "duplicated": [
- { }
]
}
}Download multiple seismic objects as a ZIP archive
Download multiple seismic objects specified by the filter, as a streamed ZIP archive file.
Authorizations:
Request Body schema: application/jsonrequired
The filter that determines the seismic objects to return.
| items required | Array of integers <int64> (CogniteInternalId) [ items <int64 > [ 1 .. 9007199254740991 ] ] The list of seismic objects to include in the ZIP archive, specified by internal id. |
Responses
Request samples
- Payload
{- "items": [
- 1
]
}Response samples
- 400
{- "error": {
- "code": 401,
- "message": "Could not authenticate.",
- "missing": [
- { }
], - "duplicated": [
- { }
]
}
}Create 3D models
Authorizations:
Request Body schema: application/jsonrequired
The models to create.
required | Array of objects (CreateModel3D) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "name": "My Model",
- "dataSetId": 1,
- "metadata": {
- "property1": "string",
- "property2": "string"
}
}
]
}Response samples
- 201
- 400
{- "items": [
- {
- "name": "My Model",
- "id": 1000,
- "createdTime": 0,
- "dataSetId": 1,
- "space": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}
}
]
}Delete 3D models
Authorizations:
Request Body schema: application/jsonrequired
List of models to delete.
required | Array of objects (DataIdentifier) [ 1 .. 1000 ] items unique List of ID objects |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1
}
]
}Response samples
- 200
- 400
{ }List 3D models
Retrieves a list of all models in a project. This operation supports pagination. You can filter out all models without a published revision.
Authorizations:
query Parameters
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 1000 even if you specify a higher limit. |
| includeRevisionInfo | boolean Default: false If true, return latest revision info as part of response |
| published | boolean Filter based on whether or not it has published revisions. |
Responses
Request samples
- JavaScript SDK
- Python SDK
- Java SDK
const models3D = await client.models3D.list({ published: true });
Response samples
- 200
- 400
{- "items": [
- {
- "name": "My Model",
- "id": 1000,
- "createdTime": 0,
- "dataSetId": 1,
- "space": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}
}
], - "nextCursor": "string"
}Retrieve a 3D model
Authorizations:
path Parameters
| modelId required | integer <int64> Model ID. |
Responses
Request samples
- JavaScript SDK
- Python SDK
- Java SDK
await client.models3D.retrieve(3744350296805509);
Response samples
- 200
- 400
{- "name": "My Model",
- "id": 1000,
- "createdTime": 0,
- "dataSetId": 1,
- "space": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}
}Update 3D models
Authorizations:
Request Body schema: application/jsonrequired
List of changes.
required | Array of objects (UpdateModel3D) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1,
- "update": {
- "name": {
- "set": "string"
}, - "dataSetId": {
- "set": 1
}, - "metadata": {
- "set": {
- "key1": "value1",
- "key2": "value2"
}
}
}
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "name": "My Model",
- "id": 1000,
- "createdTime": 0,
- "dataSetId": 1,
- "space": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}
}
]
}Create 3D revisions
Authorizations:
path Parameters
| modelId required | integer <int64> Model ID. |
Request Body schema: application/json
The revisions to create.
required | Array of objects (CreateRevision3D) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "published": false,
- "rotation": [
- 0,
- 0,
- 0
], - "scale": [
- 1,
- 1,
- 1
], - "translation": [
- 0,
- 0,
- 0
], - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "camera": {
- "target": [
- 0.1,
- 0.1,
- 0.1
], - "position": [
- 0.1,
- 0.1,
- 0.1
]
}, - "fileId": 0
}
]
}Response samples
- 201
- 400
{- "items": [
- {
- "id": 1000,
- "fileId": 1000,
- "published": false,
- "rotation": [
- 0,
- 0,
- 0
], - "scale": [
- 1,
- 1,
- 1
], - "translation": [
- 0,
- 0,
- 0
], - "camera": {
- "target": [
- 0.1,
- 0.1,
- 0.1
], - "position": [
- 0.1,
- 0.1,
- 0.1
]
}, - "status": "Done",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "thumbnailThreedFileId": 1000,
- "assetMappingCount": 0,
- "createdTime": 0
}
]
}Delete 3D revisions
Authorizations:
path Parameters
| modelId required | integer <int64> Model ID. |
Request Body schema: application/jsonrequired
List of revisions ids to delete.
required | Array of objects (DataIdentifier) [ 1 .. 1000 ] items unique List of ID objects |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1
}
]
}Response samples
- 200
- 400
{ }Filter 3D nodes
List nodes in a project, filtered by node names or node property values specified by supplied filters. This operation supports pagination and partitions. If the model revision is still being processed, you will get a HTTP status 400 when accessing nodes too early. Wait until the retrieve revision response returns "status":"Done" before calling nodes endpoints.
Authorizations:
path Parameters
| modelId required | integer <int64> Model ID. |
| revisionId required | integer <int64> Revision ID. |
Request Body schema: application/jsonrequired
object (Node3DPropertyFilter) Filters used in the search. | |
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to return. |
| cursor | string |
| partition | string (Partition) Splits the data set into To prevent unexpected problems and maximize read throughput, you should at most use 10 (N <= 10) partitions. When using more than 10 partitions, CDF may reduce the number of partitions silently.
For example, CDF may reduce the number of partitions to In future releases of the resource APIs, Cognite may reject requests if you specify more than 10 partitions. When Cognite enforces this behavior, the requests will result in a 400 Bad Request status. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "filter": {
- "properties": {
- "PDMS": {
- "Area": [
- "AB76",
- "AB77",
- "AB78"
], - "Type": [
- "PIPE",
- "BEND",
- "PIPESUP"
]
}
}
}, - "limit": 100,
- "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo",
- "partition": "1/10"
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 1000,
- "treeIndex": 3,
- "parentId": 2,
- "depth": 2,
- "name": "Node name",
- "subtreeSize": 4,
- "properties": {
- "category1": {
- "property1": "value1",
- "property2": "value2"
}, - "category2": {
- "property1": "value1",
- "property2": "value2"
}
}, - "boundingBox": {
- "max": [
- 0.1,
- 0.1,
- 0.1
], - "min": [
- 0.1,
- 0.1,
- 0.1
]
}
}
], - "nextCursor": "string"
}Get 3D nodes by ID
Retrieves specific nodes given by a list of IDs.
Authorizations:
path Parameters
| modelId required | integer <int64> Model ID. |
| revisionId required | integer <int64> Revision ID. |
Request Body schema: application/jsonrequired
The request body containing the IDs of the nodes to retrieve. Will return error 400 if the revision is still being processed.
required | Array of objects (Node3DId) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Java SDK
{- "items": [
- {
- "id": 1000
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 1000,
- "treeIndex": 3,
- "parentId": 2,
- "depth": 2,
- "name": "Node name",
- "subtreeSize": 4,
- "properties": {
- "category1": {
- "property1": "value1",
- "property2": "value2"
}, - "category2": {
- "property1": "value1",
- "property2": "value2"
}
}, - "boundingBox": {
- "max": [
- 0.1,
- 0.1,
- 0.1
], - "min": [
- 0.1,
- 0.1,
- 0.1
]
}
}
]
}List 3D ancestor nodes
Retrieves a list of ancestor nodes of a given node, including itself, in the hierarchy of the 3D model. This operation supports pagination. Will return error 400 if the revision is still being processed.
Authorizations:
path Parameters
| modelId required | integer <int64> Model ID. |
| revisionId required | integer <int64> Revision ID. |
| nodeId required | integer <int64> ID of the node to get the ancestors of. |
query Parameters
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 1000 even if you specify a higher limit. |
Responses
Request samples
- JavaScript SDK
- Python SDK
- Java SDK
const nodes3d = await client.revisions3D.list3DNodeAncestors(8252999965991682, 4190022127342195, 572413075141081);
Response samples
- 200
- 400
{- "items": [
- {
- "id": 1000,
- "treeIndex": 3,
- "parentId": 2,
- "depth": 2,
- "name": "Node name",
- "subtreeSize": 4,
- "properties": {
- "category1": {
- "property1": "value1",
- "property2": "value2"
}, - "category2": {
- "property1": "value1",
- "property2": "value2"
}
}, - "boundingBox": {
- "max": [
- 0.1,
- 0.1,
- 0.1
], - "min": [
- 0.1,
- 0.1,
- 0.1
]
}
}
], - "nextCursor": "string"
}List 3D nodes
Retrieves a list of nodes from the hierarchy in the 3D model. You can also request a specific subtree with the 'nodeId' query parameter and limit the depth of the resulting subtree with the 'depth' query parameter. By default, nodes are returned in order of ascending treeIndex. We suggest trying to set the query parameter sortByNodeId to true to check whether it makes your use case faster. The partition parameter can only be used if sortByNodeId is set to true. This operation supports pagination. If the model revision is still being processed, you will get a HTTP status 400 when accessing nodes too early. Wait until the retrieve revision response returns "status":"Done" before calling nodes endpoints.
Authorizations:
path Parameters
| modelId required | integer <int64> Model ID. |
| revisionId required | integer <int64> Revision ID. |
query Parameters
| partition | string Example: partition=1/10 Splits the data set into To prevent unexpected problems and maximize read throughput, you should at most use 10 (N <= 10) partitions. When using more than 10 partitions, CDF may reduce the number of partitions silently.
For example, CDF may reduce the number of partitions to In future releases of the resource APIs, Cognite may reject requests if you specify more than 10 partitions. When Cognite enforces this behavior, the requests will result in a 400 Bad Request status. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 1000 even if you specify a higher limit. |
| depth | integer <int32> Get sub nodes up to this many levels below the specified node. Depth 0 is the root node. |
| nodeId | integer <int64> ID of a node that are the root of the subtree you request (default is the root node). |
| sortByNodeId | boolean Default: false Enable sorting by nodeId. When this parameter is |
| properties | string <jsonObject(jsonObject(string))> Example: Filter for node properties. Only nodes that match all the given properties exactly will be listed.
The filter must be a JSON object with the same format as the |
Responses
Request samples
- JavaScript SDK
- Python SDK
- Java SDK
const nodes3d = await client.revisions3D.list3DNodes(8252999965991682, 4190022127342195);
Response samples
- 200
- 400
{- "items": [
- {
- "id": 1000,
- "treeIndex": 3,
- "parentId": 2,
- "depth": 2,
- "name": "Node name",
- "subtreeSize": 4,
- "properties": {
- "category1": {
- "property1": "value1",
- "property2": "value2"
}, - "category2": {
- "property1": "value1",
- "property2": "value2"
}
}, - "boundingBox": {
- "max": [
- 0.1,
- 0.1,
- 0.1
], - "min": [
- 0.1,
- 0.1,
- 0.1
]
}
}
], - "nextCursor": "string"
}List 3D revision logs
List log entries for the revision
Authorizations:
path Parameters
| modelId required | integer <int64> Model ID. |
| revisionId required | integer <int64> Revision ID. |
query Parameters
| severity | integer <int64> Default: 5 Minimum severity to retrieve (3 = INFO, 5 = WARN, 7 = ERROR). |
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "timestamp": 0,
- "severity": 7,
- "type": "CONVERTER/FAILED",
- "info": "string"
}
]
}List 3D revisions
Retrieves a list of all revisions of a model. This operation supports pagination. You can also filter revisions if they are marked as published or not by using the query param published.
Authorizations:
path Parameters
| modelId required | integer <int64> Model ID. |
query Parameters
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 1000 even if you specify a higher limit. |
| published | boolean Filter based on published status. |
Responses
Request samples
- JavaScript SDK
- Python SDK
- Java SDK
const revisions3D = await client.revisions3D.list(324566546546346);
Response samples
- 200
- 400
{- "items": [
- {
- "id": 1000,
- "fileId": 1000,
- "published": false,
- "rotation": [
- 0,
- 0,
- 0
], - "scale": [
- 1,
- 1,
- 1
], - "translation": [
- 0,
- 0,
- 0
], - "camera": {
- "target": [
- 0.1,
- 0.1,
- 0.1
], - "position": [
- 0.1,
- 0.1,
- 0.1
]
}, - "status": "Done",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "thumbnailThreedFileId": 1000,
- "assetMappingCount": 0,
- "createdTime": 0
}
], - "nextCursor": "string"
}List available outputs
Retrieve a list of available outputs for a processed 3D model. An output can be a format that can be consumed by a viewer (e.g. Reveal) or import in external tools. Each of the outputs will have an associated version which is used to identify the version of output format (not the revision of the processed output). Note that the structure of the outputs will vary and is not covered here.
Authorizations:
path Parameters
| modelId required | integer <int64> Model ID. |
| revisionId required | integer <int64> Revision ID. |
query Parameters
| format | string Format identifier, e.g. 'ept-pointcloud' (point cloud). Well known formats are: 'ept-pointcloud' (point cloud data) or 'reveal-directory' (output supported by Reveal). 'all-outputs' can be used to retrieve all outputs for a 3D revision. Note that some of the outputs are internal, where the format and availability might change without warning. |
Responses
Response samples
- 200
{- "items": [
- {
- "format": "ept-pointcloud",
- "version": 1,
- "blobId": 1
}
]
}Retrieve a 3D revision
Authorizations:
path Parameters
| modelId required | integer <int64> Model ID. |
| revisionId required | integer <int64> Revision ID. |
Responses
Request samples
- JavaScript SDK
- Python SDK
- Java SDK
const revisions3D = await client.revisions3D.retrieve(8252999965991682, 4190022127342195)
Response samples
- 200
{- "id": 1000,
- "fileId": 1000,
- "published": false,
- "rotation": [
- 0,
- 0,
- 0
], - "scale": [
- 1,
- 1,
- 1
], - "translation": [
- 0,
- 0,
- 0
], - "camera": {
- "target": [
- 0.1,
- 0.1,
- 0.1
], - "position": [
- 0.1,
- 0.1,
- 0.1
]
}, - "status": "Done",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "thumbnailThreedFileId": 1000,
- "assetMappingCount": 0,
- "createdTime": 0
}Update 3D revision thumbnail
Authorizations:
path Parameters
| modelId required | integer <int64> Model ID. |
| revisionId required | integer <int64> Revision ID. |
Request Body schema: application/json
The request body containing the file ID of the thumbnail image (from Files API).
| fileId required | integer <int64> File ID of thumbnail file in Files API. Only JPEG and PNG files are supported. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "fileId": 0
}Response samples
- 200
- 400
{ }Update 3D revisions
Authorizations:
path Parameters
| modelId required | integer <int64> Model ID. |
Request Body schema: application/json
List of changes.
required | Array of objects (UpdateRevision3D) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1,
- "update": {
- "published": {
- "set": true
}, - "rotation": {
- "set": [
- 0.1,
- 0.1,
- 0.1
]
}, - "scale": {
- "set": [
- 0.1,
- 0.1,
- 0.1
]
}, - "translation": {
- "set": [
- 0.1,
- 0.1,
- 0.1
]
}, - "camera": {
- "set": {
- "target": [
- 0.1,
- 0.1,
- 0.1
], - "position": [
- 0.1,
- 0.1,
- 0.1
]
}
}, - "metadata": {
- "set": {
- "key1": "value1",
- "key2": "value2"
}
}
}
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 1000,
- "fileId": 1000,
- "published": false,
- "rotation": [
- 0,
- 0,
- 0
], - "scale": [
- 1,
- 1,
- 1
], - "translation": [
- 0,
- 0,
- 0
], - "camera": {
- "target": [
- 0.1,
- 0.1,
- 0.1
], - "position": [
- 0.1,
- 0.1,
- 0.1
]
}, - "status": "Done",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "thumbnailThreedFileId": 1000,
- "assetMappingCount": 0,
- "createdTime": 0
}
]
}Retrieve a 3D directory file
Retrieve the contents of a 3D file, for a blobId which is of a directory type. This applies to the output types 'gltf-directory', 'reveal-directory', 'ept-pointcloud', 'tiles-directory', 'model-from-points'.
The 'subPath' elements, i.e. directory and/or file names, within each directory output type is subject to change and depends on each output type.
- The 'gltf-directory' output is used by Reveal v3+ for visualizing CAD files and contains a 'scene.json' file, which describes what other files are available within the blobId.
- The 'reveal-directory' output is used by Reveal v1-2 for visualizing CAD files and contains a 'scene.json' file, which describes what other files are available within the blobId.
- The 'ept-pointcloud' output is used by Reveal for visualizing point clouds, and contains a 'ept.json' file. The 'ept.json' file contains general information for the point cloud data. The file named 'ept-hierarchy/0-0-0-0.json' for the same blobId lists all the output point files which can be retrieved from a 'ept-data' folder for the same blobId, e.g. 'ept-data/0-0-0-0.bin'. The '.bin' files are in a custom point cloud format following the schema in the 'ept.json' file. Additionally, a 'filterOptions.json' file contains a description of which options were used when processing the point cloud.
Experimental outputs, normally not enabled: The 'tiles-directory' output contains files for classification of the point cloud data. Retrieve the 'tiles.json' file from this output for a overview of the files within this output. The 'model-from-points' output is used for storing a mesh based output file of some parts of the point cloud. This is stored as a 'model.ciff' file, in the Cognite internal file format.
This endpoint supports tag-based caching.
This endpoint is only compatible with 3D file IDs from the 3D API, and not compatible with file IDs from the Files API.
Authorizations:
path Parameters
| threedFileId required | integer <int64> The blob ID of the 3D output directory. |
| subPath required | string The filename for the 3D file to retrieve. |
Responses
Response samples
- 400
{- "error": {
- "code": 401,
- "message": "Could not authenticate.",
- "missing": [
- { }
], - "duplicated": [
- { }
]
}
}Retrieve a single 3D file
Retrieve the contents of a 3D file. This applies to the output types 'ciff-processed', 'ciff-partially-processed' and 'node-property-metadata-json'.
This endpoint supports tag-based caching.
This endpoint is only compatible with 3D file IDs from the 3D API, and not compatible with file IDs from the Files API.
Authorizations:
path Parameters
| threedFileId required | integer <int64> The ID of the 3D file to retrieve. |
Responses
Request samples
- JavaScript SDK
- Python SDK
- Java SDK
await client.files3D.retrieve(3744350296805509);
Response samples
- 400
{- "error": {
- "code": 401,
- "message": "Could not authenticate.",
- "missing": [
- { }
], - "duplicated": [
- { }
]
}
}Create 3D asset mappings
Create asset mappings
Asset mappings allows connections to be made between assets and 3D nodes. This can be used to contextualize 3D models.
In Hybrid CDF projects: Asset IDs obtained from a mapping may be invalid, and not point to real asset IDs.
The assetId existence is not checked by any means by the 3D API.
The mappings will be stored until an assetId and nodeId pair is removed through the mappings delete endpoint.
In DataModelingOnly CDF projects: When creating asset mappings, the data model based assetInstanceId (with space and externalId), and the 3d model revision nodeId, must be accessible, existing and valid.
Authorizations:
path Parameters
| modelId required | integer <int64> Model ID. |
| revisionId required | integer <int64> Revision ID. |
Request Body schema: application/jsonrequired
The asset mappings to create.
required | Array of objects (CreateAssetMapping3D) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "nodeId": 1003,
- "assetId": 3001,
- "assetInstanceId": {
- "space": "string",
- "externalId": "string"
}
}
]
}Response samples
- 201
- 400
{- "items": [
- {
- "nodeId": 1003,
- "assetId": 3001,
- "assetInstanceId": {
- "space": "string",
- "externalId": "string"
}, - "treeIndex": 3,
- "subtreeSize": 4
}
]
}Delete 3D asset mappings
Delete a list of asset mappings.
In Hybrid CDF projects: The delete request items requires a nodeId, and either an assetId or an assetInstanceId.
In DataModelingOnly CDF projects: The delete request items requires a nodeId and an assetInstanceId (with space and externalId).
Authorizations:
path Parameters
| modelId required | integer <int64> Model ID. |
| revisionId required | integer <int64> Revision ID. |
Request Body schema: application/jsonrequired
The IDs of the asset mappings to delete.
required | Array of objects (DeleteAssetMapping3D) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "nodeId": 1003,
- "assetId": 3001,
- "assetInstanceId": {
- "space": "string",
- "externalId": "string"
}
}
]
}Response samples
- 200
- 400
{ }Filter 3D asset mappings
Lists 3D assets mappings that match the specified filter parameter.
Only one type of filter can be specified for each request, either assetIds, nodeIds or treeIndexes.
In Hybrid CDF projects: The nodeId and assetId mappings are returned by default.
To instead see only any assetInstanceId mappings (for CoreDM based contextualization),
set the getDmsInstances property to true, in the request body.
In DataModelingOnly CDF projects: This endpoint is not available. Use DMS queries to list CogniteCADNodes.
Authorizations:
path Parameters
| modelId required | integer <int64> Model ID. |
| revisionId required | integer <int64> Revision ID. |
Request Body schema: application/json
The filter for asset mappings to get.
| getDmsInstances | boolean Default: false If true, the response will include only the mappings with assetInstanceId values, for DMS based assets. |
AssetMapping3DAssetFilter (object) or AssetMapping3DAssetInstanceIdFilter (object) or AssetMapping3DNodeFilter (object) or AssetMapping3DTreeIndexFilter (object) | |
| limit | integer <int32> [ 1 .. 1000 ] Default: 100 Limits the number of results to return. |
| cursor | string |
Responses
Request samples
- Payload
- JavaScript SDK
- Java SDK
{- "getDmsInstances": false,
- "filter": {
- "assetIds": [
- 0
]
}, - "limit": 100,
- "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo"
}Response samples
- 200
- 400
{- "items": [
- {
- "nodeId": 1003,
- "assetId": 3001,
- "assetInstanceId": {
- "space": "string",
- "externalId": "string"
}, - "treeIndex": 3,
- "subtreeSize": 4
}
], - "nextCursor": "string"
}Filter 3D assetInstanceId mappings across all 3D models
Filters the mappings for a specific assetInstanceId across all 3D models in the project.
Authorizations:
Request Body schema: application/json
The filter for assetInstanceId mappings to get.
required | AssetInstanceId (object) |
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to return. |
| cursor | string |
Responses
Request samples
- Payload
{- "filter": {
- "assetInstanceId": {
- "space": "string",
- "externalId": "string"
}
}, - "limit": 100,
- "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo"
}Response samples
- 200
- 400
{- "items": [
- {
- "modelId": 3001,
- "revisionId": 3001,
- "nodeId": 1003
}
], - "nextCursor": "string"
}Filter which nodes are within a boundingbox for a revision.
This endpoint is only supported in dm-only projects.
The nodeIds can be found as part of a CogniteCadNode in the field cadNodeReference.
Similar functionality is supported in classic through:
- list 3D asset mappings endpoint + intersectsBoundingBox
Authorizations:
Request Body schema: application/json
The Model, Revision, a list of nodes and an area definition
required | object (InstanceReference) |
required | object (InstanceReference) |
required | object (FilterNodesByBoundingBox) |
Responses
Request samples
- Payload
{- "model": {
- "instanceId": {
- "space": "string",
- "externalId": "string"
}
}, - "revision": {
- "instanceId": {
- "space": "string",
- "externalId": "string"
}
}, - "filterNodesByBoundingBox": {
- "boundingBox": {
- "xMin": 0.1,
- "xMax": 0.1,
- "yMin": 0.1,
- "yMax": 0.1,
- "zMin": 0.1,
- "zMax": 0.1
}, - "nodeIds": [
- 0
]
}
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 1000,
- "treeIndex": 3,
- "depth": 2,
- "name": "Node name",
- "subtreeSize": 4,
- "boundingBox": {
- "max": [
- 0.1,
- 0.1,
- 0.1
], - "min": [
- 0.1,
- 0.1,
- 0.1
]
}
}
], - "nextCursor": "string"
}List 3D asset mappings
Lists 3D assets mappings that match the ID for the specified filter query parameter type. Only one type of filter can be specified for each request, either assetId, nodeId or intersectsBoundingBox.
In Hybrid CDF projects: The nodeId and assetId mappings are returned by default.
To instead see any assetInstanceId mappings (for CoreDM based contextualization),
set the getDmsInstances query parameter to true.
In DataModelingOnly CDF projects: This endpoint is not available. Use DMS queries to list CogniteCADNodes.
Note: When filtering for a specific nodeId, only nodeIds that actually exists will be returned. When filtering for a specific assetId, all mappings will be returned, even if the assetId does not exist.
Authorizations:
path Parameters
| modelId required | integer <int64> Model ID. |
| revisionId required | integer <int64> Revision ID. |
query Parameters
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 1000 even if you specify a higher limit. |
| nodeId | integer <int64> |
| assetId | integer <int64> |
| intersectsBoundingBox | string Example: If given, only return asset mappings for assets whose bounding box intersects the given bounding box. Must be a JSON object with |
| getDmsInstances | boolean Default: false If true, the response will include any |
Responses
Request samples
- JavaScript SDK
- Python SDK
- Java SDK
const mappings3D = await client.assetMappings3D.list(3244265346345, 32423454353545);
Response samples
- 200
- 400
{- "items": [
- {
- "nodeId": 1003,
- "assetId": 3001,
- "assetInstanceId": {
- "space": "string",
- "externalId": "string"
}, - "treeIndex": 3,
- "subtreeSize": 4
}
], - "nextCursor": "string"
}List mappings for one assetID across all 3D models
Retrieves a list of node IDs from the hierarchy of all available 3D models which are mapped to the supplied asset ID.
If a nodeId is mapped to an assetId but is invalid or does not exist anymore, it will be omitted from the results.
An asset referenced in an asset mapping is not guaranteed to exist.
Authorizations:
path Parameters
| assetId required | integer <int64> Asset ID. |
query Parameters
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 1000 even if you specify a higher limit. |
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "modelId": 3001,
- "revisionId": 3001,
- "nodeId": 1003
}
], - "nextCursor": "string"
}Create 360 Image contextualization
Create contextualization connections between a 360 image annotation and a CogniteAsset instance. The relation between CogniteAsset and the 360 image annotations is One CogniteAsset to Many Cognite360ImageAnnotation. This allows users to navigate between 3D objects in a 360 image model and their connected CogniteAsset instances.
The 360 image annotations are defined for a specific 3D model revision. The connections are referencing the space and externalId for CogniteAsset node instances.
NOTE: This endpoint is only available for DataModelOnly projects.
Authorizations:
Request Body schema: application/json
The assetInstanceId, dmsContextualizationConfig and a list of Image360 Annotation data.
required | Array of objects (CreateImage360AnnotationContextualizationList) [ 1 .. 100 ] items |
required | object (DmsContextualizationConfig) |
Responses
Request samples
- Payload
{- "items": [
- {
- "asset": {
- "instanceId": {
- "space": "string",
- "externalId": "string"
}
}, - "image360": {
- "instanceId": {
- "space": "string",
- "externalId": "string"
}
}, - "polygon": {
- "version": "1.0.1",
- "data": [
- 0.1
]
}
}
], - "dmsContextualizationConfig": {
- "object3DSpace": "string",
- "contextualizationSpace": "string",
- "revisionInstanceId": {
- "space": "string",
- "externalId": "string"
}
}
}Response samples
- 200
- 400
{ }Create Point Cloud Volume contextualization
Create contextualization connections between point cloud volumes and CogniteAsset instances. This allows users to navigate between 3D objects in a Point Cloud 3D model and their connected CogniteAsset instances.
The point cloud volumes are defined for a specific 3D model revision. The connections are referencing the space and externalId for CogniteAsset node instances.
NOTE: This endpoint is only available for DataModelOnly projects.
Authorizations:
Request Body schema: application/json
The assetInstanceId, dmsContextualizationConfig and a list of PointCloud Volume data.
required | Array of objects (CreatePointCloudVolumeContextualizationList) [ 1 .. 100 ] items |
required | object (DmsContextualizationConfig) |
Responses
Request samples
- Payload
{- "items": [
- {
- "assetInstanceId": {
- "space": "string",
- "externalId": "string"
}, - "volumeReference": "string",
- "volume": {
- "type": "box",
- "version": "1.0.0",
- "data": [
- 0.1
]
}
}
], - "dmsContextualizationConfig": {
- "object3DSpace": "string",
- "contextualizationSpace": "string",
- "revisionInstanceId": {
- "space": "string",
- "externalId": "string"
}
}
}Response samples
- 200
- 400
{ }Delete 360 Image contextualization
Deletes the specified Image360Annotation for the referenced image 360 revision.
Authorizations:
Request Body schema: application/json
The array of unique Image360Annotation instances, and the dmsContextualizationConfig.
required | Array of objects (DeleteImage360AnnotationContextualizationList) [ 1 .. 100 ] items |
required | object (DmsContextualizationConfig) |
Responses
Request samples
- Payload
{- "items": [
- {
- "image360Annotation": {
- "instanceId": {
- "space": "string",
- "externalId": "string"
}
}
}
], - "dmsContextualizationConfig": {
- "object3DSpace": "string",
- "contextualizationSpace": "string",
- "revisionInstanceId": {
- "space": "string",
- "externalId": "string"
}
}
}Response samples
- 200
- 400
{ }Delete Point Cloud Volume contextualization
Deletes the specified volumeReferences for the referenced point cloud revision.
Authorizations:
Request Body schema: application/json
The array of unique volumeReferences, and the dmsContextualizationConfig.
required | Array of objects (DeletePointCloudVolumeContextualizationList) [ 1 .. 100 ] items |
required | object (DmsContextualizationConfig) |
Responses
Request samples
- Payload
{- "items": [
- {
- "assetInstanceId": {
- "space": "string",
- "externalId": "string"
}, - "volumeReference": "string"
}
], - "dmsContextualizationConfig": {
- "object3DSpace": "string",
- "contextualizationSpace": "string",
- "revisionInstanceId": {
- "space": "string",
- "externalId": "string"
}
}
}Response samples
- 200
- 400
{ }Create a job using 3D source data
Creates a job to be run using a 3D source. Currently supported in data-modeling projects only. The user defines a dms instance they want the job to run against, and defines it as the source of the job. Inside the job you define the space a job will exist in, and its external id, this is not populated into dms. The job external id should be created by the client, and be unique. If the job result is stored in dms, it will be stored using the space of the job. A session nonce is required by the request.
Job types with supported job sources:
- Job Type: ImageTextDetection, Job Source type: Cognite360ImageCollection
Authorizations:
Request Body schema: application/json
The job with a given source. Currently supports only one job to be created at the time.
required | Array of ImageTextDetectionJob (object) or OptimizerJob (object) (CreateJobItem) = 1 items |
Responses
Request samples
- Payload
{- "items": [
- {
- "space": "string",
- "externalId": "string",
- "name": "string",
- "type": "ImageTextDetection",
- "source": {
- "type": "Cognite360ImageCollection",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}
}, - "configuration": { },
- "nonce": "string"
}
]
}Response samples
- 201
- 400
{- "items": [
- {
- "space": "string",
- "externalId": "string",
- "name": "string",
- "type": "ImageTextDetection",
- "source": {
- "type": "Cognite360ImageCollection",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}
}, - "configuration": { },
- "status": "Scheduled",
- "createdAt": 0
}
]
}Delete jobs
Delete jobs in your project. The job instance results won't be deleted by this operation.
Authorizations:
Request Body schema: application/json
List of space and externalIds for jobs you want to delete
required | Array of objects (JobIdentifier) |
Responses
Request samples
- Payload
{- "items": [
- {
- "space": "string",
- "externalId": "string"
}
]
}Response samples
- 200
- 400
{ }List Job Result Rejections
A list of internal keys that are to be considered rejected
Authorizations:
Request Body schema: application/json
The Job space and externalId and the ResultInstanceId which you want the rejections from
required | object (JobIdentifier) |
required | object (InstanceReference) |
| cursor | string |
Responses
Request samples
- Payload
{- "job": {
- "space": "string",
- "externalId": "string"
}, - "result": {
- "instanceId": {
- "space": "string",
- "externalId": "string"
}
}, - "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo"
}Response samples
- 200
- 400
{- "items": [
- {
- "rejectedKey": "string"
}
], - "nextCursor": "string"
}List Job Results
List the results of a job
Authorizations:
Request Body schema: application/json
The job space and externalId for the job you want results for
required | object (JobIdentifier) |
| cursor | string |
Responses
Request samples
- Payload
{- "job": {
- "space": "string",
- "externalId": "string"
}, - "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo"
}Response samples
- 200
- 400
{- "items": [
- {
- "type": "CogniteFile",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}
}
], - "nextCursor": "string"
}List jobs
List jobs for your project.
Authorizations:
Request Body schema: application/json
A cursor for paginating the list of jobs.
| cursor | string |
Responses
Request samples
- Payload
{- "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo"
}Response samples
- 200
- 400
{- "items": [
- {
- "space": "string",
- "externalId": "string",
- "name": "string",
- "type": "ImageTextDetection",
- "source": {
- "type": "Cognite360ImageCollection",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}
}, - "configuration": { },
- "status": "Scheduled",
- "createdAt": 0
}
], - "nextCursor": "string"
}Update Job Result Rejections
Job Instance Results have internal unique keys you can reject to allow yourself to filter away job results items you are no longer interested in
Authorizations:
Request Body schema: application/json
The Job space and externalId and the ResultInstanceId with the operation you want to perform on the result.
Only one operation can be done at the time:
- add
- remove
required | object (JobIdentifier) |
required | object (InstanceReference) |
| add required | Array of strings |
Responses
Request samples
- Payload
{- "job": {
- "space": "string",
- "externalId": "string"
}, - "result": {
- "instanceId": {
- "space": "string",
- "externalId": "string"
}
}, - "add": [
- "string"
]
}Response samples
- 200
- 400
{ }Endpoints for initiating and managing document parsing jobs within a project context.
List Parsing Jobs (INTERNAL)
List parsing jobs.
Authorizations:
query Parameters
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 1000 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Response samples
- 200
{- "items": [
- {
- "jobId": 123,
- "createdTimestamp": 1730204346000,
- "updatedTimestamp": 1730204346000,
- "viewConfig": {
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "node": {
- "externalId": "string",
- "space": "string"
}, - "status": {
- "job": "Queued",
- "view": "instance_updated",
- "validation": "not_ready"
}, - "files": [
- {
- "fileId": 1234
}
], - "result": {
- "resultSchema": {
- "property1": { },
- "property2": { }
}, - "viewConfig": {
- "space": "string",
- "externalId": "string",
- "version": "string",
- "description": "string",
- "name": "string",
- "title": "string"
}, - "scores": {
- "completenessScore": {
- "error_count": 0,
- "score": 0.1,
- "status": "string"
}, - "typeScore": {
- "error_count": 0,
- "score": 0.1,
- "status": "string"
}
}, - "rawResponses": {
- "property1": {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0,
- "otherAnswers": [
- {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0
}
]
}, - "property2": {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0,
- "otherAnswers": [
- {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0
}
]
}
}, - "data": {
- "property1": {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0,
- "otherAnswers": [
- {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0
}
]
}, - "property2": {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0,
- "otherAnswers": [
- {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0
}
]
}
}
}, - "errorMessage": "string"
}
], - "nextCursor": "string"
}Retrieve Jobs by Job Ids (INTERNAL)
Retrieve parsing jobs by job ids.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects |
Responses
Request samples
- Payload
{- "items": [
- {
- "jobId": 123
}
]
}Response samples
- 200
{- "items": [
- {
- "jobId": 123,
- "createdTimestamp": 1730204346000,
- "updatedTimestamp": 1730204346000,
- "viewConfig": {
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "node": {
- "externalId": "string",
- "space": "string"
}, - "status": {
- "job": "Queued",
- "view": "instance_updated",
- "validation": "not_ready"
}, - "files": [
- {
- "fileId": 1234
}
], - "result": {
- "resultSchema": {
- "property1": { },
- "property2": { }
}, - "viewConfig": {
- "space": "string",
- "externalId": "string",
- "version": "string",
- "description": "string",
- "name": "string",
- "title": "string"
}, - "scores": {
- "completenessScore": {
- "error_count": 0,
- "score": 0.1,
- "status": "string"
}, - "typeScore": {
- "error_count": 0,
- "score": 0.1,
- "status": "string"
}
}, - "rawResponses": {
- "property1": {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0,
- "otherAnswers": [
- {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0
}
]
}, - "property2": {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0,
- "otherAnswers": [
- {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0
}
]
}
}, - "data": {
- "property1": {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0,
- "otherAnswers": [
- {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0
}
]
}, - "property2": {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0,
- "otherAnswers": [
- {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0
}
]
}
}
}, - "errorMessage": "string"
}
], - "nextCursor": "string"
}Start a Document Parsing Job (INTERNAL)
Start a document parsing job. The job will parse the data from the provided files and create a view instance with the extracted data.
Authorizations:
Request Body schema: application/jsonrequired
required | object (ViewConfig) The view the job is based on. |
required | Array of objects or objects or objects (DocumentParserFileReference) |
object (Node) The node ID where the job results. |
Responses
Request samples
- Payload
{- "viewConfig": {
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "files": [
- {
- "fileId": 1234
}
], - "node": {
- "externalId": "string",
- "space": "string"
}
}Response samples
- 202
{- "createdTimestamp": 1730204346000,
- "jobId": 123,
- "status": "Queued"
}Write Results to Data Models (INTERNAL)
Write results to data models.
Authorizations:
Request Body schema: application/jsonrequired
| jobId required | integer <int64> (JobId) Contextualization job ID. |
required | object (RawResponses) A dictionary where each key represents a property name (e.g., 'operatingPressure') and the value is a 'RawResponseItem' schema. |
object (Node) The node ID where the job results. |
Responses
Request samples
- Payload
{- "jobId": 123,
- "data": {
- "property1": {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0,
- "otherAnswers": [
- {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0
}
]
}, - "property2": {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0,
- "otherAnswers": [
- {
- "fileId": 0,
- "pageNum": 0,
- "propertyId": "string",
- "spatialData": {
- "xMax": 0.1,
- "xMin": 0.1,
- "yMax": 0.1,
- "yMin": 0.1
}, - "value": { },
- "selectedAnswerIndex": 0
}
]
}
}, - "node": {
- "externalId": "string",
- "space": "string"
}
}Response samples
- 200
{- "items": [
- {
- "jobId": 123,
- "viewStatus": "instance_updated",
- "node": {
- "externalId": "string",
- "space": "string"
}
}
]
}Run an instant parsing job for a file
Start an instant parsing job on a file to detect diagram symbols based on the specified library. Parsed outputs do not persist.
Authorizations:
Request Body schema: application/jsonrequired
Specifies the library to use when instant parsing the given file.
required | object (DocumentIdentifier) |
| libraryId required | string (CogniteExternalId) <= 255 characters The external ID of a library for parsing |
Responses
Request samples
- Payload
{- "document": {
- "fileId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "pageNumber": 0
}, - "libraryId": "my.known.id"
}Response samples
- 200
- 400
{- "entities": [
- {
- "externalId": "my.known.id",
- "pathIds": [
- "string"
], - "symbolId": "my.known.id"
}
], - "message": "string",
- "status": "Failed"
}Run parsing for files
Start a parsing job on files to detect their symbols and connections.
Authorizations:
Request Body schema: application/jsonrequired
Specifies the library to use when parsing the given files.
required | Array of objects (DocumentIdentifier) [ 1 .. 100 ] items |
| libraryId required | string (CogniteExternalId) <= 255 characters The external ID of a library for parsing |
| nonce required | string Nonce parameter |
Responses
Request samples
- Payload
{- "documents": [
- {
- "fileId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "pageNumber": 0
}
], - "libraryId": "my.known.id",
- "nonce": "string"
}Response samples
- 200
- 400
{- "items": [
- "my.known.id"
]
}Run parsing with tag detection for files
A parsing job will be started on the files to detect their entities and connections and map assets.
Authorizations:
path Parameters
| project required | string Example: publicdata The CDF project name, equal to the project variable in the server URL. |
Request Body schema: application/jsonrequired
Defines parsing options needed for symbol and tag detection jobs.
required | Array of objects (DocumentIdentifier) [ 1 .. 100 ] items |
required | object (DetectTagsResourceFilter) Map of filters for DMS list operations used to load assets and files |
required | object (ExternalId) The externalId of a library to use for parsing |
| minTokens | integer Each detected item must match the detected entity on at least this number of tokens. A token is a substring of consecutive letters or digits. |
| nonce required | string Session nonce value |
| partialMatch | boolean Allow partial (fuzzy) matching of entities in the engineering diagrams. Creates a match only when it is possible to do so unambiguously. |
| searchField | string This field determines the string to search for and to identify object entities. |
Responses
Request samples
- Payload
{- "documents": [
- {
- "fileId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "pageNumber": 0
}
], - "filters": {
- "Asset": { },
- "File": { }
}, - "libraryId": {
- "externalId": "my.known.id"
}, - "minTokens": 0,
- "nonce": "string",
- "partialMatch": true,
- "searchField": "string"
}Response samples
- 200
- 400
{- "items": [
- "my.known.id"
]
}Copy library
Creates a new library by copying an existing library, including all its symbols and geometries.
Authorizations:
path Parameters
| libraryId required | string (CogniteExternalId) <= 255 characters Example: my.known.id External ID of a library |
Request Body schema: application/jsonrequired
Name of the new library
| name required | string The name of the copied library |
Responses
Request samples
- Payload
{- "name": "string"
}Response samples
- 200
- 400
{- "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "lastUpdatedTime": 1730204346000,
- "name": "string",
- "scope": "Global",
- "symbols": [
- {
- "assetTypeId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "geometries": [
- {
- "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "lastUpdatedTime": 1730204346000,
- "paths": [
- {
- "id": "string",
- "d": "string",
- "styleId": "string"
}
], - "symbolId": "my.known.id"
}
], - "lastUpdatedTime": 1730204346000,
- "libraryId": "my.known.id"
}
]
}Create libraries
Create libraries.
Authorizations:
Request Body schema: application/jsonrequired
Libraries to create.
required | Array of objects (LibraryCreateDraft) [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "lastUpdatedTime": 1730204346000,
- "name": "string",
- "scope": "Global"
}
]
}Delete libraries
Delete up to 100 libraries by specifying their IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of libraries IDs to delete.
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
]
}Response samples
- 200
- 400
{- "items": [
- "my.known.id"
]
}Get a library with symbols
Returns a single library with all its symbols and geometries.
Authorizations:
path Parameters
| libraryId required | string (CogniteExternalId) <= 255 characters Example: my.known.id External ID of a library |
Responses
Response samples
- 200
- 400
{- "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "lastUpdatedTime": 1730204346000,
- "name": "string",
- "scope": "Global",
- "symbols": [
- {
- "assetTypeId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "geometries": [
- {
- "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "lastUpdatedTime": 1730204346000,
- "paths": [
- {
- "id": "string",
- "d": "string",
- "styleId": "string"
}
], - "symbolId": "my.known.id"
}
], - "lastUpdatedTime": 1730204346000,
- "libraryId": "my.known.id"
}
]
}List libraries
List all libraries defined in the current project.
Authorizations:
query Parameters
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "lastUpdatedTime": 1730204346000,
- "name": "string",
- "scope": "Global"
}
], - "nextCursor": "string"
}Retrieve libraries
Retrieve up to 100 libraries by specifying their IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of IDs for the libraries to return.
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "lastUpdatedTime": 1730204346000,
- "name": "string",
- "scope": "Global"
}
]
}Update libraries
Update the properties of a set of libraries.
Authorizations:
Request Body schema: application/jsonrequired
List of libraries to be updated.
required | Array of objects (LibraryUpdateItem) [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id",
- "update": {
- "name": "string"
}
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "lastUpdatedTime": 1730204346000,
- "name": "string",
- "scope": "Global"
}
]
}Create symbols
Create symbols
Authorizations:
Request Body schema: application/jsonrequired
List of symbols to create.
required | Array of objects (SymbolCreateDraft) [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "assetTypeId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "externalId": "my.known.id",
- "libraryId": "my.known.id"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "assetTypeId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "lastUpdatedTime": 1730204346000,
- "libraryId": "my.known.id"
}
]
}Delete symbols
Delete up to 100 symbols by specifying their IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of symbols IDs to delete.
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
]
}Response samples
- 200
- 400
{- "items": [
- "my.known.id"
]
}List symbols
List all symbols defined in the current project.
Authorizations:
query Parameters
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| libraryId | string (CogniteExternalId) <= 255 characters Example: libraryId=my.known.id Retrieve items related to this library |
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "assetTypeId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "lastUpdatedTime": 1730204346000,
- "libraryId": "my.known.id"
}
], - "nextCursor": "string"
}Retrieve symbols
Retrieve up to 100 symbols by specifying their IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of IDs for the symbols to return.
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "assetTypeId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "lastUpdatedTime": 1730204346000,
- "libraryId": "my.known.id"
}
]
}Update symbols
Update the properties of a set of symbols
Authorizations:
Request Body schema: application/jsonrequired
List of symbols to be updated.
required | Array of objects (SymbolUpdateItem) [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id",
- "update": {
- "assetTypeId": {
- "space": "string",
- "externalId": "my.known.id"
}
}
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "assetTypeId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "lastUpdatedTime": 1730204346000,
- "libraryId": "my.known.id"
}
]
}Create geometries
Create geometries.
Authorizations:
Request Body schema: application/jsonrequired
Geometries to create.
required | Array of objects (GeometryCreateDraft) [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id",
- "paths": [
- {
- "id": "string",
- "d": "string",
- "styleId": "string"
}
], - "symbolId": "my.known.id"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "lastUpdatedTime": 1730204346000,
- "paths": [
- {
- "id": "string",
- "d": "string",
- "styleId": "string"
}
], - "symbolId": "my.known.id"
}
]
}Delete geometries
Delete up to 100 geometries by specifying their IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of geometry IDs to delete.
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
]
}Response samples
- 200
- 400
{- "items": [
- "my.known.id"
]
}List geometries
List all geometries (also called variants in documentation) defined in the current project.
Authorizations:
query Parameters
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| symbolId | string (CogniteExternalId) <= 255 characters Example: symbolId=my.known.id Retrieve items related to the symbol |
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "lastUpdatedTime": 1730204346000,
- "paths": [
- {
- "id": "string",
- "d": "string",
- "styleId": "string"
}
], - "symbolId": "my.known.id"
}
], - "nextCursor": "string"
}Retrieve geometries
Retrieve up to 100 geometries by specifying their IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of IDs for the geometries to return.
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "lastUpdatedTime": 1730204346000,
- "paths": [
- {
- "id": "string",
- "d": "string",
- "styleId": "string"
}
], - "symbolId": "my.known.id"
}
]
}Update geometries
Update the properties of a set of geometries
Authorizations:
Request Body schema: application/jsonrequired
List of geometries to be updated.
required | Array of objects (GeometryUpdateItem) [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id",
- "update": {
- "paths": [
- {
- "id": "string",
- "d": "string",
- "styleId": "string"
}
]
}
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "lastUpdatedTime": 1730204346000,
- "paths": [
- {
- "id": "string",
- "d": "string",
- "styleId": "string"
}
], - "symbolId": "my.known.id"
}
]
}Filter diagrams
Filter and retrieve up to 100 diagrams by specifying their properties.
Authorizations:
Request Body schema: application/jsonrequired
Body contains the properties to filter on.
Array of objects (DmsId) DMS identifier of a file the diagram is parsed from | |
| libraryId | Array of strings (CogniteExternalId) [ items <= 255 characters ] The external ID of the library the diagram is parsed with |
| pageNumber | Array of integers The page number of a file the diagram is parsed from |
| status | Array of strings (ParseStatus) Items Enum: "Failed" "InProgress" "InQueue" "Pending" "Success" Parsing status of a diagram |
Responses
Request samples
- Payload
[- {
- "fileId": [
- {
- "space": "string",
- "externalId": "my.known.id"
}
], - "libraryId": [
- "my.known.id"
], - "pageNumber": [
- 0
], - "status": [
- "Failed"
]
}
]Response samples
- 200
- 400
{- "items": [
- {
- "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "fileId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "lastUpdatedTime": 1730204346000,
- "libraryId": "my.known.id",
- "message": "string",
- "pageNumber": 0,
- "status": "Failed"
}
]
}Get an extended diagram by external id
Get diagram information and its parsed outputs using the diagram ID. The parsed output includes all diagram entities and their connections extracted during the file parsing process.
Authorizations:
path Parameters
| diagramId required | string (CogniteExternalId) <= 255 characters Example: my.known.id External ID of a diagram |
Responses
Response samples
- 200
- 400
{- "connections": [
- {
- "createdTime": 1730204346000,
- "diagramId": "my.known.id",
- "endNodeId": "my.known.id",
- "externalId": "my.known.id",
- "isUserDetected": true,
- "lastUpdatedTime": 1730204346000,
- "startNodeId": "my.known.id"
}
], - "createdTime": 1730204346000,
- "entities": [
- {
- "annotationId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "assetId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "createdTime": 1730204346000,
- "diagramId": "my.known.id",
- "externalId": "my.known.id",
- "isAssetVerified": true,
- "isUserDetected": true,
- "lastUpdatedTime": 1730204346000,
- "pathIds": [
- "string"
], - "symbolId": "my.known.id"
}
], - "externalId": "my.known.id",
- "fileId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "lastUpdatedTime": 1730204346000,
- "libraryId": "my.known.id",
- "pageNumber": 0,
- "message": "string",
- "status": "Failed"
}Get an extended diagram by file reference
Get diagram information and its parsed outputs using its related fileId and pageNumber. The parsed output includes all diagram entities and their connections extracted during the file parsing process.
Authorizations:
path Parameters
| fileSpace required | string A DMS space where the files reside |
| fileExternalId required | string Retrieve data related to a file |
| pageNumber required | integer The file's page number |
Responses
Response samples
- 200
- 400
{- "connections": [
- {
- "createdTime": 1730204346000,
- "diagramId": "my.known.id",
- "endNodeId": "my.known.id",
- "externalId": "my.known.id",
- "isUserDetected": true,
- "lastUpdatedTime": 1730204346000,
- "startNodeId": "my.known.id"
}
], - "createdTime": 1730204346000,
- "entities": [
- {
- "annotationId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "assetId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "createdTime": 1730204346000,
- "diagramId": "my.known.id",
- "externalId": "my.known.id",
- "isAssetVerified": true,
- "isUserDetected": true,
- "lastUpdatedTime": 1730204346000,
- "pathIds": [
- "string"
], - "symbolId": "my.known.id"
}
], - "externalId": "my.known.id",
- "fileId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "lastUpdatedTime": 1730204346000,
- "libraryId": "my.known.id",
- "pageNumber": 0,
- "message": "string",
- "status": "Failed"
}Get an extended diagram with paths by external id
Get a single diagram containing entities, connections, and SVG data by using its external id
Authorizations:
path Parameters
| diagramId required | string (CogniteExternalId) <= 255 characters Example: my.known.id External ID of a diagram |
query Parameters
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Response samples
- 200
- 400
{- "connections": [
- {
- "createdTime": 1730204346000,
- "diagramId": "my.known.id",
- "endNodeId": "my.known.id",
- "externalId": "my.known.id",
- "isUserDetected": true,
- "lastUpdatedTime": 1730204346000,
- "startNodeId": "my.known.id"
}
], - "createdTime": 1730204346000,
- "entities": [
- {
- "annotationId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "assetId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "createdTime": 1730204346000,
- "diagramId": "my.known.id",
- "externalId": "my.known.id",
- "isAssetVerified": true,
- "isUserDetected": true,
- "lastUpdatedTime": 1730204346000,
- "paths": [
- {
- "id": "string",
- "d": "string",
- "styleId": "string"
}
], - "symbolId": "my.known.id"
}
], - "externalId": "my.known.id",
- "fileId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "height": "string",
- "lastUpdatedTime": 1730204346000,
- "libraryId": "my.known.id",
- "message": "string",
- "pageNumber": 0,
- "status": "Failed",
- "viewBox": "string",
- "width": "string"
}List diagrams
List all diagrams defined in the current project.
Authorizations:
query Parameters
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "fileId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "lastUpdatedTime": 1730204346000,
- "libraryId": "my.known.id",
- "message": "string",
- "pageNumber": 0,
- "status": "Failed"
}
], - "nextCursor": "string"
}Retrieve diagrams
Retrieve up to 100 diagrams by specifying their external IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of IDs for the diagrams to return.
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "createdTime": 1730204346000,
- "externalId": "my.known.id",
- "fileId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "lastUpdatedTime": 1730204346000,
- "libraryId": "my.known.id",
- "message": "string",
- "pageNumber": 0,
- "status": "Failed"
}
]
}Create diagram entities
Create diagram entities.
Authorizations:
Request Body schema: application/jsonrequired
Diagram entities to create.
required | Array of objects (EntityCreateDraft) [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "annotationId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "assetId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "diagramId": "my.known.id",
- "externalId": "my.known.id",
- "isAssetVerified": true,
- "isUserDetected": true,
- "pathIds": [
- "string"
], - "symbolId": "my.known.id"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "annotationId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "assetId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "createdTime": 1730204346000,
- "diagramId": "my.known.id",
- "externalId": "my.known.id",
- "isAssetVerified": true,
- "isUserDetected": true,
- "lastUpdatedTime": 1730204346000,
- "pathIds": [
- "string"
], - "symbolId": "my.known.id"
}
]
}Delete diagram entities
Delete up to 100 diagram entities by specifying their IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of diagram entity IDs to delete.
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
]
}Response samples
- 200
- 400
{- "items": [
- "my.known.id"
]
}List diagram entities
List all diagram entities defined for the diagram specified by the diagramId parameter.
Authorizations:
query Parameters
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| diagramId | string (CogniteExternalId) <= 255 characters Example: diagramId=my.known.id Retrieve items related to the diagram |
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "annotationId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "assetId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "createdTime": 1730204346000,
- "diagramId": "my.known.id",
- "externalId": "my.known.id",
- "isAssetVerified": true,
- "isUserDetected": true,
- "lastUpdatedTime": 1730204346000,
- "pathIds": [
- "string"
], - "symbolId": "my.known.id"
}
], - "nextCursor": "string"
}Retrieve diagram entities
Retrieve up to 100 diagram entities by specifying their IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of IDs for the diagram entities to return.
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "annotationId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "assetId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "createdTime": 1730204346000,
- "diagramId": "my.known.id",
- "externalId": "my.known.id",
- "isAssetVerified": true,
- "isUserDetected": true,
- "lastUpdatedTime": 1730204346000,
- "pathIds": [
- "string"
], - "symbolId": "my.known.id"
}
]
}Update diagram entities
Update the properties of a set of diagram entities
Authorizations:
Request Body schema: application/jsonrequired
List of diagram entities to be updated.
required | Array of objects (EntityUpdateItem) [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id",
- "update": {
- "annotationId": { },
- "assetId": { },
- "isAssetVerified": true,
- "isUserDetected": true
}
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "annotationId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "assetId": {
- "space": "string",
- "externalId": "my.known.id"
}, - "createdTime": 1730204346000,
- "diagramId": "my.known.id",
- "externalId": "my.known.id",
- "isAssetVerified": true,
- "isUserDetected": true,
- "lastUpdatedTime": 1730204346000,
- "pathIds": [
- "string"
], - "symbolId": "my.known.id"
}
]
}Create connections
Create connections between symbols in parsed diagrams.
Authorizations:
Request Body schema: application/jsonrequired
Connections to create.
required | Array of objects (ConnectionCreateDraft) [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "diagramId": "my.known.id",
- "endNodeId": "my.known.id",
- "isUserDetected": true,
- "startNodeId": "my.known.id"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "createdTime": 1730204346000,
- "diagramId": "my.known.id",
- "endNodeId": "my.known.id",
- "externalId": "my.known.id",
- "isUserDetected": true,
- "lastUpdatedTime": 1730204346000,
- "startNodeId": "my.known.id"
}
]
}Delete connections
Delete up to 100 connections by specifying their IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of connections IDs to delete.
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
]
}Response samples
- 200
- 400
{- "items": [
- "my.known.id"
]
}List connections
List all connections defined in the current project.
Authorizations:
query Parameters
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| diagramId | string (CogniteExternalId) <= 255 characters Example: diagramId=my.known.id Retrieve items related to the diagram |
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "createdTime": 1730204346000,
- "diagramId": "my.known.id",
- "endNodeId": "my.known.id",
- "externalId": "my.known.id",
- "isUserDetected": true,
- "lastUpdatedTime": 1730204346000,
- "startNodeId": "my.known.id"
}
], - "nextCursor": "string"
}Retrieve connections
Retrieve up to 100 connections by specifying their IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of IDs for the connections to return.
required | Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "createdTime": 1730204346000,
- "diagramId": "my.known.id",
- "endNodeId": "my.known.id",
- "externalId": "my.known.id",
- "isUserDetected": true,
- "lastUpdatedTime": 1730204346000,
- "startNodeId": "my.known.id"
}
]
}Get SVG data by diagramId
Get the SVG data of a file by externalId of a diagram.
Authorizations:
path Parameters
| diagramId required | string (CogniteExternalId) <= 255 characters Example: my.known.id External ID of a diagram |
Responses
Response samples
- 200
- 400
{- "height": 0,
- "paths": {
- "property1": {
- "id": "string",
- "d": "string",
- "styleId": "string"
}, - "property2": {
- "id": "string",
- "d": "string",
- "styleId": "string"
}
}, - "pathStyles": {
- "property1": {
- "fill": "string",
- "fillOpacity": "string",
- "fillRule": "nonzero",
- "stroke": "string",
- "strokeDasharray": "string",
- "strokeDashoffset": "string",
- "strokeLinecap": "butt",
- "strokeLinejoin": "bevel",
- "strokeMiterlimit": "string",
- "strokeOpacity": "string",
- "strokeWidth": "string"
}, - "property2": {
- "fill": "string",
- "fillOpacity": "string",
- "fillRule": "nonzero",
- "stroke": "string",
- "strokeDasharray": "string",
- "strokeDashoffset": "string",
- "strokeLinecap": "butt",
- "strokeLinejoin": "bevel",
- "strokeMiterlimit": "string",
- "strokeOpacity": "string",
- "strokeWidth": "string"
}
}, - "viewBox": "string",
- "width": 0
}Get SVG data by file reference
Get the SVG data of a file by file instanceId and pageNumber.
Authorizations:
path Parameters
| fileSpace required | string A DMS space where the files reside |
| fileExternalId required | string Retrieve data related to a file |
| pageNumber required | integer The file's page number |
Responses
Response samples
- 200
- 400
{- "height": 0,
- "paths": {
- "property1": {
- "id": "string",
- "d": "string",
- "styleId": "string"
}, - "property2": {
- "id": "string",
- "d": "string",
- "styleId": "string"
}
}, - "pathStyles": {
- "property1": {
- "fill": "string",
- "fillOpacity": "string",
- "fillRule": "nonzero",
- "stroke": "string",
- "strokeDasharray": "string",
- "strokeDashoffset": "string",
- "strokeLinecap": "butt",
- "strokeLinejoin": "bevel",
- "strokeMiterlimit": "string",
- "strokeOpacity": "string",
- "strokeWidth": "string"
}, - "property2": {
- "fill": "string",
- "fillOpacity": "string",
- "fillRule": "nonzero",
- "stroke": "string",
- "strokeDasharray": "string",
- "strokeDashoffset": "string",
- "strokeLinecap": "butt",
- "strokeLinejoin": "bevel",
- "strokeMiterlimit": "string",
- "strokeOpacity": "string",
- "strokeWidth": "string"
}
}, - "viewBox": "string",
- "width": 0
}Atlas AI agents use language models to solve specific industrial business needs, such as providing insights into historical and planned maintenance and analyzing time series data for root cause analysis.
An agent includes prompts with instructions, industry-relevant tools, and access to industrial data stored in the Cognite Data Fusion (CDF) knowledge graph.
A project can have a maximum of 30 agents. Each agent can have a maximum of 10 tools.
For more information about Atlas AI agents, see the Atlas AI documentation.
Add or update Atlas AI agents
Add or update (upsert) Atlas AI agents.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (Items) = 1 items A list of agents to create or update. |
Responses
Request samples
- Payload
{- "items": [
- {
- "description": "string",
- "externalId": "string",
- "instructions": "string",
- "model": "azure/o3",
- "name": "string",
- "tools": [ ]
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "createdTime": 0,
- "description": "string",
- "externalId": "string",
- "instructions": "string",
- "lastUpdatedTime": 0,
- "model": "azure/o3",
- "name": "string",
- "ownerId": "string",
- "tools": [ ]
}
]
}Delete agents
Delete agents with specific external IDs.
Authorizations:
Request Body schema: application/jsonrequired
| ignoreUnknownIds | boolean (Ignoreunknownids) Default: false If |
required | Array of objects (Items) = 1 items A list of agents to delete. |
Responses
Request samples
- Payload
{- "ignoreUnknownIds": false,
- "items": [
- {
- "externalId": "string"
}
]
}Response samples
- 200
- 400
{ }List agents
List agents defined in the project.
Authorizations:
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "createdTime": 0,
- "description": "string",
- "externalId": "string",
- "instructions": "string",
- "lastUpdatedTime": 0,
- "model": "azure/o3",
- "name": "string",
- "ownerId": "string",
- "tools": [ ]
}
]
}Retrieve agents by external ID
Retrieve agents by their external IDs. The response returns the agents in the same order as in the request.
Authorizations:
Request Body schema: application/jsonrequired
| ignoreUnknownIds | boolean (Ignoreunknownids) Default: false If |
required | Array of objects (Items) [ 1 .. 100 ] items A list of agent external IDs. |
Responses
Request samples
- Payload
{- "ignoreUnknownIds": false,
- "items": [
- {
- "externalId": "string"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "createdTime": 0,
- "description": "string",
- "externalId": "string",
- "instructions": "string",
- "lastUpdatedTime": 0,
- "model": "azure/o3",
- "name": "string",
- "ownerId": "string",
- "tools": [ ]
}
]
}Start a chat session with an agent
Begin a chat session with an agent. When a user submits a message, the agent responds using the language model and the associated tools.
This API is stateless, but you can continue conversations by including the cursor from the previous response in subsequent requests.
Providing the cursor allows the agent to maintain the context of the conversation and deliver more accurate responses.
When the cursor is provided, there is no need to include the previous message history in the messages field.
NOTE: Cursors are short-lived and may expire. Clients should not cache cursors or rely on them being available long-term.
Authorizations:
header Parameters
| content-type required | string (Content-Type) |
Request Body schema: application/jsonrequired
Array of objects (Actions) <= 10 items Custom tool calls that a client can inject. | |
| agentExternalId | string (Agentexternalid) ^[^\x00]{1,128}$ An external ID that uniquely identifies the agent. |
| agentId | string (Agentid) ^[^\x00]{1,128}$ Deprecated Deprecated: Use AgentExternalId instead. This field uniquely identifies the agent, but is deprecated and will be removed in a future release. If both AgentId and AgentExternalId are provided, AgentExternalId takes precedence. |
| cursor | string (Cursor) The cursor for continuing a multi-turn chat session. To maintain conversational context, this opaque string must be copied from the previous API response and passed in the next request. The cursor represents the server-side state and should be treated as ephemeral; do not modify or store it. To start a new conversation, this field should be omitted. |
required | Array of AgentChatMessageActionDTO (any) or AgentChatMessageUserRequest (object) (Messages) [ 1 .. 1000 ] items A list of one or multiple input items for the agent, which include various content types used to generate a response. |
Responses
Request samples
- Payload
{- "actions": [
- {
- "clientTool": {
- "description": "string",
- "name": "string",
- "parameters": {
- "description": "string",
- "properties": {
- "property1": {
- "additionalProperties": false,
- "default": "processing",
- "description": "The current status of the shipment. Must be one of the predefined values.",
- "enum": [
- "processing",
- "shipped",
- "delivered",
- "cancelled"
], - "examples": [
- "processing"
], - "format": "enum",
- "items": { },
- "maxItems": 3,
- "maxLength": 4,
- "maxProperties": 5,
- "maximum": 4,
- "minItems": 1,
- "minLength": 4,
- "minProperties": 1,
- "minimum": 4,
- "nullable": true,
- "pattern": "^(processing|shipped|delivered|cancelled)$",
- "properties": { },
- "propertyOrdering": [
- "processing",
- "shipped",
- "delivered",
- "cancelled"
], - "required": [ ],
- "title": "Shipping Status",
- "type": "string"
}, - "property2": {
- "additionalProperties": false,
- "default": "processing",
- "description": "The current status of the shipment. Must be one of the predefined values.",
- "enum": [
- "processing",
- "shipped",
- "delivered",
- "cancelled"
], - "examples": [
- "processing"
], - "format": "enum",
- "items": { },
- "maxItems": 3,
- "maxLength": 4,
- "maxProperties": 5,
- "maximum": 4,
- "minItems": 1,
- "minLength": 4,
- "minProperties": 1,
- "minimum": 4,
- "nullable": true,
- "pattern": "^(processing|shipped|delivered|cancelled)$",
- "properties": { },
- "propertyOrdering": [
- "processing",
- "shipped",
- "delivered",
- "cancelled"
], - "required": [ ],
- "title": "Shipping Status",
- "type": "string"
}
}, - "propertyOrdering": [
- "string"
], - "required": [
- "string"
], - "type": "object"
}
}, - "type": "clientTool"
}
], - "agentExternalId": "string",
- "agentId": "string",
- "cursor": "string",
- "messages": [
- {
- "actionId": "string",
- "content": {
- "text": "string",
- "type": "text"
}, - "data": [ ],
- "role": "action",
- "type": "clientTool"
}
]
}Response samples
- 200
- 400
{- "agentExternalId": "string",
- "agentId": "string",
- "response": {
- "cursor": "string",
- "messages": [
- {
- "actions": [
- {
- "actionId": "string",
- "clientTool": {
- "arguments": "string",
- "name": "string"
}, - "type": "clientTool"
}
], - "content": {
- "text": "string",
- "type": "text"
}, - "data": [
- {
- "instanceId": {
- "externalId": "string",
- "space": "string"
}, - "properties": {
- "property1": "string",
- "property2": "string"
}, - "type": "instance",
- "view": {
- "externalId": "string",
- "space": "string",
- "version": "string"
}
}
], - "reasoning": [
- {
- "content": [
- {
- "text": "string",
- "type": "text"
}
]
}
], - "role": "agent"
}
], - "type": "result"
}
}AI service availability (INTERNAL)
Use this API endpoint to retrieve information about the availability of AI API services in the current project.
Authorizations:
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "available": true,
- "defaultLanguageModel": "azure/gpt-4o",
- "name": "Chat completions",
- "path": "/ai/chat/completions",
- "supportedLanguageModels": [
- "azure/gpt-4o",
- "azure/gpt-4o-mini"
]
}
], - "languageModels": [
- {
- "earliestRetirementDate": 0,
- "maxOutputTokens": 0,
- "maxTokens": 0,
- "name": "string",
- "native": true
}
]
}Create chat completions (INTERNAL)
Generates chat completions from conversation message history.
Authorizations:
header Parameters
| content-type required | string (Content-Type) |
Request Body schema: application/jsonrequired
| maxTokens | integer (Maxtokens) > 0 Default: 2000 The maximum number of tokens to generate in the completion. The total token count of your prompt plus |
required | Array of objects (Messages) [ 1 .. 300 ] items The messages to generate chat completions for. |
| model | string (ValidLanguageModel) Enum: "azure/o3" "azure/o4-mini" "azure/gpt-4o" "azure/gpt-4o-mini" "azure/gpt-4.1" "azure/gpt-4.1-nano" "azure/gpt-4.1-mini" "azure/gpt-5" "azure/gpt-5-mini" "azure/gpt-5-nano" "gcp/gemini-2.5-pro" "gcp/gemini-2.5-flash" "aws/claude-4-sonnet" "aws/claude-4-opus" "aws/claude-4.1-opus" "aws/claude-3.5-sonnet" The name of the model to use. |
| stream | boolean (Stream) Default: false Specifies whether to stream back partial progress. |
| temperature | number (Temperature) Default: 0 The sampling temperature to use. Higher values mean the model will take more risks. Try 0.9 for more creative applications, and 0 for applications with a well-defined answer. |
ChatCompletionsToolChoice (object) or Toolchoice (string) (Toolchoice) Controls which (if any) tool the model calls. | |
Array of objects (Tools) [ 1 .. 20 ] items A list of tools the model can use. |
Responses
Request samples
- Payload
{- "maxTokens": 2000,
- "messages": [
- {
- "content": "string",
- "functionCall": {
- "arguments": "string",
- "name": "string"
}, - "name": "string",
- "role": "user",
- "tool_call_id": "string",
- "tool_calls": [
- {
- "function": {
- "arguments": "string",
- "name": "string"
}, - "id": "string",
- "type": "function"
}
]
}
], - "model": "azure/o3",
- "stream": false,
- "temperature": 0,
- "toolChoice": {
- "function": {
- "name": "string"
}, - "type": "function"
}, - "tools": [
- {
- "function": {
- "description": "Get the current weather for a specified location.",
- "name": "get_current_weather",
- "parameters": {
- "properties": {
- "location": {
- "description": "The city and state, for example, San Francisco, CA.",
- "type": "string"
}, - "unit": {
- "enum": [
- "celsius",
- "fahrenheit"
], - "type": "string"
}
}, - "required": [
- "location"
], - "type": "object"
}
}, - "type": "function"
}
]
}Response samples
- 200
- 400
{- "choices": [
- {
- "finish_reason": "string",
- "message": {
- "content": "string",
- "function_call": {
- "arguments": "string",
- "name": "string"
}, - "name": "string",
- "role": "user",
- "tool_call_id": "string",
- "tool_calls": [
- {
- "function": {
- "arguments": "string",
- "name": "string"
}, - "id": "string",
- "type": "function"
}
]
}
}
], - "created": 0,
- "model": "string",
- "usage": {
- "completion_tokens": 0,
- "prompt_tokens": 0,
- "total_tokens": 0
}
}Ask questions about one or more documents.
This API endpoint uses a language model to answer questions about documents. Provided with a natural language question and a list of files, the API returns a multi-part answer with references to the locations in the documents that were used to build the answer.
Limitations
- Currently, we only support PDF files.
- The PDF files can be a maximum of 400 pages long.
- You can only pass 100 files in a single request.
Authorizations:
header Parameters
| content-type required | string (Content-Type) |
Request Body schema: application/jsonrequired
| additionalContext | string (Additionalcontext) [ 10 .. 2048 ] characters Optional additional context that the model can use to improve its answer |
required | Array of DocumentInternalId (object) or DocumentExternalId (object) or DocumentInstanceId (object) (Fileids) [ 1 .. 100 ] items A list of file IDs, external IDs, or instance IDs pointing to PDF documents |
| ignoreUnknownIds | boolean (Ignoreunknownids) Default: false If |
| language | string (DocumentsLanguage) Default: "English" Enum: "Chinese" "Dutch" "English" "French" "German" "Italian" "Japanese" "Korean" "Latvian" "Norwegian" "Portuguese" "Spanish" "Swedish" The language in which the answer should be provided. |
| question required | string (Question) [ 1 .. 2048 ] characters The question to ask about the documents. |
Responses
Request samples
- Payload
{- "additionalContext": "stringstri",
- "fileIds": [
- {
- "id": 0
}
], - "ignoreUnknownIds": false,
- "language": "Chinese",
- "question": "string"
}Response samples
- 200
- 400
{- "content": [
- {
- "references": [
- {
- "externalId": "string",
- "fileId": 0,
- "fileName": "string",
- "instanceId": {
- "externalId": "string",
- "space": "string"
}, - "locations": [
- {
- "bottom": 0,
- "left": 0,
- "pageNumber": 0,
- "right": 0,
- "top": 0
}
]
}
], - "text": "string"
}
]
}Summarize documents.
Generates concise summaries for a list of input documents using a language model.
Authorizations:
header Parameters
| content-type required | string (Content-Type) |
Request Body schema: application/jsonrequired
| ignoreUnknownIds | boolean (Ignoreunknownids) Default: false If |
required | Array of DocumentInternalId (object) or DocumentExternalId (object) or DocumentInstanceId (object) (Items) = 1 items A list of documents to summarize. |
| language | string (DocumentsLanguage) Default: "English" Enum: "Chinese" "Dutch" "English" "French" "German" "Italian" "Japanese" "Korean" "Latvian" "Norwegian" "Portuguese" "Spanish" "Swedish" The language in which the answer should be provided. |
Responses
Request samples
- Payload
{- "ignoreUnknownIds": false,
- "items": [
- {
- "id": 0
}
], - "language": "Chinese"
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 0,
- "summary": "string"
}
]
}Generate Query completions (INTERNAL)
Generates Query completions with language models.
Authorizations:
header Parameters
| content-type required | string (Content-Type) |
Request Body schema: application/jsonrequired
| agentInstructions | string (Agentinstructions) Instructions for the agent to follow when generating the query. |
Array of objects (Chathistory) History of chat messages with author and message content. | |
required | Array of objects (Datamodels) [ 1 .. 80 ] items List of relevant data models. |
| prompt required | string (Prompt) [ 1 .. 2048 ] characters The prompt to generate query completions from. |
| stream | boolean (Stream) Default: true Specifies whether to stream back partial progress. |
| toolInstructions | string (Toolinstructions) Instructions for the tools to follow when generating the query. |
Responses
Request samples
- Payload
{- "agentInstructions": "string",
- "chatHistory": [
- {
- "author": "string",
- "message": "string"
}
], - "dataModels": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string",
- "viewExternalIds": [
- "string"
]
}
], - "prompt": "string",
- "stream": true,
- "toolInstructions": "string"
}Response samples
- 200
- 400
{- "aggregate": {
- "group_by": "string",
- "properties": { }
}, - "dataModelView": {
- "externalId": "string",
- "space": "string",
- "version": "string",
- "view": "string",
- "viewExternalIds": [
- "string"
]
}, - "filter": { },
- "limit": 0,
- "operation": "string",
- "properties": [
- "string"
], - "search": {
- "fields": [
- "string"
], - "query": "string"
}, - "sort": [
- {
- "direction": "ascending",
- "field": "string"
}
]
}Run search queries (INTERNAL)
This tool runs search queries
Authorizations:
header Parameters
| content-type required | string (Content-Type) |
Request Body schema: application/jsonrequired
object (AggregateObjectRequest) The aggregate object. This is required if the operation is 'aggregate'. | |
required | object (DataModelView) The relevant data model view from a specific data model. |
object (Filter) The filters to apply to the query. | |
| limit | integer (Limit) [ 1 .. 100 ] Default: 20 The limit of the query. |
| operation required | string (Operation) Enum: "list" "search" "aggregate" The query operation to complete. |
Array of strings or objects (Properties) The relevant properties for the data model view. | |
object (SearchObjectRequest) The search object. This is required if the operation is 'search'. | |
Array of objects (Sort) <= 2 items Default: [] The sort object. |
Responses
Request samples
- Payload
{- "aggregate": {
- "group_by": "string",
- "properties": {
- "avg": [
- "string"
], - "count": [
- "string"
], - "max": [
- "string"
], - "min": [
- "string"
], - "sum": [
- "string"
]
}
}, - "dataModelView": {
- "externalId": "string",
- "space": "string",
- "version": "string",
- "view": "string"
}, - "filter": { },
- "limit": 20,
- "operation": "list",
- "properties": [
- "string"
], - "search": {
- "fields": [
- "string"
], - "query": "string"
}, - "sort": [ ]
}Response samples
- 200
- 400
{- "items": [
- null
]
}Edit Python code (INTERNAL)
Edit Python code with language models.
Authorizations:
header Parameters
| content-type required | string (Content-Type) |
Request Body schema: application/jsonrequired
| currentCode required | string (Currentcode) <= 4096 characters The code to edit. |
| previousCodeContext | string (Previouscodecontext) <= 16384 characters The previously executed code. |
| prompt required | string (Prompt) [ 10 .. 2048 ] characters The query to be completed. |
Responses
Request samples
- Payload
{- "currentCode": "string",
- "previousCodeContext": "string",
- "prompt": "stringstri"
}Response samples
- 200
- 400
nullGenerate Python code completions (INTERNAL)
Generates completions for Python code with language models.
Authorizations:
header Parameters
| content-type required | string (Content-Type) |
Request Body schema: application/jsonrequired
| previousCodeContext | string (Previouscodecontext) <= 16384 characters The previously executed code. |
| prompt required | string (Prompt) [ 10 .. 2048 ] characters The query to be completed. |
Responses
Request samples
- Payload
{- "previousCodeContext": "string",
- "prompt": "stringstri"
}Response samples
- 200
- 400
nullCreates embedding vectors from text chunks using the specified model. (INTERNAL)
Creates embedding vectors from text chunks using the specified model.
Authorizations:
header Parameters
| content-type required | string (Content-Type) |
Request Body schema: application/jsonrequired
| dimensions | integer (Dimensions) The number of dimensions the resulting output embeddings should have. Only supported for certain models. |
| encodingFormat | string (EncodingFormat) Default: "float" Value: "float" The encoding for the document. Currently, we only support |
required | Array of objects (Items) [ 1 .. 100 ] items A list of items to create embeddings for. |
| model required | string (ValidEmbeddingModel) Enum: "azure/text-embedding-ada-002" "azure/text-embedding-3-small" "azure/text-embedding-3-large" The model to use for vectorization. |
Responses
Request samples
- Payload
{- "dimensions": 0,
- "encodingFormat": "float",
- "items": [
- {
- "text": "string"
}
], - "model": "azure/text-embedding-ada-002"
}Response samples
- 200
- 400
{- "dimensions": 0,
- "encodingFormat": "float",
- "items": [
- {
- "embedding": [
- 0
], - "text": "string"
}
], - "model": "azure/text-embedding-ada-002"
}Usage Metrics Data (INTERNAL)
Aggregates data from event storage using UTC timezone for all timestamps.
Authorizations:
Request Body schema: application/jsonrequired
| aggregate required | string (AggregateType) Value: "sum" The type of aggregation to perform on the metric data, for example, |
End (integer) or End (string) (End) The end time for the query. Accepts a Unix timestamp in milliseconds or relative time format like '7d-ago'. If omitted, defaults to the current time. | |
object (Filter-Input) Optional filter conditions for the metric data. Supports 'and' and 'not' clauses. | |
| granularity required | string (GranularityType) Enum: "day" "week" "month" "year" The time granularity to aggregate by, for example, day, week, month, or year. |
| group_by | Array of strings (Group By) Items Value: "source" An optional list of dimensions to group the results by, for example, source. |
| name required | string (MetricName) Value: "aiUnit" The name of the metric to query, for example, 'aiUnit'. |
required | Start (integer) or Start (string) (Start) The start time for the query. Accepts a Unix timestamp in milliseconds or a relative time format like '30d-ago', '1y-ago'. |
Responses
Request samples
- Payload
{- "aggregate": "sum",
- "filter": {
- "and": [
- {
- "property": "source",
- "value": "model"
}
]
}, - "granularity": "day",
- "group_by": [
- "source"
], - "name": "aiUnit",
- "start": "7d-ago"
}Response samples
- 200
- 400
{- "items": [
- {
- "datapoints": [
- {
- "timestamp": "2019-08-24T14:15:22Z",
- "value": 0
}
], - "filter": {
- "and": [
- {
- "property": "source",
- "value": "agentCall"
}
]
}, - "group_by": {
- "property1": "string",
- "property2": "string"
}
}
], - "truncated": true
}A document is a file that has been indexed by the document search engine. Every time a file is uploaded, updated or deleted in the Files API, it will also be scheduled for processing by the document search engine. After some processing, it will be possible to search for the file in the document search API.
The document search engine is able to extract content from a variety of document
types, and perform classification, contextualization and other operations on the
file. This extracted and derived information is made available in the form of a
Document object.
The document structure consists of a selection of derived fields, such as the
title, author and language of the document, plus some of the original fields
from the raw file. The fields from the raw file can be found in the
sourceFile structure. The derived fields are described in more detail below.
Derived fields
title
Some document types (such as PDFs) contain additional metadata fields. If the document contains its title as part of this metadata, this field will be populated with that title.
Note that we do not currently extract the title from the document content itself. If there is a need for this, we may consider adding such functionality in the future.
author
Similar to the title field, the author field is another field that can often be
extracted from the document's metadata.
producer
The producer field also exists in the document metadata. It contains information
about the software or the system that was used to create the document.
createdTime
The createdTime we assign to the document is not exactly the same as the one found
in the Files API. We first try to extract the created time from the document metadata.
If the document does not contain such a timestamp, we fall back to the time set in
the Files API.
mimeType
If there is a mime type set in on the file in the Files API, this field will be set to the same mime type. If there is no mime type set on the file, we will try to auto-detect it.
extension
This field contains the extension of the file, derived from the file name. For
instance, if the file name is My Document.docx, the extension field will contain
docx.
pageCount
Contains the number of pages in the document, if possible to determine.
type
The type field contains a high level file type, derived from the mime type. Mime
types are not that pleasant to look at, and not always easy to understand. That is
why we map the mime types into more user-friendly types. Below is the list of types
currently returned, but be aware that this list may be extended in the future.
Document: Document files from Microsoft Word or similar word processing software.PDF: PDF files.Spreadsheet: Files from Microsoft Excel or similar spreadsheet software.Presentation: Slides from Microsoft Powerpoint or similar.Image: Any kind of image such as PNG or JPG files.Video: Any kind of video such as MOV or MP4 files.Tabular data: Csv, tsv and other kinds of tabular data files.Plain text: Plain text files.Compressed: ZIP files and other kinds of compressed archive files.Script: Program code such as python or matlab.Other: Anything that doesn't fit in any of the above types.
geoLocation
If there is a geolocation set on the file in the Files API, then this field will contain the same geolocation. If there is no explicitly assigned geolocation, the document processing system will try to detect a location using two different techniques;
- We will extract locations from files that contain embedded GPS locations. Photos and videos often have this kind of metadata.
- We will look at related assets that have locations, and assign the same location(s) to the document.
File type support
We create a document for each uploaded file, but only derive data from certain files.
The following file types are eligible for further data extraction & enrichment:
- PDF files
- Spreadsheets, documents, and presentations from the Microsoft, Libre Office and macOS office suites
- Plain text files
- Images
Aggregate documents
The aggregation API lets you compute aggregated results on documents, such as getting the count of all documents in a project, checking different authors of documents in a project and the count of documents in each of those aggregations. By specifying an additional filter or search, you can aggregate only among documents matching the specified filter or search.
When you don't specify the aggregate field in the request
body, the default behavior is to return the count of all matched documents.
Supported aggregates
| Aggregate |
Description |
Example |
|---|---|---|
count | Count of documents matching the specified filters and search. |
|
cardinalityValues | Returns an approximate count of distinct values for the specified properties. |
|
cardinalityProperties | Returns an approximate count of
distinct properties for a given property path. Currently only implemented for the
["sourceFile", "metadata"] path. |
|
uniqueValues | Returns top unique values for specified properties (up to the
requested limit) and the count of each in the property specified in properties.
The list will have the highest count first. |
|
uniqueProperties | Returns top unique properties values for specified properties (up to the
requested limit) and the count of each in the property specified in properties.
The list will have the highest count first.
Currently, the |
|
Aggregate filtering
Only some aggregate types currently support
aggregateFilter
Aggregate filtering works directly on the aggregated result. While a normal filter filters relevant documents, aggregate filtering filters the aggregated bucket values. This is useful for e.g. listing metadata keys; while a normal filter will return all metadata keys for related documents, the aggregate filter can be used to reduce the aggregate result even further.
Tip: use both filter and aggregateFilter to potentially speed up queries, as the aggregateFilter is essentially a post filter.
Filter metadata keys by prefix
Here we only show metadata keys which starts with "car".
{
"aggregate": "uniqueProperties",
"properties": [{"property": ["sourceFile", "metadata"]}],
"aggregateFilter": {"prefix": {"value": "car"}}
}
Filter metadata values by prefix
Here we only show metadata values which starts with "ctx", for the given metadata key "car-codes".
{
"aggregate": "uniqueValues",
"properties": [{"property": ["sourceFile", "metadata", "car-codes"]}],
"aggregateFilter": {"prefix": {"value": "ctx"}}
}
Authorizations:
Request Body schema: application/json
object | |
(bool filters (and (object) or or (object) or not (object))) or (leaf filters (equals (object) or in (object) or containsAny (object) or containsAll (object) or range (object) or prefix (object) or search (object) or exists (object) or geojsonIntersects (object) or geojsonDisjoint (object) or geojsonWithin (object) or inAssetSubtree (object))) (DocumentFilter) | |
| aggregate | string Default: "count" Value: "count" Count of documents matching the specified filters and search. |
Responses
Request samples
- Payload
- Python SDK
{- "filter": {
- "equals": {
- "property": [
- "type"
], - "value": "PDF"
}
}, - "aggregate": "uniqueValues",
- "properties": [
- {
- "property": [
- "author"
]
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "count": 10
}
]
}Document status Deprecated
Documents status endpoint has moved out of alpha to beta, this version is now deprecated and will soon be removed. Check the index status for set of documents. Useful to check if a document is ready for search.
Authorizations:
header Parameters
| cdf-version | string Example: alpha cdf version header. Use this to specify the requested CDF release. |
Request Body schema: application/jsonrequired
A list of document ids you want status on
required | Array of objects |
| includeStatistics | boolean Default: false Whether or not to include statistics about the document. This gives additional insight such as the number of pages, number of vectors, etc. |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 1
}
], - "includeStatistics": false
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 1,
- "semanticSearch": {
- "status": "waiting",
- "reason": "string"
}, - "elements": {
- "status": "waiting",
- "reason": "string"
}, - "statistics": {
- "numberOfPages": 0,
- "numberOfVectors": 0
}
}
]
}List documents
Retrieves a list of the documents in a project. You can use filters to narrow down the list. Unlike the search endpoint, the pagination isn't restricted to 1000 documents in total, meaning this endpoint can be used to iterate through all the documents in your project.
For more information on how the filtering works, see the documentation for the search endpoint.
Authorizations:
Request Body schema: application/jsonrequired
Fields to be set for the list request.
(bool filters (and (object) or or (object) or not (object))) or (leaf filters (equals (object) or in (object) or containsAny (object) or containsAll (object) or range (object) or prefix (object) or search (object) or exists (object) or geojsonIntersects (object) or geojsonDisjoint (object) or geojsonWithin (object) or inAssetSubtree (object))) (DocumentFilter) | |
Array of objects (DocumentSortItem) = 1 items List of properties to sort by. Currently only supports 1 property. | |
| limit | integer <int32> [ 1 .. 1000 ] Default: 100 Maximum number of items per page. Use the cursor to get more pages. |
| cursor | string Cursor for paging through results. |
Responses
Request samples
- Payload
- Python SDK
{- "filter": {
- "and": [
- {
- "prefix": {
- "property": [
- "name"
], - "value": "Report"
}
}, - {
- "equals": {
- "property": [
- "type"
], - "value": "PDF"
}
}
]
}, - "sort": [
- {
- "order": "asc",
- "property": [
- "sourceFile",
- "name"
]
}
], - "limit": 100,
- "cursor": "string"
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 2384,
- "externalId": "haml001",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "title": "Hamlet",
- "author": "William Shakespeare",
- "producer": "string",
- "createdTime": 1519862400000,
- "modifiedTime": 1519958703000,
- "lastIndexedTime": 1521062805000,
- "mimeType": "text/plain",
- "extension": "pdf",
- "pageCount": 2,
- "type": "Document",
- "language": "en",
- "truncatedContent": "ACT I\nSCENE I. Elsinore. A platform before the castle.\n FRANCISCO at his post. Enter to him BERNARDO\nBERNARDO\n Who's there?\n",
- "assetIds": [
- 42,
- 101
], - "labels": [
- {
- "externalId": "my.known.id"
}
], - "sourceFile": {
- "name": "hamlet.txt",
- "directory": "plays/shakespeare",
- "source": "SubsurfaceConnectors",
- "mimeType": "application/octet-stream",
- "size": 1000,
- "hash": "23203f9264161714cdb8d2f474b9b641e6a735f8cea4098c40a3cab8743bd749",
- "assetIds": [ ],
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Point",
- "coordinates": [
- 10.74609,
- 59.91273
]
}, - "datasetId": 1,
- "securityCategories": [ ],
- "metadata": {
- "property1": "string",
- "property2": "string"
}
}, - "geoLocation": {
- "type": "Point",
- "coordinates": [
- 10.74609,
- 59.91273
]
}
}
], - "nextCursor": "string"
}Retrieve document content Deprecated
Returns extracted textual information for the given document.
The documents pipeline extracts up to 1MiB of textual information from each processed document.
The search and list endpoints truncate the textual content of each document, in order to reduce the size
of the returned payload. If you want the whole text for a document, you can use this endpoint.
The accept request header MUST be set to text/plain. Other values will
give an HTTP 406 error.
Authorizations:
path Parameters
| id required | integer <int64> (CogniteInternalId) [ 1 .. 9007199254740991 ] A server-generated ID for the object. |
Responses
Request samples
- Python SDK
content = client.documents.retrieve_content(id=123) from pathlib import Path with Path("my_file.txt").open("wb") as buffer: client.documents.retrieve_content_buffer(id=123, buffer=buffer)
Response samples
- 400
{- "error": {
- "code": 401,
- "message": "Could not authenticate.",
- "missing": [
- { }
], - "duplicated": [
- { }
]
}
}Retrieve document content
Returns extracted textual information for the given document.
The documents pipeline extracts up to 1MiB of textual information from each processed document. The search and list endpoints truncate the textual content of each document, in order to reduce the size of the returned payload. If you want the whole text for a document, you can use this endpoint.
The accept request header MUST be set to text/plain. Other values will
give an HTTP 406 error.
Authorizations:
Request Body schema: application/jsonrequired
Fields to be set for the content request.
| id required | integer <int64> (CogniteInternalId) [ 1 .. 9007199254740991 ] A server-generated ID for the object. |
Responses
Request samples
- Payload
{- "id": 1
}Response samples
- 400
{- "error": {
- "code": 401,
- "message": "Could not authenticate.",
- "missing": [
- { }
], - "duplicated": [
- { }
]
}
}Retrieve parsed document content
Returns parsed document content for the file.
Each document that is uploaded to CDF is OCR'ed and run through layout analysis, which detects titles, paragraphs and tables in the document. The textual content of the document is returned as a hierarchy of layout elements.
The high-level layout elements are again divided into lines and words. Each word has a bounding box for identifying which page it is found on, and where on the page.
Bounding boxes for paragraphs or lines are not provided, but can be easily calculated from the bounding boxes on the individual words.
Note that this endpoint only supports PDF files for now. Support for more file types will be added in the future.
This endpoint is in alpha and is available only when a cdf-version: YYYYMMDD-alpha header
is provided.
Authorizations:
header Parameters
| cdf-version | string Example: alpha cdf version header. Use this to specify the requested CDF release. |
Request Body schema: application/jsonrequired
Fields to be set for the content request.
| id required | integer <int64> (CogniteInternalId) [ 1 .. 9007199254740991 ] A server-generated ID for the object. |
| granularity | string Default: "words" Enum: "words" "elements" "lines" Adjust the level of detail in the response. |
Responses
Request samples
- Payload
{- "id": 1,
- "granularity": "words"
}Response samples
- 200
- 400
{- "elements": [
- {
- "text": "string",
- "page": 0,
- "left": 0,
- "right": 0,
- "top": 0,
- "bottom": 0
}
]
}Search for documents
This endpoint lets you search for documents by using advanced filters and free text queries. Free text queries are matched against the documents' filenames and contents.
Free text search
Boolean operators
The + symbol represents an AND operation, and the | symbol represents an OR.
Searching for lorem + ipsum will match documents containing both "lorem" AND "ipsum" in the filename or content.
Similarly, searching for lorem | ipsum will match documents containing either "lorem" OR "ipsum" in the filename or
content.
The default operator between the search keywords is AND.
That means that searching for two terms without any operator, for example, lorem ipsum, will
match documents containing both the words "lorem" and "ipsum" in the filename or content.
You can use the operator - to exclude documents containing a specific word.
For instance, the search lorem -ipsum will match documents that contain the word "lorem", but does NOT contain the
word "ipsum".
Phrases
Enclose multiple words inside double quotes " to group these words together.
Normally, the search query lorem ipsum will match not only "lorem ipsum" but also "lorem cognite ipsum",
and in general, there can be any number of words between the two words in the query.
The search query "lorem ipsum", however, will match only exactly "lorem ipsum" and not "lorem cognite ipsum".
Escape
To search for the special characters (+, |, -, ". \), escape with a preceding backslash \.
Ordering
When you search for a term, the endpoint tries to return the most relevant documents first, with less relevant documents further down the list. There are a few factors that determine the relevance of a document:
- If the search terms are found multiple times within a document, the relevance of that document is higher.
- For searches with multiple terms, documents containing all the terms are considered more relevant than documents containing only some.
- Matches of the terms in the filename field of the document are more relevant than matches in the document's content.
Examples
The following request will return documents matching the specified search query.
{
"search": {
"query": "cognite \"lorem ipsum\""
}
}
The following example combines a query with a filter.
The search request will return documents matching the search query, where externalId starts with "1".
The results will be ordered by how well they match the query string.
{
"search":{
"query":"cognite \"lorem ipsum\""
},
"filter":{
"prefix":{
"property":[
"externalId"
],
"value":"1"
}
}
}
Highlights
When you enable highlights for your search query, the response contains an additional highlight field for each search hit, including the highlighted fragments for your query matches. However, the result limit is 20 documents due to the operation costs.
Filtering
Filtering uses a special JSON filtering language.
It's quite flexible and consists of a number of different "leaf" filters, which can be combined arbitrarily using the boolean clauses and, or, and not.
Supported leaf filters
| Leaf filter |
Supported fields |
Description |
|---|---|---|
equals | Non-array type fields | Only includes results that are equal to the specified value.
|
in | Non-array type fields | Only includes results that are equal to one of the specified values.
|
containsAll | Array type fields | Only includes results which contain all of the specified values.
|
containsAny | Array type fields | Only includes results which contain all of the specified values.
|
exists | All fields | Only includes results where the specified property exists (has value).
|
prefix | String type fields | Only includes results which start with the specified value.
|
range | Non-array type fields | Only includes results that fall within the specified range.
Supported operators: |
geojsonIntersects | geoLocation | Only includes results where the geoshape intersects with the specified geometry.
|
geojsonDisjoint | geoLocation | Only includes results where the geoshape has nothing in common with the specified geometry.
|
geojsonWithin | geoLocation | Only includes results where the geoshape falls within the specified geometry.
|
inAssetSubtree | assetIds, assetExternalIds | Only includes results with a related asset in a subtree rooted at any specified IDs.
|
search | name, content |
|
Properties
The following overview shows the properties you can filter and which filter applies to which property.
| Property | Type | Applicable filters |
|---|---|---|
["id"] |
integer | equals, in, range, exists |
["externalId"] |
string | equals, in, prefix, exists |
["instanceId"] |
string | equals, in |
["instanceId", "space"] |
string | equals, in, prefix, exists |
["instanceId", "externalId"] |
string | equals, in, prefix, exists |
["title"] |
string | equals, in, prefix, exists |
["author"] |
string | equals, in, prefix, exists |
["createdTime"] |
integer | equals, in, range, exists |
["modifiedTime"] |
integer | equals, in, range, exists |
["lastIndexedTime"] |
integer | equals, in, range, exists |
["mimeType"] |
string | equals, in, prefix, exists |
["extension"] |
string | equals, in, prefix, exists |
["pageCount"] |
integer | equals, in, range, exists |
["type"] |
string | equals, in, prefix, exists |
["geoLocation"] |
geometry object | geojsonIntersects, geojsonDisjoint, geojsonWithin, exists |
["language"] |
string | equals, in, prefix, exists |
["assetIds"] |
array of integers | containsAny, containsAll, exists, inAssetSubtree |
["assetExternalIds"] |
array of strings | containsAny, containsAll, exists, inAssetSubtree |
["labels"] |
array of Labels | containsAny, containsAll, exists |
["content"] |
string | search |
["sourceFile", "name"] |
string | equals, in, prefix, exists, search |
["sourceFile", "mimeType"] |
string | equals, in, prefix, exists |
["sourceFile", "size"] |
integer | equals, in, range, exists |
["sourceFile", "source"] |
string | equals, in, prefix, exists |
["sourceFile", "directory"] |
string | equals, in, prefix, exists |
["sourceFile", "assetIds"] |
array of integers | containsAny, containsAll, exists, inAssetSubtree |
["sourceFile", "assetExternalIds"] |
array of strings | containsAny, containsAll, exists, inAssetSubtree |
["sourceFile", "datasetId"] |
integer | equals, in, range, exists |
["sourceFile", "securityCategories"] |
array of integers | containsAny, containsAll, exists |
["sourceFile", "geoLocation"] |
geometry object | geojsonIntersects, geojsonDisjoint, geojsonWithin, exists |
["sourceFile", "labels"] |
array of Labels | containsAny, containsAll, exists |
["sourceFile", "metadata", <key>] |
string | equals, in, prefix, exists |
["sourceFile", "metadata"] |
string | equals, in, prefix, exists This is a special filter field that targets all metadata values. An alternative to creating a filter for each key in the metadata field. |
Full example
{
"filter": {
"and": [
{
"or": [
{
"equals": {
"property": [
"type"
],
"value": "PDF"
}
},
{
"prefix": {
"property": [
"externalId"
],
"value": "hello"
}
}
]
},
{
"range": {
"property": [
"createdTime"
],
"lte": 1519862400000
}
},
{
"not": {
"in": {
"property": [
"sourceFile",
"name"
],
"values": [
"My Document.doc",
"My Other Document.docx"
]
}
}
}
]
}
}
Sorting
By default, search results are ordered by relevance, meaning how well they match the given query string. However, it's possible to specify a different property to sort by. Sorting can be ascending or descending. The sort order is ascending if none is specified.
Properties
The following overview shows all properties that can be sorted on.
| Property |
|---|
["id"] |
["externalId"] |
["mimeType"] |
["extension"] |
["pageCount"] |
["author"] |
["title"] |
["language"] |
["type"] |
["createdTime"] |
["modifiedTime"] |
["lastIndexedTime"] |
["sourceFile", "name"] |
["sourceFile", "mimeType"] |
["sourceFile", "size"] |
["sourceFile", "source"] |
["sourceFile", "datasetId"] |
["sourceFile", "metadata", *] |
Example
{
"sort":[
{
"property":[
"createdTime"
],
"order":"asc",
}
]
}
Authorizations:
Request Body schema: application/jsonrequired
Fields to be set for the search request.
object | |
(bool filters (and (object) or or (object) or not (object))) or (leaf filters (equals (object) or in (object) or containsAny (object) or containsAll (object) or range (object) or prefix (object) or search (object) or exists (object) or geojsonIntersects (object) or geojsonDisjoint (object) or geojsonWithin (object) or inAssetSubtree (object))) (DocumentFilter) | |
Array of objects (DocumentSearchCountAggregate) [ 1 .. 5 ] items Deprecated | |
Array of objects (DocumentSortItem) = 1 items List of properties to sort by. Currently only supports 1 property. | |
| limit | integer <int32> [ 0 .. 1000 ] Default: 100 Maximum number of items. When using highlights the maximum value is reduced to 20. |
| cursor | string Cursor for paging through results. |
| highlight | boolean Whether or not matches in search results should be highlighted. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
{- "search": {
- "query": "cognite \"lorem ipsum\"",
- "highlight": false
}, - "filter": {
- "and": [
- {
- "prefix": {
- "property": [
- "name"
], - "value": "Report"
}
}, - {
- "equals": {
- "property": [
- "type"
], - "value": "PDF"
}
}
]
}, - "aggregates": [
- {
- "name": "countOfTypes",
- "aggregate": "count",
- "groupBy": [
- {
- "property": [
- "type"
]
}
]
}
], - "sort": [
- {
- "order": "asc",
- "property": [
- "sourceFile",
- "name"
]
}
], - "limit": 100,
- "cursor": "string",
- "highlight": true
}Response samples
- 200
- 400
{- "items": [
- {
- "highlight": {
- "name": [
- "amet elit <em>non diam</em> aliquam suscipit"
], - "content": [
- "Nunc <em>vulputate erat</em> ipsum, at aliquet ligula vestibulum at",
- "<em>Quisque</em> lectus ex, fringilla aliquet <em>eleifend</em> nec, laoreet a velit.\n\nPhasellus <em>faucibus</em> risus arcu"
]
}, - "item": {
- "id": 2384,
- "externalId": "haml001",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "title": "Hamlet",
- "author": "William Shakespeare",
- "producer": "string",
- "createdTime": 1519862400000,
- "modifiedTime": 1519958703000,
- "lastIndexedTime": 1521062805000,
- "mimeType": "text/plain",
- "extension": "pdf",
- "pageCount": 2,
- "type": "Document",
- "language": "en",
- "truncatedContent": "ACT I\nSCENE I. Elsinore. A platform before the castle.\n FRANCISCO at his post. Enter to him BERNARDO\nBERNARDO\n Who's there?\n",
- "assetIds": [
- 42,
- 101
], - "labels": [
- {
- "externalId": "my.known.id"
}
], - "sourceFile": {
- "name": "hamlet.txt",
- "directory": "plays/shakespeare",
- "source": "SubsurfaceConnectors",
- "mimeType": "application/octet-stream",
- "size": 1000,
- "hash": "23203f9264161714cdb8d2f474b9b641e6a735f8cea4098c40a3cab8743bd749",
- "assetIds": [ ],
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Point",
- "coordinates": [
- 10.74609,
- 59.91273
]
}, - "datasetId": 1,
- "securityCategories": [ ],
- "metadata": {
- "property1": "string",
- "property2": "string"
}
}, - "geoLocation": {
- "type": "Point",
- "coordinates": [
- 10.74609,
- 59.91273
]
}
}
}
], - "aggregates": [
- {
- "name": "string",
- "groups": [
- {
- "group": [
- {
- "property": [
- "sourceFile",
- "name"
], - "value": "string"
}
], - "count": 0
}
], - "total": 0
}
], - "nextCursor": "string"
}Semantic search Deprecated
This endpoint lets you search for relevant parts (passages) of up to 100 PDF documents by using advanced filters and semantic search queries.
For each query you have to specify a list of document ids using the in filter (see exmple).
This endpoint has been deprecated in favor of /documents/passages/search which is now in GA. Please consider moving over.
Authorizations:
header Parameters
| cdf-version | string Example: alpha cdf version header. Use this to specify the requested CDF release. |
Request Body schema: application/jsonrequired
Fields to be set for the search request.
required | bool filters (and (object)) or (leaf filters (equals (object) or in (object) or semanticSearch (object) or lexicalSearch (object))) (DocumentSemanticFilter) |
required | DocumentSemanticSearchPassageExpansionSymmetric (object) A expansion strategy to to increase the text view for each passage returned. Helpful to increase context for an LLM. |
| limit | integer <int32> [ 1 .. 10 ] Default: 10 Maximum number of items. |
Responses
Request samples
- Payload
{- "filter": {
- "and": [
- {
- "prefix": {
- "property": [
- "name"
], - "value": "Report"
}
}, - {
- "equals": {
- "property": [
- "type"
], - "value": "PDF"
}
}
]
}, - "expansionStrategy": {
- "strategy": "symmetric",
- "chunk_count": 1
}, - "limit": 10
}Response samples
- 200
- 400
{- "items": [
- {
- "match": {
- "text": "Pump installation\nFollow these 15 steps:\n ...",
- "location": [
- {
- "page": 7,
- "left": 68.78,
- "right": 478.56,
- "top": 75.04,
- "bottom": 386.1
}
]
}, - "item": {
- "id": 2384,
- "externalId": "haml001",
- "instanceId": {
- "space": "string",
- "externalId": "string"
}, - "title": "Hamlet",
- "author": "William Shakespeare",
- "producer": "string",
- "createdTime": 1519862400000,
- "modifiedTime": 1519958703000,
- "lastIndexedTime": 1521062805000,
- "mimeType": "text/plain",
- "extension": "pdf",
- "pageCount": 2,
- "type": "Document",
- "language": "en",
- "truncatedContent": "ACT I\nSCENE I. Elsinore. A platform before the castle.\n FRANCISCO at his post. Enter to him BERNARDO\nBERNARDO\n Who's there?\n",
- "assetIds": [
- 42,
- 101
], - "labels": [
- {
- "externalId": "my.known.id"
}
], - "sourceFile": {
- "name": "hamlet.txt",
- "directory": "plays/shakespeare",
- "source": "SubsurfaceConnectors",
- "mimeType": "application/octet-stream",
- "size": 1000,
- "hash": "23203f9264161714cdb8d2f474b9b641e6a735f8cea4098c40a3cab8743bd749",
- "assetIds": [ ],
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Point",
- "coordinates": [
- 10.74609,
- 59.91273
]
}, - "datasetId": 1,
- "securityCategories": [ ],
- "metadata": {
- "property1": "string",
- "property2": "string"
}
}, - "geoLocation": {
- "type": "Point",
- "coordinates": [
- 10.74609,
- 59.91273
]
}
}
}
]
}Semantic search for passages
This endpoint lets you search for relevant passages of up to 100 PDF documents by using advanced filters and semantic search queries.
Where documents search results in a list of relevant documents, this endpoint gives you a result of the most relevant parts of a set of documents.
For each query you have to specify a list of document ids using the in filter (see exmple).
Semantic search works by comparing the semantic meaning of the search query to the semantic meaning of the document passages. The document passages are automatically derived and indexed upon file uploads (PDF only).
A natural flow would be:
- Upload a document
- Query
/documents/statusto check if the document is ready (see beta documentation) - Query
/documents/passages/searchto find relevant passages in the document(s)
Passages search offers semantic search filters
This endpoint requires a list of document ids that you want to do semantic search on. You can not currently search through all passages for the entire project in a single query.
Ordering
Search results are ranked by relevance, with the most relevant appearing first. How relevance is determined depends on the filter you choose:
Lexical Search Filter: This filter looks for exact word matches, making it ideal for finding specific dates, names, or keywords. Use this when you know exactly what you’re looking for. This is the default search behavior for the Documents API.
Semantic Search Filter: This filter understands the meaning behind words and phrases, even if they don’t match exactly. It’s useful for broader searches or when you’re looking for related ideas or concepts.
Choose the filter based on your needs: use Lexical for precise results and Semantic for more general, context-based searches.
When both filters are used together, the results are combined to give you a balanced, relevant list. For best results, we recommend starting with both filters active.
Examples
The following request will return document passages matching the specified search query for the document ids 1, 2, and 3.
{
"filter":{
"and": [
{
"semanticSearch":{
"property":["content"],
"value":"I have an overheating pump that is 85 degrees celsius, what dangers are there with higher temperatures"
}
},
{
"in":{
"property":["document", "id"],
"values":[1, 2, 3]
}
}
]
}
}
If you need keyword matching you can specify a lexicalSearch filter. This helps with edge cases where it's hard to extract meaning such as numbers (eg. dates), names, etc.
{
"filter":{
"and": [
{
"semanticSearch":{
"property":["content"],
"value":"I have an overheating pump that is 85 degrees celsius, what dangers are there with higher temperatures"
}
},
{
"lexicalSearch":{
"property":["content"],
"value":"pump AJ523-253-133"
}
},
{
"in":{
"property":["document", "id"],
"values":[1, 2, 3]
}
}
]
}
}
Doing just lexical search is also possible:
{
"filter":{
"and": [
{
"lexicalSearch":{
"property":["content"],
"value":"pump AJ523-253-133"
}
},
{
"in":{
"property":["document", "id"],
"values":[1, 2, 3]
}
}
]
}
}
Filtering
Filtering uses a special JSON filtering language.
It's flexible and consists of a number of different "leaf" filters, which can be combined arbitrarily using the boolean clauses and.
This is the same filters used in the search, list and aggregate endpoints, with some restrictions and the addition of "semanticSearch" filter.
Supported leaf filters
| Leaf filter |
Supported fields |
Description |
|---|---|---|
equals | Non-array type fields | Only includes results that are equal to the specified value.
|
in | Non-array type fields | Only includes results that are equal to one of the specified values.
|
semanticSearch | content |
|
lexicalSearch | content |
|
Properties
The following overview shows the properties you can filter on and which filter applies to which property.
| Property | Type | Applicable filters |
|---|---|---|
["document", "id"] |
integer | equals, in |
["document", "externalId"] |
string | equals, in |
["document", "instanceId"] |
object | equals, in |
["type"] |
string | equals |
["content"] |
string | semanticSearch, lexicalSearch |
Full example
{
"filter":{
"and": [
{
"in": {
"property": ["document", "instanceId"],
"values": [
{"space": "space1", "externalId": "my-ext-id-1"},
{"space": "space1", "externalId": "my-ext-id-45"},
{"space": "space1", "externalId": "some-other-ext-id"},
]
}
},
{
"semanticSearch":{
"property":["content"],
"value":"A person walking a dog at night time"
}
},
{
"lexicalSearch":{
"property":["content"],
"value":"11:23pm"
}
}
]
}
}
Authorizations:
Request Body schema: application/jsonrequired
Fields to be set for the search request.
required | bool filters (and (object)) or (leaf filters (equals (object) or in (object) or semanticSearch (object) or lexicalSearch (object))) (DocumentPassagesFilter) |
required | DocumentPassagesSearchPassageExpansionSymmetric (object) A expansion strategy to to increase the text view for each passage returned. Helpful to increase context for an LLM. |
| limit | integer <int32> [ 1 .. 10 ] Default: 10 Maximum number of items. |
Responses
Request samples
- Payload
{- "filter": {
- "and": [
- {
- "prefix": {
- "property": [
- "name"
], - "value": "Report"
}
}, - {
- "equals": {
- "property": [
- "type"
], - "value": "PDF"
}
}
]
}, - "expansionStrategy": {
- "strategy": "symmetric",
- "chunk_count": 1
}, - "limit": 10
}Response samples
- 200
- 400
{- "items": [
- {
- "text": "Pump installation\nFollow these 15 steps:\n ...",
- "document": {
- "id": 1234
}, - "locations": [
- {
- "page_number": 3,
- "left": 68.78,
- "right": 478.56,
- "top": 75.04,
- "bottom": 386.1
}, - {
- "page_number": 4,
- "left": 68.78,
- "right": 478.56,
- "top": 75.04,
- "bottom": 386.1
}
]
}
]
}The document preview service is a utility API that can render most document types as an image or PDF. This can be very helpful if you want to display a preview of a file in a frontend, or for other tasks that require one of these formats.
For both rendered formats there is a concept of a page. The actual meaning of a page depends on the source document. E.g. an image will always have exactly one page, while a spreadsheet will typically have one page representing each individual sheet.
The document preview service can only generate preview for document sizes that do not exceed 150 MiB. Trying to preview a larger document will give an error.
File type support
Previews can be created for the following types of files:
- PDF files
- Spreadsheets, documents and presentations from the Microsoft and Libre Office office suites
- Images
Retrieve a image preview of a page from a document
This endpoint returns a rendered image preview for a specific page of the specified document.
The accept request header MUST be set to image/png. Other values will
give an HTTP 406 error.
The rendered image will be downsampled to a maximum of 2400x2400 pixels. Only PNG format is supported and only the first 10 pages can be rendered.
Previews will be rendered if neccessary during the request. Be prepared for the request to take a few seconds to complete.
Authorizations:
path Parameters
| documentId required | integer Internal ID for document to preview |
| pageNumber required | integer [ 1 .. 10 ] Page number to preview. Starting at 1 for first page |
Responses
Request samples
- Python SDK
client.documents.previews.download_page_as_png("previews", id=123, page_number=5) content = client.documents.previews.download_page_as_png_bytes(id=123, page_number=5) from IPython.display import Image binary_png = client.documents.previews.download_page_as_png_bytes(id=123, page_number=5) Image(binary_png)
Response samples
- 400
- 401
- 406
- 422
{- "error": {
- "code": 401,
- "message": "Could not authenticate.",
- "missing": [
- { }
], - "duplicated": [
- { }
]
}
}Retrieve a PDF preview of a document
This endpoint returns a rendered PDF preview for a specified document.
The accept request header MUST be set to application/pdf. Other values will
give an HTTP 406 error.
This endpoint is optimized for in-browser previews. We reserve the right to adjust the quality and other attributes of the output with this in mind. Please reach out to us if you have a different use case and requirements.
Previews will be rendered if neccessary during the request. Be prepared for the request to take a few seconds to complete.
Authorizations:
path Parameters
| documentId required | integer Internal ID for document to preview |
header Parameters
| cdf-version | string Example: alpha cdf version header. Use this to specify the requested CDF release. |
Responses
Request samples
- Python SDK
client.documents.previews.download_document_as_pdf("previews", id=123) content = client.documents.previews.download_document_as_pdf_bytes(id=123)
Response samples
- 400
- 401
- 406
- 422
{- "error": {
- "code": 401,
- "message": "Could not authenticate.",
- "missing": [
- { }
], - "duplicated": [
- { }
]
}
}Retrieve a temporary link to a PDF preview of a document
This endpoint works similar as the normal preview endpoint except it returns a short-lived temporary link to download the rendered preview instead of returning the binary data.
Authorizations:
path Parameters
| documentId required | integer Internal ID for document to preview |
header Parameters
| cdf-version | string Example: alpha cdf version header. Use this to specify the requested CDF release. |
Responses
Request samples
- Python SDK
link = client.documents.previews.retrieve_pdf_link(id=123)
Response samples
- 200
- 400
- 401
- 422
{- "temporaryLink": "string",
- "expirationTime": 1519862400000
}Manage data in the raw NoSQL database. Each project will have a variable number of raw databases, each of which will have a variable number of tables, each of which will have a variable number of key-value objects. Only queries on key are supported through this API.\
Request and concurrency limits
Both the rate of requests and the number of concurrent (parallel) requests are governed by limits,
for all CDF API endpoints. If a request exceeds one of the limits,
it will be throttled with a 429: Too Many Requests response. More on limit types
and how to avoid being throttled is described
here.
The limits for the Raw service are described in the table below. Note that under high load,
some deviation from the limits might occur for short periods of time as the service is scaling up.
The /rows endpoints for inserting and retrieving data are governed by specific data rate limits.
| Limit | Per project | Per user (identity) |
|---|---|---|
| Concurrency | 64 parallel requests | 48 parallel requests |
| Data rate (retrieve) | 8.3 GB / 10 minutes | 6.6 GB / 10 minutes |
| Data rate (insert) | 1.6 GB / 10 minutes | 1.3 GB / 10 minutes |
Create databases
Create databases in a project. It is possible to post a maximum of 1000 databases per request.
Authorizations:
Request Body schema: application/jsonrequired
List of names of databases to be created.
Array of objects (RawDB) |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "name": "string"
}
]
}Response samples
- 201
{- "items": [
- {
- "name": "string"
}
]
}Create tables in a database
Create tables in a database. It is possible to post a maximum of 1000 tables per request.
Authorizations:
path Parameters
| dbName required | string Name of the database to create tables in. |
query Parameters
| ensureParent | boolean Default: false Create database if it doesn't exist already |
Request Body schema: application/jsonrequired
List of tables to create.
Array of objects (RawDBTable) |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "name": "string"
}
]
}Response samples
- 201
- 400
{- "items": [
- {
- "name": "string"
}
]
}Delete databases
It deletes a database, but fails if the database is not empty and recursive is set to false (default).
Authorizations:
Request Body schema: application/jsonrequired
List of names of the databases to be deleted.
Array of objects (RawDB) | |
| recursive | boolean Default: false When true, tables of this database are deleted with the database. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "name": "string"
}
], - "recursive": false
}Response samples
- 200
{ }Delete rows in a table
Authorizations:
path Parameters
| dbName required | string [ 1 .. 32 ] characters Name of the database containing the rows. |
| tableName required | string [ 1 .. 64 ] characters Name of the table containing the rows. |
Request Body schema: application/jsonrequired
Keys to the rows to delete.
Array of objects (RawDBRowKey) |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "key": "string"
}
]
}Response samples
- 200
{ }Delete tables in a database
Authorizations:
path Parameters
| dbName required | string Name of the database to delete tables in. |
Request Body schema: application/jsonrequired
List of tables to delete.
Array of objects (RawDBTable) |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "name": "string"
}
]
}Response samples
- 200
- 400
{ }Insert rows into a table
Insert rows into a table. It is possible to post a maximum of 10000 rows per request. It will replace the columns of an existing row if the rowKey already exists.
The rowKey is limited to 1024 characters which also includes Unicode characters. The maximum size of columns are 5 MiB, however the maximum size of one column name and value is 2621440 characters each. If you want to store huge amount of data per row or column we recommend using the Files API to upload blobs, then reference it from the Raw row.
The columns object is a key value object, where the key corresponds to the column name while the value is the column value. It supports all the valid types of values in JSON, so number, string, array, and even nested JSON structure (see payload example to the right).
If an error occurs during the write, partial data may be written as there is no rollback. However, it's safe to retry the request, since this endpoint supports both update and insert (upsert).
A row's last updated timestamp will only be updated if the new column contents are considered different to the old one. An identical JSON string should always be counted as the same contents.
Authorizations:
path Parameters
| dbName required | string [ 1 .. 32 ] characters Name of the database. |
| tableName required | string [ 1 .. 64 ] characters Name of the table. |
query Parameters
| ensureParent | boolean Default: false Create database/table if it doesn't exist already |
Request Body schema: required
List of rows to create.
Array of objects (RawDBRowInsert) |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "key": "some rowKey",
- "columns": {
- "some int-col": 10,
- "some string-col": "string example",
- "some json-col": {
- "test": {
- "foo": "nested"
}
}, - "some array-col": [
- 0,
- 1,
- 3,
- 4
]
}
}
]
}Response samples
- 200
- 400
{ }List databases
Authorizations:
query Parameters
| limit | integer <int32> [ 1 .. 1000 ] Default: 25 Limit on the number of databases to be returned. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Request samples
- JavaScript SDK
- Python SDK
- Java SDK
const databases = await client.raw.listDatabases();
Response samples
- 200
{- "items": [
- {
- "name": "string"
}
], - "nextCursor": "string"
}List tables in a database
Authorizations:
path Parameters
| dbName required | string The name of a database to retrieve tables from. |
query Parameters
| limit | integer <int32> [ 1 .. 1000 ] Default: 25 Limit on the number of tables to be returned. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Request samples
- JavaScript SDK
- Python SDK
- Java SDK
const tables = await client.raw.listTables('My company');
Response samples
- 200
{- "items": [
- {
- "name": "string"
}
], - "nextCursor": "string"
}Retrieve cursors for parallel reads
Retrieve cursors based on the last updated time range. Normally this endpoint is used for reading in parallel.
Each cursor should be supplied as the 'cursor' query parameter on GET requests to Read Rows. Note that the 'minLastUpdatedTime' and the 'maxLastUpdatedTime' query parameter on Read Rows are ignored when a cursor is specified.
Authorizations:
path Parameters
| dbName required | string Name of the database. |
| tableName required | string Name of the table. |
query Parameters
| minLastUpdatedTime | integer <int64> (EpochTimestamp) >= 0 Example: minLastUpdatedTime=1730204346000 An exclusive filter, specified as the number of milliseconds that have elapsed since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| maxLastUpdatedTime | integer <int64> (EpochTimestamp) >= 0 Example: maxLastUpdatedTime=1730204346000 An inclusive filter, specified as the number of milliseconds that have elapsed since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| numberOfCursors | integer <int32> [ 1 .. 10000 ] The number of cursors to return, by default it's 10. |
Responses
Response samples
- 200
{- "items": [
- "string"
]
}Retrieve row by key
Authorizations:
path Parameters
| dbName required | string [ 1 .. 32 ] characters Name of the database to retrieve the row from. |
| tableName required | string [ 1 .. 64 ] characters Name of the table to retrieve the row from. |
| rowKey required | string Row key of the row to retrieve. |
Responses
Request samples
- JavaScript SDK
- Python SDK
- Java SDK
await client.raw.retrieveRow('My company', 'Customers', 'customer1');
Response samples
- 200
{- "key": "string",
- "columns": { },
- "lastUpdatedTime": 1730204346000
}Retrieve rows from a table
Authorizations:
path Parameters
| dbName required | string Name of the database. |
| tableName required | string Name of the table. |
query Parameters
| limit | integer <int32> [ 1 .. 10000 ] Default: 25 Limit the number of results. The API may return fewer than the specified limit. |
| columns | string Example: columns=column1,column2 Ordered list of column keys, separated by commas. Leave empty for all, use single comma to retrieve only row keys. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| minLastUpdatedTime | integer <int64> (EpochTimestamp) >= 0 Example: minLastUpdatedTime=1730204346000 An exclusive filter, specified as the number of milliseconds that have elapsed since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
| maxLastUpdatedTime | integer <int64> (EpochTimestamp) >= 0 Example: maxLastUpdatedTime=1730204346000 An inclusive filter, specified as the number of milliseconds that have elapsed since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC), minus leap seconds. |
Responses
Request samples
- JavaScript SDK
- Python SDK
- Java SDK
await client.raw.listRows('My company', 'Employees', { columns: ['last_name'] });
Response samples
- 200
{- "items": [
- {
- "key": "string",
- "columns": { },
- "lastUpdatedTime": 1730204346000
}
], - "nextCursor": "string"
}Extraction Pipeline objects represent the applications and software that are deployed to ingest operational data into CDF. An extraction pipeline can consist of a number of different software components between the source system and CDF. The extraction pipeline object represents the software component that actually sends the data to CDF. Two examples are Cognite extractors and third party ETL tools such as Microsoft Azure or Informatica PowerCenter
Create extraction pipelines
Creates multiple new extraction pipelines. A maximum of 1000 extraction pipelines can be created per request.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (CreateExtPipe) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "items": [
- {
- "externalId": "string",
- "name": "string",
- "description": "string",
- "dataSetId": 9007199254740991,
- "rawTables": [
- {
- "dbName": "string",
- "tableName": "string"
}
], - "schedule": "string",
- "contacts": [
- {
- "name": "string",
- "email": "user@example.com",
- "role": "string",
- "sendNotification": true
}
], - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "documentation": "string",
- "notificationConfig": {
- "allowedNotSeenRangeInMinutes": 0
}, - "createdBy": "string"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "string",
- "name": "string",
- "description": "string",
- "dataSetId": 9007199254740991,
- "rawTables": [
- {
- "dbName": "string",
- "tableName": "string"
}
], - "schedule": "string",
- "contacts": [
- {
- "name": "string",
- "email": "user@example.com",
- "role": "string",
- "sendNotification": true
}
], - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "documentation": "string",
- "notificationConfig": {
- "allowedNotSeenRangeInMinutes": 0
}, - "createdBy": "string",
- "id": 9007199254740991,
- "lastSuccess": 0,
- "lastFailure": 0,
- "lastMessage": "string",
- "lastSeen": 0,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
], - "nextCursor": "string"
}Delete extraction pipelines
Delete extraction pipelines for given list of ids and externalIds. When the extraction pipeline is deleted, all extraction pipeline runs related to the extraction pipeline are automatically deleted.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of ExtPipeInternalId (object) or ExtPipeExternalId (object) (ExtPipeId) [ 1 .. 1000 ] items |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 9007199254740991
}
], - "ignoreUnknownIds": false
}Response samples
- 200
- 400
{ }Filter extraction pipelines
Use advanced filtering options to find extraction pipelines.
Authorizations:
Request Body schema: application/jsonrequired
object (ExtPipesFilter) | |
| limit | integer <int32> [ 1 .. 1000 ] Default: 100 Limits the number of results to return. |
| cursor | string |
Responses
Request samples
- Payload
- Java SDK
{- "filter": {
- "externalIdPrefix": "string",
- "name": "string",
- "description": "string",
- "dataSetIds": [
- {
- "id": 1
}
], - "schedule": "string",
- "contacts": [
- {
- "name": "string",
- "email": "user@example.com",
- "role": "string",
- "sendNotification": true
}
], - "rawTables": [
- {
- "dbName": "string",
- "tableName": "string"
}
], - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "documentation": "string",
- "createdBy": "string",
- "createdTime": {
- "max": 0,
- "min": 0
}, - "lastUpdatedTime": {
- "max": 0,
- "min": 0
}
}, - "limit": 100,
- "cursor": "string"
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "string",
- "name": "string",
- "description": "string",
- "dataSetId": 9007199254740991,
- "rawTables": [
- {
- "dbName": "string",
- "tableName": "string"
}
], - "schedule": "string",
- "contacts": [
- {
- "name": "string",
- "email": "user@example.com",
- "role": "string",
- "sendNotification": true
}
], - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "documentation": "string",
- "notificationConfig": {
- "allowedNotSeenRangeInMinutes": 0
}, - "createdBy": "string",
- "id": 9007199254740991,
- "lastSuccess": 0,
- "lastFailure": 0,
- "lastMessage": "string",
- "lastSeen": 0,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}List extraction pipelines
Returns a list of all extraction pipelines for a given project
Authorizations:
query Parameters
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 1000 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Request samples
- Python SDK
ep_list = client.extraction_pipelines.list(limit=5)
Response samples
- 200
{- "items": [
- {
- "externalId": "string",
- "name": "string",
- "description": "string",
- "dataSetId": 9007199254740991,
- "rawTables": [
- {
- "dbName": "string",
- "tableName": "string"
}
], - "schedule": "string",
- "contacts": [
- {
- "name": "string",
- "email": "user@example.com",
- "role": "string",
- "sendNotification": true
}
], - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "documentation": "string",
- "notificationConfig": {
- "allowedNotSeenRangeInMinutes": 0
}, - "createdBy": "string",
- "id": 9007199254740991,
- "lastSuccess": 0,
- "lastFailure": 0,
- "lastMessage": "string",
- "lastSeen": 0,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
], - "nextCursor": "string"
}Retrieve an extraction pipeline by its ID.
Retrieve an extraction pipeline by its ID. If you want to retrieve extraction pipelines by externalIds, use Retrieve extraction pipelines instead.
Authorizations:
path Parameters
| id required | integer <int64> (CogniteInternalId) [ 1 .. 9007199254740991 ] A server-generated ID for the object. |
Responses
Request samples
- Python SDK
res = client.extraction_pipelines.retrieve(id=1) res = client.extraction_pipelines.retrieve(external_id="1")
Response samples
- 200
- 400
{- "externalId": "string",
- "name": "string",
- "description": "string",
- "dataSetId": 9007199254740991,
- "rawTables": [
- {
- "dbName": "string",
- "tableName": "string"
}
], - "schedule": "string",
- "contacts": [
- {
- "name": "string",
- "email": "user@example.com",
- "role": "string",
- "sendNotification": true
}
], - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "documentation": "string",
- "notificationConfig": {
- "allowedNotSeenRangeInMinutes": 0
}, - "createdBy": "string",
- "id": 9007199254740991,
- "lastSuccess": 0,
- "lastFailure": 0,
- "lastMessage": "string",
- "lastSeen": 0,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}Retrieve extraction pipelines
Retrieves information about multiple extraction pipelines in the same project. All ids and externalIds must be unique.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of ExtPipeInternalId (object) or ExtPipeExternalId (object) (ExtPipeId) [ 1 .. 1000 ] items |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 9007199254740991
}
], - "ignoreUnknownIds": false
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "string",
- "name": "string",
- "description": "string",
- "dataSetId": 9007199254740991,
- "rawTables": [
- {
- "dbName": "string",
- "tableName": "string"
}
], - "schedule": "string",
- "contacts": [
- {
- "name": "string",
- "email": "user@example.com",
- "role": "string",
- "sendNotification": true
}
], - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "documentation": "string",
- "notificationConfig": {
- "allowedNotSeenRangeInMinutes": 0
}, - "createdBy": "string",
- "id": 9007199254740991,
- "lastSuccess": 0,
- "lastFailure": 0,
- "lastMessage": "string",
- "lastSeen": 0,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Update extraction pipelines
Update information for a list of extraction pipelines. Fields that are not included in the request, are not changed.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of ExtPipeUpdateById (object) or ExtPipeUpdateByExternalId (object) (ExtPipeUpdate) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 9007199254740991,
- "update": {
- "externalId": {
- "set": "string"
}, - "name": {
- "set": "string"
}, - "description": {
- "set": "string"
}, - "dataSetId": {
- "set": 9007199254740991
}, - "schedule": {
- "set": "string"
}, - "rawTables": {
- "set": [
- {
- "dbName": "string",
- "tableName": "string"
}
]
}, - "contacts": {
- "set": [
- {
- "name": "string",
- "email": "user@example.com",
- "role": "string",
- "sendNotification": true
}
]
}, - "metadata": {
- "set": {
- "property1": "string",
- "property2": "string"
}
}, - "source": {
- "set": "string"
}, - "documentation": {
- "set": "string"
}, - "notificationConfig": {
- "set": {
- "allowedNotSeenRangeInMinutes": 0
}
}
}
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "string",
- "name": "string",
- "description": "string",
- "dataSetId": 9007199254740991,
- "rawTables": [
- {
- "dbName": "string",
- "tableName": "string"
}
], - "schedule": "string",
- "contacts": [
- {
- "name": "string",
- "email": "user@example.com",
- "role": "string",
- "sendNotification": true
}
], - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "documentation": "string",
- "notificationConfig": {
- "allowedNotSeenRangeInMinutes": 0
}, - "createdBy": "string",
- "id": 9007199254740991,
- "lastSuccess": 0,
- "lastFailure": 0,
- "lastMessage": "string",
- "lastSeen": 0,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Extraction Pipelines Runs are CDF objects to store statuses related to an extraction pipeline. The supported statuses are: success, failure and seen. The statuses are related to two different types of operation of the extraction pipeline. Success and failure indicate the status for a particular EP run where the EP attempts to send data to CDF. If the data is successfully posted to CDF the status of the run is ‘success’; if the run has been unsuccessful and the data is not posted to CDF, the status of the run is ‘failure’. Message can be stored to explain run status. Seen is a heartbeat status that indicates that the extraction pipeline is alive. This message is sent periodically on a schedule and indicates that the extraction pipeline is working even though data may not have been sent to CDF by the extraction pipeline.
Create extraction pipeline runs
Create multiple extraction pipeline runs. Current version supports one extraction pipeline run per request. Extraction pipeline runs support three statuses: success, failure, seen. The content of the Error Message parameter is configurable and will contain any messages that have been configured within the extraction pipeline.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (ExtPipeRunRequest) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "items": [
- {
- "externalId": "string",
- "status": "success",
- "message": "string",
- "createdTime": 0
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 1,
- "status": "string",
- "message": "string",
- "createdTime": 1730204346000,
- "externalId": "string"
}
]
}Filter extraction pipeline runs
Use advanced filtering options to find extraction pipeline runs. Sorted by createdTime value with descendant order.
Authorizations:
Request Body schema: application/jsonrequired
required | object (RunsFilter) |
| limit | integer <int32> [ 1 .. 1000 ] Default: 100 Limits the number of results to return. |
| cursor | string |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "filter": {
- "externalId": "string",
- "statuses": [
- "success"
], - "createdTime": {
- "max": 0,
- "min": 0
}, - "message": {
- "substring": "string"
}
}, - "limit": 100,
- "cursor": "string"
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 1,
- "status": "string",
- "message": "string",
- "createdTime": 1730204346000
}
], - "nextCursor": "string"
}List extraction pipeline runs
List of all extraction pipeline runs for a given extraction pipeline. Sorted by createdTime value with descendant order.
Authorizations:
query Parameters
| externalId required | string |
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 1000 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Response samples
- 200
{- "items": [
- {
- "id": 1,
- "status": "string",
- "message": "string",
- "createdTime": 1730204346000
}
], - "nextCursor": "string"
}Extraction Pipelines Configs are configuration file revisions tied to an extraction pipeline. Users can create new configuration revisions, and extractors can fetch the latest, making it easy to deploy configuration files from source control, automated scripts, etc.
Create extraction configuration revision
Creates a configuration revision for the given extraction pipeline.
Authorizations:
Request Body schema: application/jsonrequired
| externalId required | string [ 1 .. 255 ] characters External ID of the extraction pipeline this configuration revision belongs to. |
| config | string Configuration content. |
| description | string or null A description of this configuration revision. |
Responses
Request samples
- Payload
{- "externalId": "string",
- "config": "string",
- "description": "string"
}Response samples
- 200
- 400
{- "externalId": "string",
- "config": "string",
- "revision": 2147483647,
- "createdTime": 1730204346000,
- "description": "string"
}Get a single configuration revision
Retrieves a single configuration revision. By default, the latest revision is retrieved.
Authorizations:
query Parameters
| externalId required | string |
| revision | integer <int32> >= 0 Default: 0 |
| activeAtTime | integer <int64> >= 0 Default: 0 |
Responses
Response samples
- 200
- 400
{- "externalId": "string",
- "config": "string",
- "revision": 2147483647,
- "createdTime": 1730204346000,
- "description": "string"
}List configuration revisions
Lists configuration revisions for the given extraction pipeline.
Authorizations:
query Parameters
| externalId required | string |
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 1000 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "string",
- "revision": 2147483647,
- "createdTime": 1730204346000,
- "description": "string"
}
]
}Revert configuration revision
Reverts the latest configuration revision to an older revision. Equivalent to creating a new revision identical to the old revision.
Authorizations:
Request Body schema: application/jsonrequired
| externalId required | string [ 1 .. 255 ] characters External ID of the extraction pipeline to revert configurations for. |
| revision | integer <int32> [ 0 .. 2147483647 ] Revision number of this configuration. |
Responses
Request samples
- Payload
{- "externalId": "string",
- "revision": 2147483647
}Response samples
- 200
- 400
{- "externalId": "string",
- "config": "string",
- "revision": 2147483647,
- "createdTime": 1730204346000,
- "description": "string"
}Extractors are tools used to move data from various source systems to CDF. The extractors API is used to manage extractor releases, give access to downloads, and contextualize which source systems each extractor is used to access.
Each extractor has a list of releases, and each release may have a list of artifacts which are things like documentation PDFs, executables, and installers.
Extractors may also be tied to source systems through solutions, representing concrete sources each extractor may connect to.
The extractors API is currently read-only. In the future it may be possible to define per-project extractors. Because of this, cognite-maintained extractors and source systems currently have their external ID prefixed by cognite-.
Get Config Schema
Retrieve the configuration schema for the specified extractor and release version. The configuration schema is a JSON Schema file.
Authorizations:
path Parameters
| extractor required | string <= 255 characters External ID of the extractor to get the schema for. |
| version required | string Example: 1.2.3 Version of the extractor to fetch schema for. |
Responses
Response samples
- 200
- 400
{ }List Extractors
List all available extractors.
Authorizations:
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "documentation": "string",
- "imageUrl": "string",
- "latestVersion": "string",
- "links": [
- {
- "name": "string",
- "type": "generic",
- "url": "string"
}
], - "tags": [
- "string"
], - "type": "global"
}
]
}List releases
List releases for all extractors, or optionally for a single extractor. Results are sorted in descending version order.
Authorizations:
query Parameters
| externalId | string (External ID) External ID of extractor to retrieve releases for. |
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "artifacts": [
- {
- "name": "string",
- "displayName": "string",
- "link": "string",
- "platform": "windows"
}
], - "changelog": {
- "added": [
- "string"
], - "changed": [
- "string"
], - "deprecated": [
- "string"
], - "fixed": [
- "string"
], - "removed": [
- "string"
], - "security": [
- "string"
]
}, - "createdTime": 1730204346000,
- "description": "string",
- "externalId": "my.known.id",
- "version": "string"
}
]
}List Solutions
List solutions. Solutions connect sources to extractors, documenting how a specific extractor might be used to connect to a source system.
Authorizations:
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "documentation": "string",
- "type": "global",
- "sourceSystemExternalId": "string",
- "extractorExternalId": "string"
}
]
}List Source Systems
List source systems. Source systems represent sources that extractors may read from. They are tied to extractors through Solutions.
Authorizations:
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "documentation": "string",
- "imageUrl": "string",
- "type": "global",
- "tags": [
- "string"
]
}
]
}Retrieve Extractors
Retrieve extractors by external ID, optionally ignoring unknown IDs.
Authorizations:
Request Body schema: application/jsonrequired
| ignoreUnknownIds | boolean (Ignore Unknown Ids) |
required | Array of objects (Items) |
Responses
Request samples
- Payload
{- "ignoreUnknownIds": true,
- "items": [
- {
- "externalId": "my.known.id"
}
]
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "documentation": "string",
- "imageUrl": "string",
- "latestVersion": "string",
- "links": [
- {
- "name": "string",
- "type": "generic",
- "url": "string"
}
], - "tags": [
- "string"
], - "type": "global"
}
]
}Retrieve Releases
Retrieve releases by extractor external ID and version, optionally ignoring unknown IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of releases to retrieve.
| ignoreUnknownIds | boolean (Ignore Unknown Ids) |
required | Array of objects (Items) |
Responses
Request samples
- Payload
{- "ignoreUnknownIds": true,
- "items": [
- {
- "externalId": "my.known.id",
- "version": "string"
}
]
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "artifacts": [
- {
- "name": "string",
- "displayName": "string",
- "link": "string",
- "platform": "windows"
}
], - "changelog": {
- "added": [
- "string"
], - "changed": [
- "string"
], - "deprecated": [
- "string"
], - "fixed": [
- "string"
], - "removed": [
- "string"
], - "security": [
- "string"
]
}, - "createdTime": 1730204346000,
- "description": "string",
- "externalId": "my.known.id",
- "version": "string"
}
]
}Retrieve Solutions
Retrieve solutions by external ID. Solutions connect sources to extractors, documenting how a specific extractor might be used to connect to a source system.
Authorizations:
Request Body schema: application/json
| ignoreUnknownIds | boolean (Ignore Unknown Ids) |
required | Array of objects (Items) |
Responses
Request samples
- Payload
{- "ignoreUnknownIds": true,
- "items": [
- {
- "externalId": "my.known.id"
}
]
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "documentation": "string",
- "type": "global",
- "sourceSystemExternalId": "string",
- "extractorExternalId": "string"
}
]
}Retrieve Source Systems
Retrieve source systems. Source systems represent sources that extractors may read from. They are tied to extractors through Solutions.
Authorizations:
Request Body schema: application/json
List of source systems to retrieve.
| ignoreUnknownIds | boolean (Ignore Unknown Ids) |
required | Array of objects (Items) |
Responses
Request samples
- Payload
{- "ignoreUnknownIds": true,
- "items": [
- {
- "externalId": "my.known.id"
}
]
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "documentation": "string",
- "imageUrl": "string",
- "type": "global",
- "tags": [
- "string"
]
}
]
}Data sets let you document and track data lineage, ensure data integrity, and allow 3rd parties to write their insights securely back to a Cognite Data Fusion (CDF) project.
Data sets group and track data by its source. For example, a data set can contain all work orders originating from SAP. Typically, an organization will have one data set for each of its data ingestion pipelines in CDF.
A data set consists of metadata about the data set, and the data objects that belong to the data set. Data objects, for example events, files, and time series, are added to a data set through the dataSetId field of the data object. Each data object can belong to only one data set.
To learn more about data sets, see getting started guide
Aggregate data sets
Aggregate data sets in the same project. Criteria can be applied to select a subset of data sets.
Authorizations:
Request Body schema: application/json
object (DataSetFilter) Filter on data sets with strict matching. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "filter": {
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "createdTime": {
- "max": 0,
- "min": 0
}, - "lastUpdatedTime": {
- "max": 0,
- "min": 0
}, - "externalIdPrefix": "my.known.prefix",
- "writeProtected": true
}
}Response samples
- 200
- 400
{- "items": [
- {
- "count": 0
}
]
}Create data sets
You can create a maximum of 10 data sets per request.
Authorizations:
Request Body schema: application/jsonrequired
List of the data sets to create.
required | Array of objects (DataSetSpec) [ 1 .. 10 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "writeProtected": false
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "writeProtected": false,
- "id": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Filter data sets
Use advanced filtering options to find data sets.
Authorizations:
Request Body schema: application/json
object (DataSetFilter) Filter on data sets with strict matching. | |
| limit | integer <int32> [ 1 .. 1000 ] Default: 100 Limits the number of results to return. |
| cursor | string |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "filter": {
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "createdTime": {
- "max": 0,
- "min": 0
}, - "lastUpdatedTime": {
- "max": 0,
- "min": 0
}, - "externalIdPrefix": "my.known.prefix",
- "writeProtected": true
}, - "limit": 100,
- "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo"
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "writeProtected": false,
- "id": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
], - "nextCursor": "string"
}Retrieve data sets
Retrieve data sets by IDs or external IDs.
Authorizations:
Request Body schema: application/json
List of the IDs of the data sets to retrieve. You can retrieve a maximum of 1000 data sets per request. All IDs must be unique.
required | Array of DataSetInternalId (object) or DataSetExternalId (object) (DataSetIdEither) [ 1 .. 1000 ] items unique |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 1
}
], - "ignoreUnknownIds": false
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "writeProtected": false,
- "id": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Update data sets.
Authorizations:
Request Body schema: application/jsonrequired
All provided IDs and external IDs must be unique. Fields that are not included in the request, are not changed.
required | Array of DataSetChangeById (object) or DataSetChangeByExternalId (object) (DataSetUpdate) |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "update": {
- "externalId": {
- "set": "string"
}, - "name": {
- "set": "string"
}, - "description": {
- "set": "string"
}, - "metadata": {
- "set": {
- "key1": "value1",
- "key2": "value2"
}
}, - "writeProtected": {
- "set": true
}
}, - "id": 1
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "writeProtected": false,
- "id": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Create label definitions.
Creates label definitions that can be used across different resource types. The label definitions are uniquely identified by their external id.
Authorizations:
Request Body schema: application/jsonrequired
List of label definitions to create
required | Array of objects (ExternalLabelDefinition) [ 1 .. 1000 ] items unique |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1
}
]
}Response samples
- 201
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "createdTime": 1730204346000
}
]
}Delete label definitions.
Delete all the label definitions specified by their external ids. The resource items that have the corresponding label attached remain unmodified. It is up to the client to clean up the resource items from their attached labels if necessary.
Authorizations:
Request Body schema: application/jsonrequired
List of external ids of label definitions to delete.
required | Array of objects (LabelDefinitionExternalId) [ 1 .. 1000 ] items unique |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "externalId": "my.known.id"
}
]
}Response samples
- 200
- 400
{ }Filter labels
Use advanced filtering options to find label definitions.
Authorizations:
Request Body schema: application/json
object (Filter) Filter on labels definitions with strict matching. | |
| cursor | string |
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to return. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "filter": {
- "name": "string",
- "externalIdPrefix": "string",
- "dataSetIds": [
- {
- "id": 1
}
]
}, - "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo",
- "limit": 100
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "createdTime": 1730204346000
}
], - "nextCursor": "string"
}Retrieve labels
Retrieve labels using their external ids
Authorizations:
Request Body schema: application/json
required | Array of objects (Select by ExternalId) [ 1 .. 1000 ] items |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "my.known.id"
}
], - "ignoreUnknownIds": false
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "createdTime": 1730204346000
}
], - "nextCursor": "string"
}The relationships resource type represents connections between resource objects in CDF. Relationships allow you to organize assets in other structures in addition to the standard hierarchical asset structure. Each relationship is between a source and a target object and is defined by a relationship type and the external IDs and resource types of the source and target objects. Optionally, a relationship can be time-constrained with a start and end time. To define and manage the available relationship types, use the labels resource type. The externalId field uniquely identifies each relationship.
Create relationships
List of the relationships to create. You can create a maximum of 1000 relationships per request. Relationships should be unique, but CDF does not prevent you from creating duplicates where only the externalId differs.
Relationships are uniquely identified by their externalId. Non-unique relationships will not be created.
The order of relationships in the response equals the order in the request.
Authorizations:
Request Body schema: application/jsonrequired
Data required to create relationships. You can request a maximum of 1000 relationships per request.
required | Array of objects (relationship) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "externalId": "string",
- "sourceExternalId": "string",
- "sourceType": "asset",
- "targetExternalId": "string",
- "targetType": "asset",
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "confidence": 1,
- "dataSetId": 1,
- "labels": [
- {
- "externalId": "my.known.id"
}
]
}
]
}Response samples
- 201
- 400
- 409
- 500
{- "items": [
- {
- "externalId": "string",
- "sourceExternalId": "string",
- "sourceType": "asset",
- "targetExternalId": "string",
- "targetType": "asset",
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "confidence": 1,
- "dataSetId": 1,
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Delete relationships
Delete the relationships between resources identified by the external IDs in the request. You can delete a maximum of 1000 relationships per request.
Authorizations:
Request Body schema: application/jsonrequired
Data required to delete relationships. You can delete a maximum of 1000 relationships per request.
required | Array of objects (itemsArray) [ 1 .. 1000 ] items |
| ignoreUnknownIds | boolean (ignoreUnknownIds) Ignore external IDs that are not found. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "externalId": "string"
}
], - "ignoreUnknownIds": false
}Response samples
- 202
- 409
- 500
{ }Filter relationships
Lists relationships matching the query filter in the request. You can retrieve a maximum of 1000 relationships per request.
Authorizations:
Request Body schema: application/jsonrequired
Data required to filter relationships. Combined filters are interpreted as an AND operation (not OR). Only relationships that match ALL the provided filters are returned.
object (advancedListFilter) Filter on relationships with exact match. Multiple filter elements in one property, for example | |
| limit | integer [ 1 .. 1000 ] Limits the number of results to return. |
| cursor | string |
| fetchResources | boolean (fetchResources) If true, will try to fetch the resources referred to in the relationship, based on the users access rights. Will silently fail to attatch the resources if the user lacks access to some of them. |
| partition | string (Partition) Splits the data set into To prevent unexpected problems and maximize read throughput, you should at most use 10 (N <= 10) partitions. When using more than 10 partitions, CDF may reduce the number of partitions silently.
For example, CDF may reduce the number of partitions to In future releases of the resource APIs, Cognite may reject requests if you specify more than 10 partitions. When Cognite enforces this behavior, the requests will result in a 400 Bad Request status. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "filter": {
- "sourceExternalIds": [
- "string"
], - "sourceTypes": [
- "asset"
], - "targetExternalIds": [
- "string"
], - "targetTypes": [
- "asset"
], - "dataSetIds": [
- {
- "id": 1
}
], - "startTime": {
- "max": 0,
- "min": 0
}, - "endTime": {
- "max": 0,
- "min": 0
}, - "confidence": {
- "min": 0,
- "max": 0
}, - "lastUpdatedTime": {
- "max": 0,
- "min": 0
}, - "createdTime": {
- "max": 0,
- "min": 0
}, - "activeAtTime": {
- "max": 0,
- "min": 0
}, - "labels": {
- "containsAny": [
- {
- "externalId": "my.known.id"
}
]
}, - "sourcesOrTargets": [
- {
- "type": "asset",
- "externalId": "string"
}
]
}, - "limit": 100,
- "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo",
- "fetchResources": false,
- "partition": "1/10"
}Response samples
- 200
- 400
- 409
{- "items": [
- {
- "externalId": "string",
- "sourceExternalId": "string",
- "sourceType": "asset",
- "targetExternalId": "string",
- "targetType": "asset",
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "confidence": 1,
- "dataSetId": 1,
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "source": {
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "rootId": 1,
- "aggregates": {
- "childCount": 0,
- "depth": 0,
- "path": [
- {
- "id": 1
}
]
}, - "parentId": 1,
- "parentExternalId": "my.known.id",
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1
}, - "target": {
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "rootId": 1,
- "aggregates": {
- "childCount": 0,
- "depth": 0,
- "path": [
- {
- "id": 1
}
]
}, - "parentId": 1,
- "parentExternalId": "my.known.id",
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1
}
}
], - "nextCursor": "string"
}List relationships
Lists all relationships. The order of retrieved objects may change for two calls with the same parameters. The endpoint supports pagination. The initial call to this endpoint should not contain a cursor, but the cursor parameter should be used to retrieve further pages of results.
Authorizations:
query Parameters
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 1000 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| partition | string Example: partition=1/10 Splits the data set into To prevent unexpected problems and maximize read throughput, you should at most use 10 (N <= 10) partitions. When using more than 10 partitions, CDF may reduce the number of partitions silently.
For example, CDF may reduce the number of partitions to In future releases of the resource APIs, Cognite may reject requests if you specify more than 10 partitions. When Cognite enforces this behavior, the requests will result in a 400 Bad Request status. |
Responses
Response samples
- 200
- 500
{- "items": [
- {
- "externalId": "string",
- "sourceExternalId": "string",
- "sourceType": "asset",
- "targetExternalId": "string",
- "targetType": "asset",
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "confidence": 1,
- "dataSetId": 1,
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
], - "nextCursor": "string"
}Retrieve relationships
Retrieve relationships by external IDs. You can retrieve a maximum of 1000 relationships per request. The order of the relationships in the response equals the order in the request.
Authorizations:
Request Body schema: application/jsonrequired
Data required to list relationships.
required | Array of objects (itemsArray) [ 1 .. 1000 ] items |
| ignoreUnknownIds | boolean (ignoreUnknownIds) Ignore external IDs that are not found. |
| fetchResources | boolean (fetchResources) If true, will try to fetch the resources referred to in the relationship, based on the users access rights. Will silently fail to attatch the resources if the user lacks access to some of them. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
- Java SDK
{- "items": [
- {
- "externalId": "string"
}
], - "ignoreUnknownIds": false,
- "fetchResources": false
}Response samples
- 200
- 400
- 409
{- "items": [
- {
- "externalId": "string",
- "sourceExternalId": "string",
- "sourceType": "asset",
- "targetExternalId": "string",
- "targetType": "asset",
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "confidence": 1,
- "dataSetId": 1,
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "source": {
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "rootId": 1,
- "aggregates": {
- "childCount": 0,
- "depth": 0,
- "path": [
- {
- "id": 1
}
]
}, - "parentId": 1,
- "parentExternalId": "my.known.id",
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1
}, - "target": {
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "rootId": 1,
- "aggregates": {
- "childCount": 0,
- "depth": 0,
- "path": [
- {
- "id": 1
}
]
}, - "parentId": 1,
- "parentExternalId": "my.known.id",
- "externalId": "my.known.id",
- "name": "string",
- "description": "string",
- "dataSetId": 1,
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "source": "string",
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "geoLocation": {
- "type": "Feature",
- "geometry": {
- "type": "Point",
- "coordinates": [
- 0,
- 0
]
}, - "properties": { }
}, - "id": 1
}
}
]
}Update relationships
Update relationships between resources according to the partial definitions of the relationships given in the payload of the request. This means that fields not mentioned in the payload will remain unchanged. Up to 1000 relationships can be updated in one operation.
To delete a value from an optional value the setNull field should be set to true.
The order of the updated relationships in the response equals the order in the request.
Authorizations:
Request Body schema: application/jsonrequired
Data required to update relationships.
required | Array of objects (relationshipUpdate) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "items": [
- {
- "externalId": "string",
- "update": {
- "sourceType": {
- "set": "asset"
}, - "sourceExternalId": {
- "set": "string"
}, - "targetType": {
- "set": "asset"
}, - "targetExternalId": {
- "set": "string"
}, - "confidence": {
- "set": 1
}, - "startTime": {
- "set": 1730204346000
}, - "endTime": {
- "set": 1730204346000
}, - "dataSetId": {
- "set": 1
}, - "labels": {
- "add": [
- {
- "externalId": "my.known.id"
}
], - "remove": [
- {
- "externalId": "my.known.id"
}
]
}
}
}
]
}Response samples
- 200
- 400
- 409
{- "items": [
- {
- "externalId": "string",
- "sourceExternalId": "string",
- "sourceType": "asset",
- "targetExternalId": "string",
- "targetType": "asset",
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "confidence": 1,
- "dataSetId": 1,
- "labels": [
- {
- "externalId": "my.known.id"
}
], - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Annotations reflect contextual information in base CDF resource types, such as Files and Time series, that are not present on the object itself. The benefits of the annotations concept are threefold:
- The annotations concept is a good fit for enriching the base resources themselves, so that the overall data quality is higher in a given project.
- It is also a good fit for building reference datasets for data problems uniformly across customer projects. Product teams can then use those reference datasets to train machine learning models or validate the performance of their algorithms on actual customer data.
- Given a uniform way of labelling similar concepts across projects, it becomes easy for apps to agree on a consistent visual representation of those concepts.
Create annotations
Creates the given annotations.
Identifiers
An annotation must reference an annotated resource.
The reference can be made by providing the internal ID of the annotated resource.
Status
The annotation must have the status field set to either "suggested", "rejected", or "approved"
Access control
The caller must have read-access on all the annotated resources, otherwise the call will fail.
Annotation types and Data
The annotation type property must be set to one of the globally available annotation types.
See the documentation of the annotationType and data attributes for details.
The annotation data must conform to the schema provided by the annotation type.
Creating Application and User
The creating application and its version must be provided. The creating user must be provided, but if the
annotation is being created by a service, this can be set to null.
Authorizations:
Request Body schema: application/jsonrequired
A request for creating annotations
required | Array of objects (AnnotationsV2CreateSchema) [ 1 .. 1000 ] A list of annotations to create |
Responses
Request samples
- Payload
- JavaScript SDK
{- "items": [
- {
- "annotatedResourceType": "file",
- "annotatedResourceId": 1337,
- "annotationType": "pointcloud.BoundingVolume",
- "creatingApp": "cognite-vision",
- "creatingAppVersion": "1.2.1",
- "creatingUser": "john.doe@cognite.com",
- "data": {
- "assetRef": {
- "externalId": "abc"
}, - "symbolRegion": {
- "xMin": 0.1,
- "xMax": 0.2,
- "yMin": 0.1,
- "yMax": 0.2
}, - "textRegion": {
- "xMin": 0.2,
- "xMax": 0.3,
- "yMin": 0.2,
- "yMax": 0.3
}, - "pageNumber": 43
}, - "status": "approved"
}
]
}Response samples
- 201
- 400
{- "items": [
- {
- "id": 4096,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "annotatedResourceType": "file",
- "annotatedResourceId": 1337,
- "annotationType": "pointcloud.BoundingVolume",
- "creatingApp": "cognite-vision",
- "creatingAppVersion": "1.2.1",
- "creatingUser": "john.doe@cognite.com",
- "data": {
- "assetRef": {
- "externalId": "abc"
}, - "symbolRegion": {
- "xMin": 0.1,
- "xMax": 0.2,
- "yMin": 0.1,
- "yMax": 0.2
}, - "textRegion": {
- "xMin": 0.2,
- "xMax": 0.3,
- "yMin": 0.2,
- "yMax": 0.3
}, - "pageNumber": 43
}, - "status": "approved"
}
]
}Delete annotations
Deletes the referenced annotations completely.
The caller must have read-access on all the annotated resources, otherwise the call will fail.
Authorizations:
Request Body schema: application/jsonrequired
A request referencing existing annotations
required | Array of objects (AnnotationsV2ReferenceSchema) [ 1 .. 1000 ] A list of existing annotation references |
Responses
Request samples
- Payload
- JavaScript SDK
{- "items": [
- {
- "id": 4096
}
]
}Response samples
- 400
{- "error": {
- "code": 401,
- "message": "Could not authenticate.",
- "missing": [
- { }
], - "duplicated": [
- { }
]
}
}Filter annotations
Lists the annotations the caller has access to, based on a filter.
The caller must have read-access on the annotated resources listed in the filter, otherwise the call will fail.
Authorizations:
Request Body schema: application/jsonrequired
A request specifying the annotation listing behavior
| cursor | string or null [ 1 .. 255 ] characters A cursor pointing to another page of results |
| limit | integer [ 1 .. 1000 ] Default: 25 |
required | object (AnnotationsV2FilterSchema) A filter to apply on annotations |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
{- "cursor": "MzE1NjAwMDcxNzQ0ODI5",
- "limit": 25,
- "filter": {
- "annotatedResourceType": "file",
- "annotatedResourceIds": [
- {
- "id": 1066
}, - {
- "id": 1067
}
], - "status": "approved",
- "data": {
- "label": "cat"
}
}
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 4096,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "annotatedResourceType": "file",
- "annotatedResourceId": 1337,
- "annotationType": "pointcloud.BoundingVolume",
- "creatingApp": "cognite-vision",
- "creatingAppVersion": "1.2.1",
- "creatingUser": "john.doe@cognite.com",
- "data": {
- "assetRef": {
- "externalId": "abc"
}, - "symbolRegion": {
- "xMin": 0.1,
- "xMax": 0.2,
- "yMin": 0.1,
- "yMax": 0.2
}, - "textRegion": {
- "xMin": 0.2,
- "xMax": 0.3,
- "yMin": 0.2,
- "yMax": 0.3
}, - "pageNumber": 43
}, - "status": "approved"
}
], - "nextCursor": null
}Get an annotation
Retrieves the referenced annotation.
The caller must have read-access on the annotated resource, otherwise the call will fail.
Authorizations:
path Parameters
| annotationId required | integer <int64> (AnnotationId) [ 1 .. 9007199254740991 ] Example: 4096 The internal ID of the annotation |
Responses
Request samples
- JavaScript SDK
const annotationIds = [{ id: 1 }, { id: 2 }]; const response = await client.annotations.retrieve(annotationIds);
Response samples
- 200
- 400
{- "id": 4096,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "annotatedResourceType": "file",
- "annotatedResourceId": 1337,
- "annotationType": "pointcloud.BoundingVolume",
- "creatingApp": "cognite-vision",
- "creatingAppVersion": "1.2.1",
- "creatingUser": "john.doe@cognite.com",
- "data": {
- "assetRef": {
- "externalId": "abc"
}, - "symbolRegion": {
- "xMin": 0.1,
- "xMax": 0.2,
- "yMin": 0.1,
- "yMax": 0.2
}, - "textRegion": {
- "xMin": 0.2,
- "xMax": 0.3,
- "yMin": 0.2,
- "yMax": 0.3
}, - "pageNumber": 43
}, - "status": "approved"
}Retrieve annotations
Retrieves the referenced annotations.
The caller must have read-access on all the annotated resources, otherwise the call will fail.
Authorizations:
Request Body schema: application/jsonrequired
A request referencing existing annotations
required | Array of objects (AnnotationsV2ReferenceSchema) [ 1 .. 1000 ] A list of existing annotation references |
Responses
Request samples
- Payload
- JavaScript SDK
{- "items": [
- {
- "id": 4096
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 4096,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "annotatedResourceType": "file",
- "annotatedResourceId": 1337,
- "annotationType": "pointcloud.BoundingVolume",
- "creatingApp": "cognite-vision",
- "creatingAppVersion": "1.2.1",
- "creatingUser": "john.doe@cognite.com",
- "data": {
- "assetRef": {
- "externalId": "abc"
}, - "symbolRegion": {
- "xMin": 0.1,
- "xMax": 0.2,
- "yMin": 0.1,
- "yMax": 0.2
}, - "textRegion": {
- "xMin": 0.2,
- "xMax": 0.3,
- "yMin": 0.2,
- "yMax": 0.3
}, - "pageNumber": 43
}, - "status": "approved"
}
]
}Reverse lookup
Provided an annotation filter and an annotated resource type (file/3D), returns ids of annotated resources having annotations matching the filter. A typical use case is looking up files with annotations linking to a specific asset. Only ids of annotated resources that the client has access to will be returned.
In beta. Available only when the cdf-version header with the beta suffix value is provided.
Authorizations:
Request Body schema: application/jsonrequired
A request to look up annotated resource ids based on having annotations matching a filter.
required | object (AnnotationsV2ReverseLookupFilterSchema) A filter for reverse lookups |
| limit | integer [ 1 .. 1000 ] Default: 100 |
| cursor | string or null [ 1 .. 255 ] characters A cursor pointing to another page of results |
Responses
Request samples
- Payload
- JavaScript SDK
{- "filter": {
- "annotatedResourceType": "file",
- "status": "approved",
- "data": {
- "label": "cat",
- "fileRef": {
- "externalId": "abc"
}
}
}, - "limit": 100,
- "cursor": "MzE1NjAwMDcxNzQ0ODI5"
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 123,
- "externalId": "abc-1066"
}
], - "nextCursor": null,
- "annotatedResourceType": "file"
}Suggest annotations
Suggests the given annotations, i.e. creates them with status set to "suggested"
Identifiers
An annotation must reference an annotated resource.
The reference can be made by providing the internal ID of the annotated resource.
Access control
The caller must have read-access on all the annotated resources, otherwise the call will fail.
Annotation types and Data
The annotation type property must be set to one of the globally available annotation types.
See the documentation of the annotationType and data attributes for details.
The annotation data must conform to the schema provided by the annotation type.
Creating Application and User
The creating application and its version must be provided. The creating user must be provided, but if the
annotation is being created by a service, this can be set to null.
Authorizations:
Request Body schema: application/jsonrequired
A request for suggesting annotations, i.e., creating them with the "suggested" status
required | Array of objects (AnnotationsV2SuggestSchema) [ 1 .. 1000 ] A list of annotations to suggest |
Responses
Request samples
- Payload
- JavaScript SDK
{- "items": [
- {
- "annotatedResourceType": "file",
- "annotatedResourceId": 1337,
- "annotationType": "pointcloud.BoundingVolume",
- "creatingApp": "cognite-vision",
- "creatingAppVersion": "1.2.1",
- "creatingUser": "john.doe@cognite.com",
- "data": {
- "assetRef": {
- "externalId": "abc"
}, - "symbolRegion": {
- "xMin": 0.1,
- "xMax": 0.2,
- "yMin": 0.1,
- "yMax": 0.2
}, - "textRegion": {
- "xMin": 0.2,
- "xMax": 0.3,
- "yMin": 0.2,
- "yMax": 0.3
}, - "pageNumber": 43
}
}
]
}Response samples
- 201
- 400
{- "items": [
- {
- "id": 4096,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "annotatedResourceType": "file",
- "annotatedResourceId": 1337,
- "annotationType": "pointcloud.BoundingVolume",
- "creatingApp": "cognite-vision",
- "creatingAppVersion": "1.2.1",
- "creatingUser": "john.doe@cognite.com",
- "data": {
- "assetRef": {
- "externalId": "abc"
}, - "symbolRegion": {
- "xMin": 0.1,
- "xMax": 0.2,
- "yMin": 0.1,
- "yMax": 0.2
}, - "textRegion": {
- "xMin": 0.2,
- "xMax": 0.3,
- "yMin": 0.2,
- "yMax": 0.3
}, - "pageNumber": 43
}, - "status": "approved"
}
]
}Update annotations
Updates the referenced annotations.
The caller must have read-access on all the annotated resources, otherwise the call will fail.
Authorizations:
Request Body schema: application/jsonrequired
A request for updating existing annotations
required | Array of objects (AnnotationsV2UpdateItemSchema) [ 1 .. 1000 ] |
Responses
Request samples
- Payload
- JavaScript SDK
{- "items": [
- {
- "id": 4096,
- "update": {
- "data": {
- "set": {
- "assetRef": {
- "externalId": "abc"
}, - "symbolRegion": {
- "xMin": 0.1,
- "xMax": 0.2,
- "yMin": 0.1,
- "yMax": 0.2
}, - "textRegion": {
- "xMin": 0.4,
- "xMax": 0.5,
- "yMin": 0.4,
- "yMax": 0.5
}, - "pageNumber": 43
}
}
}
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 4096,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "annotatedResourceType": "file",
- "annotatedResourceId": 1337,
- "annotationType": "pointcloud.BoundingVolume",
- "creatingApp": "cognite-vision",
- "creatingAppVersion": "1.2.1",
- "creatingUser": "john.doe@cognite.com",
- "data": {
- "assetRef": {
- "externalId": "abc"
}, - "symbolRegion": {
- "xMin": 0.1,
- "xMax": 0.2,
- "yMin": 0.1,
- "yMax": 0.2
}, - "textRegion": {
- "xMin": 0.2,
- "xMax": 0.3,
- "yMin": 0.2,
- "yMax": 0.3
}, - "pageNumber": 43
}, - "status": "approved"
}
]
}Transformations enable users to use Spark SQL queries to transform data from the CDF staging area, RAW, into the CDF data model.
Concurrency limits
The number of concurrent (parallel) jobs are governed by limits. If a request exceeds one of the limits, the job fails to run. This limitation also applies to scheduled transformations.
The limits for the transformation service are described in the table below. Note that under high load, some deviation from the limits might occur for short periods as the service scales up.
| Limit | Per project |
|---|---|
| Concurrency | 10 parallel jobs |
Cancel a transformation
Authorizations:
Request Body schema: application/jsonrequired
| externalId required | string The external ID provided by the client. Must be unique for the resource type. |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "externalId": "string"
}Response samples
- 200
- 400
- 403
{ }Create transformations
Create a maximum of 1000 transformations per request.
Authorizations:
Request Body schema: application/jsonrequired
Array of objects (TransformationCreate) <= 1000 items |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "items": [
- {
- "name": "string",
- "query": "string",
- "destination": {
- "type": "assets"
}, - "conflictMode": "abort",
- "isPublic": true,
- "sourceOidcCredentials": {
- "clientId": "string",
- "clientSecret": "string",
- "scopes": "string",
- "tokenUri": "string",
- "cdfProjectName": "string",
- "audience": "string"
}, - "destinationOidcCredentials": {
- "clientId": "string",
- "clientSecret": "string",
- "scopes": "string",
- "tokenUri": "string",
- "cdfProjectName": "string",
- "audience": "string"
}, - "sourceNonce": {
- "sessionId": 0,
- "nonce": "string",
- "cdfProjectName": "string",
- "clientId": "string"
}, - "destinationNonce": {
- "sessionId": 0,
- "nonce": "string",
- "cdfProjectName": "string",
- "clientId": "string"
}, - "externalId": "string",
- "ignoreNullFields": true,
- "dataSetId": 0,
- "tags": [
- "string"
]
}
]
}Response samples
- 200
- 400
- 403
- 409
{- "items": [
- {
- "id": 0,
- "name": "string",
- "query": "string",
- "destination": {
- "type": "assets"
}, - "conflictMode": "abort",
- "isPublic": true,
- "blocked": {
- "reason": "string",
- "createdTime": 0
}, - "createdTime": 0,
- "lastUpdatedTime": 0,
- "owner": "string",
- "ownerIsCurrentUser": true,
- "hasSourceOidcCredentials": true,
- "hasDestinationOidcCredentials": true,
- "sourceSession": {
- "clientId": "string",
- "sessionId": 0,
- "projectName": "string"
}, - "destinationSession": {
- "clientId": "string",
- "sessionId": 0,
- "projectName": "string"
}, - "lastFinishedJob": {
- "id": 0,
- "uuid": "string",
- "transformationId": 0,
- "transformationExternalId": "string",
- "sourceProject": "string",
- "destinationProject": "string",
- "destination": {
- "type": "assets"
}, - "conflictMode": "abort",
- "query": "string",
- "createdTime": 0,
- "startedTime": 0,
- "finishedTime": 0,
- "lastSeenTime": 0,
- "error": "string",
- "ignoreNullFields": true,
- "status": "Completed"
}, - "runningJob": {
- "id": 0,
- "uuid": "string",
- "transformationId": 0,
- "transformationExternalId": "string",
- "sourceProject": "string",
- "destinationProject": "string",
- "destination": {
- "type": "assets"
}, - "conflictMode": "abort",
- "query": "string",
- "createdTime": 0,
- "startedTime": 0,
- "finishedTime": 0,
- "lastSeenTime": 0,
- "error": "string",
- "ignoreNullFields": true,
- "status": "Completed"
}, - "schedule": {
- "id": 0,
- "externalId": "string",
- "createdTime": 0,
- "lastUpdatedTime": 0,
- "interval": "0 0 * * *",
- "isPaused": true
}, - "externalId": "string",
- "ignoreNullFields": true,
- "dataSetId": 0,
- "tags": [
- "string"
]
}
]
}Delete transformations
Delete a maximum of 1000 transformations by ids and externalIds per request.
Authorizations:
Request Body schema: application/jsonrequired
Array of TransformationCogniteExternalId (object) or TransformationCogniteInternalId (object) <= 1000 items | |
| ignoreUnknownIds | boolean Ignore IDs and external IDs that are not found. Defaults to false. |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "items": [
- {
- "externalId": "string"
}
], - "ignoreUnknownIds": true
}Response samples
- 200
- 400
- 403
- 409
{ }Filter transformations
Filter transformations. Use nextCursor to paginate through the results.
Authorizations:
Request Body schema: application/jsonrequired
required | object (TransformationFilter) |
| limit | integer <int32> |
| cursor | string |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "filter": {
- "isPublic": true,
- "nameRegex": "string",
- "queryRegex": "string",
- "destinationType": "string",
- "conflictMode": "abort",
- "hasBlockedError": true,
- "cdfProjectName": "string",
- "createdTime": {
- "min": 0,
- "max": 0
}, - "lastUpdatedTime": {
- "min": 0,
- "max": 0
}, - "dataSetIds": [
- {
- "externalId": "string"
}
], - "tags": {
- "containsAny": [
- "string"
]
}
}, - "limit": 0,
- "cursor": "string"
}Response samples
- 200
- 400
- 403
{- "items": [
- {
- "id": 0,
- "name": "string",
- "query": "string",
- "destination": {
- "type": "assets"
}, - "conflictMode": "abort",
- "isPublic": true,
- "blocked": {
- "reason": "string",
- "createdTime": 0
}, - "createdTime": 0,
- "lastUpdatedTime": 0,
- "owner": "string",
- "ownerIsCurrentUser": true,
- "hasSourceOidcCredentials": true,
- "hasDestinationOidcCredentials": true,
- "sourceSession": {
- "clientId": "string",
- "sessionId": 0,
- "projectName": "string"
}, - "destinationSession": {
- "clientId": "string",
- "sessionId": 0,
- "projectName": "string"
}, - "lastFinishedJob": {
- "id": 0,
- "uuid": "string",
- "transformationId": 0,
- "transformationExternalId": "string",
- "sourceProject": "string",
- "destinationProject": "string",
- "destination": {
- "type": "assets"
}, - "conflictMode": "abort",
- "query": "string",
- "createdTime": 0,
- "startedTime": 0,
- "finishedTime": 0,
- "lastSeenTime": 0,
- "error": "string",
- "ignoreNullFields": true,
- "status": "Completed"
}, - "runningJob": {
- "id": 0,
- "uuid": "string",
- "transformationId": 0,
- "transformationExternalId": "string",
- "sourceProject": "string",
- "destinationProject": "string",
- "destination": {
- "type": "assets"
}, - "conflictMode": "abort",
- "query": "string",
- "createdTime": 0,
- "startedTime": 0,
- "finishedTime": 0,
- "lastSeenTime": 0,
- "error": "string",
- "ignoreNullFields": true,
- "status": "Completed"
}, - "schedule": {
- "id": 0,
- "externalId": "string",
- "createdTime": 0,
- "lastUpdatedTime": 0,
- "interval": "0 0 * * *",
- "isPaused": true
}, - "externalId": "string",
- "ignoreNullFields": true,
- "dataSetId": 0,
- "tags": [
- "string"
]
}
], - "nextCursor": "string"
}List transformations
List transformations. Use nextCursor to paginate through the results.
Authorizations:
query Parameters
| limit | integer <int32> [ 1 .. 1000 ] Limits the number of results to be returned. The maximum is 1000, default limit is 100. |
| cursor | string Cursor for paging through results. |
| includePublic | boolean Whether public transformations should be included in the results. The default is true. |
| withJobDetails | boolean Whether transformations should contain information about jobs. The default is true. |
Responses
Response samples
- 200
- 400
- 403
{- "items": [
- {
- "id": 0,
- "name": "string",
- "query": "string",
- "destination": {
- "type": "assets"
}, - "conflictMode": "abort",
- "isPublic": true,
- "blocked": {
- "reason": "string",
- "createdTime": 0
}, - "createdTime": 0,
- "lastUpdatedTime": 0,
- "owner": "string",
- "ownerIsCurrentUser": true,
- "hasSourceOidcCredentials": true,
- "hasDestinationOidcCredentials": true,
- "sourceSession": {
- "clientId": "string",
- "sessionId": 0,
- "projectName": "string"
}, - "destinationSession": {
- "clientId": "string",
- "sessionId": 0,
- "projectName": "string"
}, - "lastFinishedJob": {
- "id": 0,
- "uuid": "string",
- "transformationId": 0,
- "transformationExternalId": "string",
- "sourceProject": "string",
- "destinationProject": "string",
- "destination": {
- "type": "assets"
}, - "conflictMode": "abort",
- "query": "string",
- "createdTime": 0,
- "startedTime": 0,
- "finishedTime": 0,
- "lastSeenTime": 0,
- "error": "string",
- "ignoreNullFields": true,
- "status": "Completed"
}, - "runningJob": {
- "id": 0,
- "uuid": "string",
- "transformationId": 0,
- "transformationExternalId": "string",
- "sourceProject": "string",
- "destinationProject": "string",
- "destination": {
- "type": "assets"
}, - "conflictMode": "abort",
- "query": "string",
- "createdTime": 0,
- "startedTime": 0,
- "finishedTime": 0,
- "lastSeenTime": 0,
- "error": "string",
- "ignoreNullFields": true,
- "status": "Completed"
}, - "schedule": {
- "id": 0,
- "externalId": "string",
- "createdTime": 0,
- "lastUpdatedTime": 0,
- "interval": "0 0 * * *",
- "isPaused": true
}, - "externalId": "string",
- "ignoreNullFields": true,
- "dataSetId": 0,
- "tags": [
- "string"
]
}
], - "nextCursor": "string"
}Retrieve transformations
Retrieve a maximum of 1000 transformations by ids and externalIds per request.
Authorizations:
Request Body schema: application/jsonrequired
Array of TransformationCogniteExternalId (object) or TransformationCogniteInternalId (object) <= 1000 items | |
| ignoreUnknownIds | boolean Ignore IDs and external IDs that are not found. Defaults to false. |
| withJobDetails required | boolean Whether the transformations will be returned with running job and last created job details. |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "items": [
- {
- "externalId": "string"
}
], - "ignoreUnknownIds": true,
- "withJobDetails": true
}Response samples
- 200
- 400
- 403
- 409
{- "items": [
- {
- "id": 0,
- "name": "string",
- "query": "string",
- "destination": {
- "type": "assets"
}, - "conflictMode": "abort",
- "isPublic": true,
- "blocked": {
- "reason": "string",
- "createdTime": 0
}, - "createdTime": 0,
- "lastUpdatedTime": 0,
- "owner": "string",
- "ownerIsCurrentUser": true,
- "hasSourceOidcCredentials": true,
- "hasDestinationOidcCredentials": true,
- "sourceSession": {
- "clientId": "string",
- "sessionId": 0,
- "projectName": "string"
}, - "destinationSession": {
- "clientId": "string",
- "sessionId": 0,
- "projectName": "string"
}, - "lastFinishedJob": {
- "id": 0,
- "uuid": "string",
- "transformationId": 0,
- "transformationExternalId": "string",
- "sourceProject": "string",
- "destinationProject": "string",
- "destination": {
- "type": "assets"
}, - "conflictMode": "abort",
- "query": "string",
- "createdTime": 0,
- "startedTime": 0,
- "finishedTime": 0,
- "lastSeenTime": 0,
- "error": "string",
- "ignoreNullFields": true,
- "status": "Completed"
}, - "runningJob": {
- "id": 0,
- "uuid": "string",
- "transformationId": 0,
- "transformationExternalId": "string",
- "sourceProject": "string",
- "destinationProject": "string",
- "destination": {
- "type": "assets"
}, - "conflictMode": "abort",
- "query": "string",
- "createdTime": 0,
- "startedTime": 0,
- "finishedTime": 0,
- "lastSeenTime": 0,
- "error": "string",
- "ignoreNullFields": true,
- "status": "Completed"
}, - "schedule": {
- "id": 0,
- "externalId": "string",
- "createdTime": 0,
- "lastUpdatedTime": 0,
- "interval": "0 0 * * *",
- "isPaused": true
}, - "externalId": "string",
- "ignoreNullFields": true,
- "dataSetId": 0,
- "tags": [
- "string"
]
}
]
}Run a transformation
Authorizations:
Request Body schema: application/jsonrequired
| externalId required | string |
object (NonceCredentials) |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "externalId": "string",
- "nonce": {
- "sessionId": 0,
- "nonce": "string",
- "cdfProjectName": "string",
- "clientId": "string"
}
}Response samples
- 200
- 400
- 403
{- "id": 0,
- "uuid": "string",
- "transformationId": 0,
- "transformationExternalId": "string",
- "sourceProject": "string",
- "destinationProject": "string",
- "destination": {
- "type": "assets"
}, - "conflictMode": "abort",
- "query": "string",
- "createdTime": 0,
- "startedTime": 0,
- "finishedTime": 0,
- "lastSeenTime": 0,
- "error": "string",
- "ignoreNullFields": true,
- "status": "Completed"
}Update transformations
Update the attributes of transformations, maximum 1000 per request.
Authorizations:
Request Body schema: application/jsonrequired
Array of UpdateItemWithExternalId_TransformationUpdate (object) or UpdateItemWithId_TransformationUpdate (object) <= 1000 items |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "items": [
- {
- "update": {
- "name": {
- "set": "string"
}, - "externalId": {
- "set": "my.known.id"
}, - "destination": {
- "set": {
- "type": "assets"
}
}, - "conflictMode": {
- "set": "abort"
}, - "query": {
- "set": "string"
}, - "sourceOidcCredentials": {
- "setNull": true
}, - "destinationOidcCredentials": {
- "setNull": true
}, - "sourceNonce": {
- "setNull": true
}, - "destinationNonce": {
- "setNull": true
}, - "isPublic": {
- "set": true
}, - "ignoreNullFields": {
- "set": true
}, - "dataSetId": {
- "setNull": true
}, - "tags": {
- "set": [
- "string"
]
}
}, - "externalId": "string"
}
]
}Response samples
- 200
- 400
- 403
- 409
{- "items": [
- {
- "id": 0,
- "name": "string",
- "query": "string",
- "destination": {
- "type": "assets"
}, - "conflictMode": "abort",
- "isPublic": true,
- "blocked": {
- "reason": "string",
- "createdTime": 0
}, - "createdTime": 0,
- "lastUpdatedTime": 0,
- "owner": "string",
- "ownerIsCurrentUser": true,
- "hasSourceOidcCredentials": true,
- "hasDestinationOidcCredentials": true,
- "sourceSession": {
- "clientId": "string",
- "sessionId": 0,
- "projectName": "string"
}, - "destinationSession": {
- "clientId": "string",
- "sessionId": 0,
- "projectName": "string"
}, - "lastFinishedJob": {
- "id": 0,
- "uuid": "string",
- "transformationId": 0,
- "transformationExternalId": "string",
- "sourceProject": "string",
- "destinationProject": "string",
- "destination": {
- "type": "assets"
}, - "conflictMode": "abort",
- "query": "string",
- "createdTime": 0,
- "startedTime": 0,
- "finishedTime": 0,
- "lastSeenTime": 0,
- "error": "string",
- "ignoreNullFields": true,
- "status": "Completed"
}, - "runningJob": {
- "id": 0,
- "uuid": "string",
- "transformationId": 0,
- "transformationExternalId": "string",
- "sourceProject": "string",
- "destinationProject": "string",
- "destination": {
- "type": "assets"
}, - "conflictMode": "abort",
- "query": "string",
- "createdTime": 0,
- "startedTime": 0,
- "finishedTime": 0,
- "lastSeenTime": 0,
- "error": "string",
- "ignoreNullFields": true,
- "status": "Completed"
}, - "schedule": {
- "id": 0,
- "externalId": "string",
- "createdTime": 0,
- "lastUpdatedTime": 0,
- "interval": "0 0 * * *",
- "isPaused": true
}, - "externalId": "string",
- "ignoreNullFields": true,
- "dataSetId": 0,
- "tags": [
- "string"
]
}
]
}List job metrics by job id
Authorizations:
path Parameters
| id required | integer <int32> The job id. |
Responses
Request samples
- Python SDK
- Java SDK
res = client.transformations.jobs.list_metrics(id=1)
Response samples
- 200
- 400
- 403
{- "items": [
- {
- "timestamp": 0,
- "name": "assets.read",
- "count": 0
}
]
}List jobs
Authorizations:
query Parameters
| transformationId | integer <int32> List only jobs for the specified transformation. The transformation is identified by ID. |
| transformationExternalId | string List only jobs for the specified transformation. The transformation is identified by external ID. |
| limit | integer <int32> [ 1 .. 1000 ] Limits the number of results to be returned. The maximum is 1000, default limit is 100. |
| cursor | string Cursor for paging through results. |
Responses
Request samples
- Python SDK
- Java SDK
transformation_jobs_list = client.transformations.jobs.list() transformation_jobs_list = client.transformations.jobs.list(transformation_id=1)
Response samples
- 200
- 400
- 403
{- "items": [
- {
- "id": 0,
- "uuid": "string",
- "transformationId": 0,
- "transformationExternalId": "string",
- "sourceProject": "string",
- "destinationProject": "string",
- "destination": {
- "type": "assets"
}, - "conflictMode": "abort",
- "query": "string",
- "createdTime": 0,
- "startedTime": 0,
- "finishedTime": 0,
- "lastSeenTime": 0,
- "error": "string",
- "ignoreNullFields": true,
- "status": "Completed"
}
], - "nextCursor": "string"
}Retrieve jobs by ids
Retrieve a maximum of 1000 jobs by ids per request.
Authorizations:
Request Body schema: application/jsonrequired
Array of objects (TransformationCogniteInternalId) | |
| ignoreUnknownIds | boolean Ignore IDs and external IDs that are not found. Defaults to false. |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 0
}
], - "ignoreUnknownIds": true
}Response samples
- 200
- 400
- 403
- 409
{- "items": [
- {
- "id": 0,
- "uuid": "string",
- "transformationId": 0,
- "transformationExternalId": "string",
- "sourceProject": "string",
- "destinationProject": "string",
- "destination": {
- "type": "assets"
}, - "conflictMode": "abort",
- "query": "string",
- "createdTime": 0,
- "startedTime": 0,
- "finishedTime": 0,
- "lastSeenTime": 0,
- "error": "string",
- "ignoreNullFields": true,
- "status": "Completed"
}
]
}Transformation schedules allow you to run transformations with a specific input at intervals defined by a cron expression. These transformation jobs will be asynchronous and show up in the transformation job list. Visit http://www.cronmaker.com to generate a cron expression with a UI.
List all schedules
List all transformation schedules. Use nextCursor to paginate through the results.
Authorizations:
query Parameters
| limit | integer <int32> [ 1 .. 1000 ] Limits the number of results to be returned. The maximum is 1000, default limit is 100. |
| cursor | string Cursor for paging through results. |
| includePublic | boolean Whether public transformations should be included in the results. The default is true. |
Responses
Request samples
- Python SDK
- Java SDK
schedules_list = client.transformations.schedules.list()
Response samples
- 200
- 400
- 403
- 409
{- "items": [
- {
- "id": 0,
- "externalId": "string",
- "createdTime": 0,
- "lastUpdatedTime": 0,
- "interval": "0 0 * * *",
- "isPaused": true
}
], - "nextCursor": "string"
}Retrieve schedules
Retrieve transformation schedules by transformation IDs or external IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of transformation IDs of schedules to retrieve. Must be up to a maximum of 1000 items and all of them must be unique.
Array of TransformationCogniteExternalId (object) or TransformationCogniteInternalId (object) <= 1000 items | |
| ignoreUnknownIds | boolean Ignore IDs and external IDs that are not found. Defaults to false. |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "items": [
- {
- "externalId": "string"
}
], - "ignoreUnknownIds": true
}Response samples
- 200
- 400
- 403
- 409
{- "items": [
- {
- "id": 0,
- "externalId": "string",
- "createdTime": 0,
- "lastUpdatedTime": 0,
- "interval": "0 0 * * *",
- "isPaused": true
}
]
}Schedule transformations
Schedule transformations with the specified configurations.
Authorizations:
Request Body schema: application/jsonrequired
List of the schedules to create. Must be up to a maximum of 1000 items.
Array of ScheduleParametersWithExternalId (object) or ScheduleParametersWithId (object) |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "items": [
- {
- "interval": "0 0 * * *",
- "isPaused": true,
- "externalId": "string"
}
]
}Response samples
- 201
- 400
- 403
- 409
{- "items": [
- {
- "id": 0,
- "externalId": "string",
- "createdTime": 0,
- "lastUpdatedTime": 0,
- "interval": "0 0 * * *",
- "isPaused": true
}
]
}Unschedule transformations
Unschedule transformations by IDs or externalIds.
Authorizations:
Request Body schema: application/jsonrequired
List of transformation IDs of schedules to delete. Must be up to a maximum of 1000 items and all of them must be unique.
Array of TransformationCogniteExternalId (object) or TransformationCogniteInternalId (object) <= 1000 items | |
| ignoreUnknownIds | boolean Ignore IDs and external IDs that are not found. Defaults to false. |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "items": [
- {
- "externalId": "string"
}
], - "ignoreUnknownIds": true
}Response samples
- 200
- 400
- 403
- 409
{ }Update schedules
Authorizations:
Request Body schema: application/jsonrequired
List of schedule updates. Must be up to a maximum of 1000 items.
Array of UpdateItemWithExternalId_ScheduleUpdate (object) or UpdateItemWithId_ScheduleUpdate (object) |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "items": [
- {
- "update": {
- "interval": {
- "set": "0 0 * * *"
}, - "isPaused": {
- "set": true
}
}, - "externalId": "string"
}
]
}Response samples
- 200
- 400
- 403
- 409
{- "items": [
- {
- "id": 0,
- "externalId": "string",
- "createdTime": 0,
- "lastUpdatedTime": 0,
- "interval": "0 0 * * *",
- "isPaused": true
}
]
}Transformation notifications let users know when a job fails if subscribed.
Delete notification subscriptions by notification ID
Deletes the specified notification subscriptions on the transformation. Requests to delete non-existing subscriptions do nothing, but do not throw an error.
Authorizations:
Request Body schema: application/jsonrequired
List of IDs to be deleted.
Array of objects (TransformationCogniteInternalId) |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "items": [
- {
- "id": 0
}
]
}Response samples
- 200
- 400
- 403
- 409
{ }List notification subscriptions
Authorizations:
query Parameters
| transformationId | integer <int32> List only notifications for the specified transformation. The transformation is identified by ID. |
| transformationExternalId | string List only notifications for the specified transformation. The transformation is identified by external ID. |
| destination | string Filter by notification destination. |
| limit | integer <int32> [ 1 .. 1000 ] Limits the number of results to be returned. The maximum is 1000, default limit is 100. |
| cursor | string Cursor for paging through results. |
Responses
Request samples
- Python SDK
- Java SDK
notifications_list = client.transformations.notifications.list() notifications_list = client.transformations.notifications.list(transformation_id = 1)
Response samples
- 200
- 400
- 403
{- "items": [
- {
- "id": 0,
- "createdTime": 0,
- "lastUpdatedTime": 0,
- "transformationId": 0,
- "destination": "string"
}
], - "nextCursor": "string"
}Subscribe for notifications
Subscribe for notifications on the transformation errors.
Authorizations:
Request Body schema: application/jsonrequired
List of the notifications for new subscriptions. Must be up to a maximum of 1000 items.
Array of NotificationCreateWithExternalId (object) or NotificationCreateWithId (object) <= 1000 items |
Responses
Request samples
- Payload
- Python SDK
- Java SDK
{- "items": [
- {
- "destination": "string",
- "transformationExternalId": "string"
}
]
}Response samples
- 200
- 400
- 403
- 409
{- "items": [
- {
- "id": 0,
- "createdTime": 0,
- "lastUpdatedTime": 0,
- "transformationId": 0,
- "destination": "string"
}
]
}Run query
Preview a SQL query.
Authorizations:
Request Body schema: application/jsonrequired
| query required | string SQL query to run for preview. |
| convertToString required | boolean Stringify values in the query results. |
| limit | integer <int32> End-result limit of the query. |
| sourceLimit | integer <int32> Limit for how many rows to download from the data sources. |
| inferSchemaLimit | integer <int32> Limit for how many rows that are used for inferring schema. Default is 10,000. |
| timeout | integer <int32> Number of seconds to wait before cancelling a query. The default, and maximum, is 240. |
Responses
Request samples
- Payload
- Python SDK
{- "query": "string",
- "convertToString": true,
- "limit": 0,
- "sourceLimit": 0,
- "inferSchemaLimit": 0,
- "timeout": 0
}Response samples
- 200
- 400
- 403
{- "schema": {
- "items": [
- {
- "name": "string",
- "sqlType": "string",
- "type": {
- "type": "string"
}, - "nullable": true
}
]
}, - "results": {
- "items": [
- {
- "property1": "string",
- "property2": "string"
}
]
}
}Get Instance schema.
For View centric schema, viewSpace, viewExternalId, viewVersion need to be specified while withInstanceSpace, isConnectionDefinition, instanceType are optional . For Data Model centric schema, dataModelSpace, dataModelExternalId, dataModelVersion, type need to be specified and relationshipFromType is optional. For Both scenarios conflictMode is required.
Authorizations:
query Parameters
| conflictMode | string Enum: "abort" "upsert" "update" "delete" conflict mode of the transformation.
One of the following conflictMode types can be provided:
|
| viewSpace | string non-empty Space of the View. Not required if |
| viewExternalId | string non-empty External id of the View. Not required if |
| viewVersion | string non-empty Version of the View. Not required if |
| instanceType | string Enum: "nodes" "edges" Instance type to deal with |
| withInstanceSpace | boolean Is instance space set at the transformation config or not |
| isConnectionDefinition | boolean If the edge is a connection definition or not |
| dataModelSpace | string non-empty Space of the Data Model. Relevant for Data Model centric schema. |
| dataModelExternalId | string non-empty External id of the Data Model. Relevant for Data Model centric schema. |
| dataModelVersion | string non-empty Version of the Data Model. Relevant for Data Model centric schema. |
| type | string non-empty External id of the View in the Data model. Relevant for Data Model centric schema. |
| relationshipFromType | string non-empty Property Identifier of Connection Definition in |
Responses
Response samples
- 200
- 400
- 403
{- "items": [
- {
- "name": "string",
- "sqlType": "string",
- "type": {
- "type": "string"
}, - "nullable": true
}
]
}Get the schema of a sequence
Authorizations:
query Parameters
| externalId required | string non-empty External ID of the Sequence |
Responses
Response samples
- 200
- 400
- 403
{- "items": [
- {
- "name": "string",
- "sqlType": "string",
- "type": {
- "type": "string"
}, - "nullable": true
}
]
}Get the schema of resource type
Authorizations:
path Parameters
| schemaType required | string Name of the target schema type, please provide one of the following:
|
query Parameters
| conflictMode | string One of the following conflictMode types can be provided:
|
Responses
Request samples
- Python SDK
from cognite.client.data_classes import TransformationDestination columns = client.transformations.schema.retrieve(destination = TransformationDestination.assets())
Response samples
- 200
- 400
- 403
{- "items": [
- {
- "name": "string",
- "sqlType": "string",
- "type": {
- "type": "string"
}, - "nullable": true
}
]
}Functions enables Python code to be hosted and executed in the cloud, on demand or by using a schedule. Execution, status and logs are available through the API. A function is uploaded to the Files API as a zip file with at least a Python file called handler.py (unless specified otherwise through the functionPath-argument) that must contain a function named handle with any of the following arguments: data, client, secrets, or 'function_call_info', which are passed into the function.
The latest version of Cognite SDK's are available, and additional python packages and version specifications can be defined in a requirements.txt in the root of the zip.
Activate Functions
Activate Cognite Functions. This will create the necessary backend infrastructure for Cognite Functions.
Authorizations:
Responses
Request samples
- Python SDK
status = client.functions.activate()
Response samples
- 202
- 400
{- "status": "inactive"
}Create functions
You can only create one function per request.
Authorizations:
Request Body schema: application/json
required | Array of objects (Function) = 1 items Array of functions to create. |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "name": "My awesome function",
- "fileId": 5467347282343
}
]
}Response samples
- 201
- 400
{- "items": [
- {
- "id": 1,
- "createdTime": 123455234,
- "status": "Queued",
- "name": "myfunction",
- "externalId": "my.known.id",
- "fileId": 1,
- "owner": "user@cognite.com",
- "description": "My fantastic function with advanced ML",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "secrets": {
- "MySecret": "***"
}, - "functionPath": "myfunction/handler.py",
- "envVars": {
- "MyKey": "MyValue"
}, - "cpu": 1,
- "memory": 1.5,
- "runtime": "py312",
- "runtimeVersion": "Python 3.11.10",
- "error": {
- "code": 400,
- "message": "Could not build function."
}
}
]
}Delete functions
Delete functions. You can delete a maximum of 10 functions per request. Function source files stored in the Files API must be deleted separately.
Authorizations:
Request Body schema: application/json
required | Array of FunctionId (object) or FunctionExternalId (object) (FunctionIdEither) [ 1 .. 10 ] items |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "id": 1
}
], - "ignoreUnknownIds": false
}Response samples
- 200
- 400
{ }Filter functions
Use advanced filtering options to find functions.
Authorizations:
Request Body schema: application/json
object (FunctionFilter) | |
| limit | integer <int32> >= 1 Default: 100 Limits the number of results to be returned. |
Responses
Request samples
- Payload
- Python SDK
{- "filter": {
- "status": "Queued",
- "createdTime": {
- "min": 10,
- "max": 199
}
}
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 1,
- "createdTime": 123455234,
- "status": "Queued",
- "name": "myfunction",
- "externalId": "my.known.id",
- "fileId": 1,
- "owner": "user@cognite.com",
- "description": "My fantastic function with advanced ML",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "secrets": {
- "MySecret": "***"
}, - "functionPath": "myfunction/handler.py",
- "envVars": {
- "MyKey": "MyValue"
}, - "cpu": 1,
- "memory": 1.5,
- "runtime": "py312",
- "runtimeVersion": "Python 3.11.10",
- "error": {
- "code": 400,
- "message": "Could not build function."
}
}
]
}Functions limits
Service limits for the associated project.
Authorizations:
Responses
Request samples
- Python SDK
limits = client.functions.limits()
Response samples
- 200
- 400
{- "timeoutMinutes": 9,
- "cpuCores": {
- "min": 1,
- "max": 1,
- "default": 1
}, - "memoryGb": {
- "min": 1.5,
- "max": 1.5,
- "default": 1.5
}, - "runtimes": [
- "py310",
- "py311",
- "py312"
], - "responseSizeMb": 1
}List functions
List functions.
Authorizations:
query Parameters
| limit | integer >= 1 Default: 100 Limits the number of results to be returned. |
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "id": 1,
- "createdTime": 123455234,
- "status": "Queued",
- "name": "myfunction",
- "externalId": "my.known.id",
- "fileId": 1,
- "owner": "user@cognite.com",
- "description": "My fantastic function with advanced ML",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "secrets": {
- "MySecret": "***"
}, - "functionPath": "myfunction/handler.py",
- "envVars": {
- "MyKey": "MyValue"
}, - "cpu": 1,
- "memory": 1.5,
- "runtime": "py312",
- "runtimeVersion": "Python 3.11.10",
- "error": {
- "code": 400,
- "message": "Could not build function."
}
}
]
}Retrieve a function by its id
Retrieve a function by its id. If you want to retrieve functions by names, use Retrieve functions instead.
Authorizations:
path Parameters
| functionId required | integer The function id. |
Responses
Response samples
- 200
- 400
{- "id": 1,
- "createdTime": 123455234,
- "status": "Queued",
- "name": "myfunction",
- "externalId": "my.known.id",
- "fileId": 1,
- "owner": "user@cognite.com",
- "description": "My fantastic function with advanced ML",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "secrets": {
- "MySecret": "***"
}, - "functionPath": "myfunction/handler.py",
- "envVars": {
- "MyKey": "MyValue"
}, - "cpu": 1,
- "memory": 1.5,
- "runtime": "py312",
- "runtimeVersion": "Python 3.11.10",
- "error": {
- "code": 400,
- "message": "Could not build function."
}
}Retrieve functions
Retrieve functions by ids.
Authorizations:
Request Body schema: application/json
required | Array of FunctionId (object) or FunctionExternalId (object) (FunctionIdEither) [ 1 .. 10 ] items |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "id": 1
}
], - "ignoreUnknownIds": false
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 1,
- "createdTime": 123455234,
- "status": "Queued",
- "name": "myfunction",
- "externalId": "my.known.id",
- "fileId": 1,
- "owner": "user@cognite.com",
- "description": "My fantastic function with advanced ML",
- "metadata": {
- "property1": "string",
- "property2": "string"
}, - "secrets": {
- "MySecret": "***"
}, - "functionPath": "myfunction/handler.py",
- "envVars": {
- "MyKey": "MyValue"
}, - "cpu": 1,
- "memory": 1.5,
- "runtime": "py312",
- "runtimeVersion": "Python 3.11.10",
- "error": {
- "code": 400,
- "message": "Could not build function."
}
}
]
}Call a function asynchronously
Perform a function call. To provide input data to the function, add the data in an object called data in the request body. It will be available as the data argument into the function. Info about the function call at runtime can be obtained through the function_call_info argument if added in the function handle. WARNING: Secrets or other confidential information should not be passed via the data object. There is a dedicated secrets object in the request body to "Create functions" for this purpose.
Authorizations:
path Parameters
| functionId required | integer The function id. |
Request Body schema: application/json
| data | object (data) Input data to the function (only present if provided on the schedule). This data is passed deserialized into the function through one of the arguments called |
| nonce required | string (nonce) Nonce retrieved from sessions API when creating a session. This will be used to bind the session before executing the function. The corresponding access token will be passed to the function and used to instantiate the client of the handle() function. You can create a session via the Sessions API. When using the Python SDK, the session will be created behind the scenes when creating the schedule. |
Responses
Request samples
- Payload
- Python SDK
{- "data": {
- "timeSeriesId1": 13435351,
- "maxValue": 4
}, - "nonce": "string"
}Response samples
- 201
- 400
{- "id": 1,
- "status": "Running",
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "error": {
- "trace": "Cannot assign foo to bar.",
- "message": "Could not authenticate."
}, - "scheduleId": 1,
- "functionId": 1,
- "scheduledTime": 1730204346000
}Filter function calls
Use advanced filtering options to find function calls.
Authorizations:
path Parameters
| functionId required | integer The function id. |
Request Body schema: application/json
object (FunctionCallFilter) | |
| limit | integer <int32> >= 1 Default: 100 Limits the number of results to be returned. |
| cursor | string |
Responses
Request samples
- Payload
- Python SDK
{- "filter": {
- "status": "Running",
- "scheduleId": 123,
- "startTime": {
- "min": 1234,
- "max": 5678
}
}, - "limit": 10
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 1,
- "status": "Running",
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "error": {
- "trace": "Cannot assign foo to bar.",
- "message": "Could not authenticate."
}, - "scheduleId": 1,
- "functionId": 1,
- "scheduledTime": 1730204346000
}
], - "nextCursor": "string"
}List function calls
List function calls.
Authorizations:
path Parameters
| functionId required | integer The function id. |
query Parameters
| limit | integer >= 1 Default: 100 Limits the number of results to be returned. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Request samples
- Python SDK
logs = client.functions.calls.get_logs(call_id=2, function_id=1) call = client.functions.calls.retrieve(call_id=2, function_id=1) logs = call.get_logs()
Response samples
- 200
- 400
{- "items": [
- {
- "id": 1,
- "status": "Running",
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "error": {
- "trace": "Cannot assign foo to bar.",
- "message": "Could not authenticate."
}, - "scheduleId": 1,
- "functionId": 1,
- "scheduledTime": 1730204346000
}
], - "nextCursor": "string"
}Retrieve a function call by its id
Retrieve function calls.
Authorizations:
path Parameters
| callId required | integer The function call id. |
| functionId required | integer The function id. |
Responses
Response samples
- 200
- 400
{- "id": 1,
- "status": "Running",
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "error": {
- "trace": "Cannot assign foo to bar.",
- "message": "Could not authenticate."
}, - "scheduleId": 1,
- "functionId": 1,
- "scheduledTime": 1730204346000
}Retrieve calls
Retrieve function calls by call ids.
Authorizations:
path Parameters
| functionId required | integer The function id. |
Request Body schema: application/json
List of IDs of calls to retrieve. Must be up to a maximum of 10000 items and all of them must be unique.
required | Array of objects (FunctionCallId) [ 1 .. 10000 ] items |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "id": 1
}
], - "ignoreUnknownIds": false
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 1,
- "status": "Running",
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "error": {
- "trace": "Cannot assign foo to bar.",
- "message": "Could not authenticate."
}, - "scheduleId": 1,
- "functionId": 1,
- "scheduledTime": 1730204346000
}
]
}Retrieve logs for function call
Get logs from a function call.
Authorizations:
path Parameters
| callId required | integer The function call id. |
| functionId required | integer The function id. |
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "timestamp": 1585350274000,
- "message": "Did do fancy thing"
}, - {
- "timestamp": 1585350276000,
- "message": "Did do another fancy thing"
}
]
}Retrieve response for function call
Retrieve response from a function call.
Authorizations:
path Parameters
| callId required | integer The function call id. |
| functionId required | integer The function id. |
Responses
Request samples
- Python SDK
response = client.functions.calls.get_response(call_id=2, function_id=1) call = client.functions.calls.retrieve(call_id=2, function_id=1) response = call.get_response()
Response samples
- 200
- 400
{- "response": {
- "numAssets": 1234,
- "someCalculation": 3.14
}
}Function schedules allow you to run functions with a specific input at intervals defined by a cron expression. These function calls will be asynchronous and show up in the function call list. Visit http://www.cronmaker.com to generate a cron expression with a UI.
Create schedules
Create function schedules. Function schedules trigger asynchronous calls with specific input data, based on a cron expression that determines when these triggers should be fired. Use e.g. http://www.cronmaker.com to be guided on how to generate a cron expression. One of FunctionId or FunctionExternalId (deprecated) must be set (but not both). When creating a schedule with a session, i.e. with a nonce, FunctionId must be used. The nonce will be used to bind the session before function execution, and the session will be kept alive for the lifetime of the schedule. WARNING: Secrets or other confidential information should not be passed via the data object. There is a dedicated secrets object in the request body to "Create functions" for this purpose.
Authorizations:
Request Body schema: application/json
required | Array of objects (FunctionSchedule) = 1 items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "name": "My schedule",
- "description": "This is a nice schedule",
- "cronExpression": "* * * * *",
- "functionId": 1,
- "functionExternalId": "my.known.id",
- "data": {
- "timeSeriesId1": 13435351,
- "maxValue": 4
}, - "nonce": "string"
}
]
}Response samples
- 201
- 400
{- "items": [
- {
- "id": 1,
- "name": "My schedule",
- "createdTime": 1730204346000,
- "description": "This is a nice schedule",
- "cronExpression": "* * * * *",
- "when": "Every hour",
- "functionId": 1,
- "functionExternalId": "my.known.id",
- "sessionId": "string"
}
]
}Delete schedules
Delete function schedules.
Authorizations:
Request Body schema: application/json
required | Array of objects (FunctionScheduleId) [ 1 .. 10000 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "id": 1
}
]
}Response samples
- 200
- 400
{ }Filter function schedules
Use advanced filtering options to find function schedules. At most one of FunctionId or FunctionExternalId can be specified.
Authorizations:
Request Body schema: application/json
object (FunctionScheduleFilter) | |
| limit | integer <int32> >= 1 Default: 100 Limits the number of results to be returned. |
Responses
Request samples
- Payload
- Python SDK
{- "filter": {
- "name": "MySchedule",
- "cronExpression": "5 4 * * *"
}
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 1,
- "name": "My schedule",
- "createdTime": 1730204346000,
- "description": "This is a nice schedule",
- "cronExpression": "* * * * *",
- "when": "Every hour",
- "functionId": 1,
- "functionExternalId": "my.known.id",
- "sessionId": "string"
}
]
}List schedules
List function schedules in project.
Authorizations:
query Parameters
| limit | integer >= 1 Default: 100 Limits the number of results to be returned. |
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "id": 1,
- "name": "My schedule",
- "createdTime": 1730204346000,
- "description": "This is a nice schedule",
- "cronExpression": "* * * * *",
- "when": "Every hour",
- "functionId": 1,
- "functionExternalId": "my.known.id",
- "sessionId": "string"
}
]
}Retrieve a function schedule by its id
Retrieve a function schedule by its id.
Authorizations:
path Parameters
| scheduleId required | integer The function schedule id. |
Responses
Response samples
- 200
- 400
{- "id": 1,
- "name": "My schedule",
- "createdTime": 1730204346000,
- "description": "This is a nice schedule",
- "cronExpression": "* * * * *",
- "when": "Every hour",
- "functionId": 1,
- "functionExternalId": "my.known.id",
- "sessionId": "string"
}Retrieve function input data
Retrieve the input data to the associated function.
Authorizations:
path Parameters
| scheduleId required | integer The function schedule id. |
Responses
Request samples
- Python SDK
client.functions.schedules.get_input_data(id=123)
Response samples
- 200
- 400
{- "id": 1,
- "data": {
- "timeSeriesId1": 13435351,
- "maxValue": 4
}
}Retrieve schedules
Retrieve function schedules by schedule ids.
Authorizations:
Request Body schema: application/json
List of IDs of schedules to retrieve. Must be up to a maximum of 10000 items and all of them must be unique.
required | Array of objects [ 1 .. 10000 ] items |
| ignoreUnknownIds | boolean Default: false Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "id": 1
}
], - "ignoreUnknownIds": false
}Response samples
- 200
- 400
{- "items": [
- {
- "id": 1,
- "name": "My schedule",
- "createdTime": 1730204346000,
- "description": "This is a nice schedule",
- "cronExpression": "* * * * *",
- "when": "Every hour",
- "functionId": 1,
- "functionExternalId": "my.known.id",
- "sessionId": "string"
}
]
}A hosted extractor source represents an external source system on the internet. The source resource in CDF contains all the information the extractor needs to connect to the external source system. A source can have many jobs, each streaming different data from the source system.
Create Sources
Create up to 100 sources.
Authorizations:
Request Body schema: application/jsonrequired
Sources to create.
required | Array of any (Items) [ 1 .. 10 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "type": "mqtt3",
- "externalId": "my.known.id",
- "host": "string",
- "port": 1883,
- "authentication": {
- "type": "basic",
- "username": "string",
- "password": "string"
}, - "useTls": true,
- "caCertificate": {
- "type": "der",
- "certificate": "string"
}, - "authCertificate": {
- "key": "string",
- "keyPassword": "string",
- "type": "der",
- "certificate": "string"
}
}
]
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "type": "mqtt3",
- "externalId": "my.known.id",
- "host": "string",
- "port": 1883,
- "authentication": {
- "type": "basic",
- "username": "string"
}, - "useTls": true,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "caCertificate": {
- "thumbprint": "string",
- "expiresAt": 0
}, - "authCertificate": {
- "thumbprint": "string",
- "expiresAt": 0
}
}
]
}Delete Sources
Delete a list of sources by their external ID. This operation will fail if any destination in the request is associated with a job, unless the force query parameter is set to true.
Authorizations:
Request Body schema: application/jsonrequired
List of external IDs of sources to delete.
required | Array of objects (Items) [ 1 .. 100 ] items |
| ignoreUnknownIds | boolean (IgnoreUnknownIds) Ignore IDs and external IDs that are not found. |
| force | boolean (Force) Delete any jobs associated with each item. |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "my.known.id"
}
], - "ignoreUnknownIds": true,
- "force": true
}Response samples
- 200
- 400
- 422
{ }List Sources
List all sources in a given project. If more than limit sources exist, a cursor for pagination will be returned with the response.
Authorizations:
query Parameters
| limit | integer [ 1 .. 100 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 100 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Request samples
- Python SDK
source_list = client.hosted_extractors.sources.list(limit=5) for source in client.hosted_extractors.sources: source # do something with the source for source_list in client.hosted_extractors.sources(chunk_size=25): source_list # do something with the sources
Response samples
- 200
- 400
- 422
{- "items": [
- {
- "type": "mqtt3",
- "externalId": "my.known.id",
- "host": "string",
- "port": 1883,
- "authentication": {
- "type": "basic",
- "username": "string"
}, - "useTls": true,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "caCertificate": {
- "thumbprint": "string",
- "expiresAt": 0
}, - "authCertificate": {
- "thumbprint": "string",
- "expiresAt": 0
}
}
], - "nextCursor": "string"
}Retrieve Sources
Retrieve a list of up to 100 sources by their external ID, optionally ignoring unknown IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of external IDs of sources to retrieve.
required | Array of objects (Items) [ 1 .. 100 ] items |
| ignoreUnknownIds | boolean (IgnoreUnknownIds) Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "my.known.id"
}
], - "ignoreUnknownIds": true
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "type": "mqtt3",
- "externalId": "my.known.id",
- "host": "string",
- "port": 1883,
- "authentication": {
- "type": "basic",
- "username": "string"
}, - "useTls": true,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "caCertificate": {
- "thumbprint": "string",
- "expiresAt": 0
}, - "authCertificate": {
- "thumbprint": "string",
- "expiresAt": 0
}
}
]
}Update Sources
Update up to 100 sources.
Authorizations:
Request Body schema: application/json
Sources to update.
required | Array of any (Items) [ 1 .. 10 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "type": "mqtt3",
- "externalId": "my.known.id",
- "update": {
- "host": {
- "set": "string"
}, - "port": {
- "set": 1
}, - "authentication": {
- "set": {
- "type": "basic",
- "username": "string",
- "password": "string"
}
}, - "useTls": {
- "set": true
}, - "caCertificate": {
- "set": {
- "type": "der",
- "certificate": "string"
}
}, - "authCertificate": {
- "set": {
- "key": "string",
- "keyPassword": "string",
- "type": "der",
- "certificate": "string"
}
}
}
}
]
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "type": "mqtt3",
- "externalId": "my.known.id",
- "host": "string",
- "port": 1883,
- "authentication": {
- "type": "basic",
- "username": "string"
}, - "useTls": true,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "caCertificate": {
- "thumbprint": "string",
- "expiresAt": 0
}, - "authCertificate": {
- "thumbprint": "string",
- "expiresAt": 0
}
}
]
}A hosted extractor job represents the running extractor. Jobs produce logs and metrics that give the state of the job. For details on available states and metrics see documentation here.
Create Jobs
Create up to 100 jobs.
Authorizations:
Request Body schema: application/jsonrequired
Jobs to create.
required | Array of objects (Items) [ 1 .. 10 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "my.known.id",
- "destinationId": "string",
- "sourceId": "string",
- "format": {
- "type": "rockwell",
- "encoding": "utf8",
- "compression": "gzip",
- "prefix": {
- "fromTopic": true,
- "prefix": "string"
}, - "dataModels": {
- "space": "string"
}
}, - "config": {
- "topicFilter": "string"
}
}
]
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "destinationId": "string",
- "sourceId": "string",
- "format": {
- "type": "rockwell",
- "encoding": "utf8",
- "compression": "gzip",
- "prefix": {
- "fromTopic": true,
- "prefix": "string"
}, - "dataModels": {
- "space": "string"
}
}, - "targetStatus": "running",
- "status": "startup_error",
- "config": {
- "topicFilter": "string"
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Delete Jobs
Delete a list of jobs by their external ID.
Authorizations:
Request Body schema: application/jsonrequired
List of external IDs of jobs to delete.
required | Array of objects (Items) [ 1 .. 100 ] items |
| ignoreUnknownIds | boolean (IgnoreUnknownIds) Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "my.known.id"
}
], - "ignoreUnknownIds": true
}Response samples
- 200
- 400
- 422
{ }Get Job Logs
List logs, optionally filtering on job, source, or destination. Logs are retrieved in reverse chronological order.
Authorizations:
query Parameters
| job | string (Job) Require returned logs to belong to the job given by this external ID. |
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 1000 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| source | string (Source) Require returned logs to belong to the any job with source given by this external ID. |
| destination | string (Destination) Require returned logs to belong to the any job with destination given by this external ID. |
Responses
Request samples
- Python SDK
res = client.hosted_extractors.jobs.list_logs(job="myJob")
Response samples
- 200
- 400
- 422
{- "items": [
- {
- "jobExternalId": "string",
- "type": "paused",
- "message": "string",
- "createdTime": 1730204346000
}
]
}Get Job Metrics
List metrics, optionally filtering on job, source, or destination. Logs are retrieved in reverse chronological order.
Authorizations:
query Parameters
| job | string (Job) Require returned metrics to belong to the job given by this external ID. |
| limit | integer [ 1 .. 1000 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 1000 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| source | string (Source) Require returned metrics to belong to the any job with source given by this external ID. |
| destination | string (Destination) Require returned metrics to belong to the any job with destination given by this external ID. |
Responses
Request samples
- Python SDK
res = client.hosted_extractors.jobs.list_metrics(job="myJob")
Response samples
- 200
- 400
- 422
{- "items": [
- {
- "jobExternalId": "string",
- "timestamp": 0,
- "sourceMessages": 0,
- "cdfInputValues": 0,
- "cdfRequests": 0,
- "transformFailures": 0,
- "cdfWriteFailures": 0,
- "cdfSkippedValues": 0,
- "cdfFailedValues": 0,
- "cdfUploadedValues": 0
}
]
}List Jobs
List all jobs in a given project. If more than limit jobs exist, a cursor for pagination will be returned with the response.
Authorizations:
query Parameters
| limit | integer [ 1 .. 100 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 100 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| source | string (Source) External ID of source the returned jobs must be tied to. |
| destination | string (Destination) External ID of destination the returned jobs must be tied to. |
| mapping | string (Mapping) External ID of mapping the returned jobs must be tied to. |
Responses
Request samples
- Python SDK
job_list = client.hosted_extractors.jobs.list(limit=5) for job in client.hosted_extractors.jobs: job # do something with the job for job_list in client.hosted_extractors.jobs(chunk_size=25): job_list # do something with the jobs
Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "destinationId": "string",
- "sourceId": "string",
- "format": {
- "type": "rockwell",
- "encoding": "utf8",
- "compression": "gzip",
- "prefix": {
- "fromTopic": true,
- "prefix": "string"
}, - "dataModels": {
- "space": "string"
}
}, - "targetStatus": "running",
- "status": "startup_error",
- "config": {
- "topicFilter": "string"
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
], - "nextCursor": "string"
}Retrieve Jobs
Retrieve a list of up to 100 jobs by their external ID, optionally ignoring unknown IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of external IDs of jobs to retrieve.
required | Array of objects (Items) [ 1 .. 100 ] items |
| ignoreUnknownIds | boolean (IgnoreUnknownIds) Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "my.known.id"
}
], - "ignoreUnknownIds": true
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "destinationId": "string",
- "sourceId": "string",
- "format": {
- "type": "rockwell",
- "encoding": "utf8",
- "compression": "gzip",
- "prefix": {
- "fromTopic": true,
- "prefix": "string"
}, - "dataModels": {
- "space": "string"
}
}, - "targetStatus": "running",
- "status": "startup_error",
- "config": {
- "topicFilter": "string"
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Update Jobs
Update a list of up to 100 jobs.
Authorizations:
Request Body schema: application/jsonrequired
Jobs to update.
required | Array of objects (Items) [ 1 .. 10 ] characters |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "my.known.id",
- "update": {
- "destinationId": {
- "set": "string"
}, - "format": {
- "set": {
- "type": "rockwell",
- "encoding": "utf8",
- "compression": "gzip",
- "prefix": {
- "fromTopic": true,
- "prefix": "string"
}, - "dataModels": {
- "space": "string"
}
}
}, - "sourceId": {
- "set": "string"
}, - "targetStatus": {
- "set": "running"
}, - "config": {
- "set": {
- "topicFilter": "string"
}
}
}
}
]
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "destinationId": "string",
- "sourceId": "string",
- "format": {
- "type": "rockwell",
- "encoding": "utf8",
- "compression": "gzip",
- "prefix": {
- "fromTopic": true,
- "prefix": "string"
}, - "dataModels": {
- "space": "string"
}
}, - "targetStatus": "running",
- "status": "startup_error",
- "config": {
- "topicFilter": "string"
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}A hosted extractor writes to a destination. The destination contains credentials for CDF, and additional information about where the data should land, such as data set ID. Multiple jobs can share a single destination, in which case requests will be combined, reducing the number of requests made to CDF APIs. Metrics are still reported for each individual job.
Create Destinations
Create up to 100 destinations.
Authorizations:
Request Body schema: application/jsonrequired
Destinations to create.
required | Array of objects (Items) [ 1 .. 10 ] characters |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "my.known.id",
- "credentials": {
- "nonce": "string"
}, - "targetDataSetId": 1
}
]
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "sessionId": 1,
- "targetDataSetId": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Delete Destinations
Delete a list of destinations by their external ID. This operation will fail if any destination in the request is associated with a job, unless the force query parameter is set to true.
Authorizations:
Request Body schema: application/jsonrequired
List of external IDs of destinations to delete.
required | Array of objects (Items) [ 1 .. 100 ] items |
| ignoreUnknownIds | boolean (IgnoreUnknownIds) Ignore IDs and external IDs that are not found. |
| force | boolean (Force) Delete any jobs associated with each item. |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "my.known.id"
}
], - "ignoreUnknownIds": true,
- "force": true
}Response samples
- 200
- 400
- 422
{ }List Destinations
List all destinations in a given project. If more than limit destinations exist, a cursor for pagination will be returned with the response.
Authorizations:
query Parameters
| limit | integer [ 1 .. 100 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 100 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Request samples
- Python SDK
destination_list = client.hosted_extractors.destinations.list(limit=5) for destination in client.hosted_extractors.destinations: destination # do something with the destination for destination_list in client.hosted_extractors.destinations(chunk_size=25): destination_list # do something with the destinationss
Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "sessionId": 1,
- "targetDataSetId": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
], - "nextCursor": "string"
}Retrieve Destinations
Retrieve a list of up to 100 destinations by their external ID, optionally ignoring unknown IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of external IDs of destinations to retrieve.
required | Array of objects (Items) [ 1 .. 100 ] items |
| ignoreUnknownIds | boolean (IgnoreUnknownIds) Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "my.known.id"
}
], - "ignoreUnknownIds": true
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "sessionId": 1,
- "targetDataSetId": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Update Destinations
Update up to 100 destinations.
Authorizations:
Request Body schema: application/jsonrequired
Destinations to update.
required | Array of objects (Items) [ 1 .. 10 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "my.known.id",
- "update": {
- "credentials": {
- "setNull": true
}, - "targetDataSetId": {
- "setNull": true
}
}
}
]
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "sessionId": 1,
- "targetDataSetId": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}A mapping is a custom transformation, translating the source format to a format that can be ingested into CDF. Mappings are written in the Cognite transformation language. For more details see documentation here.
Create Mappings
Create up to 100 mappings.
Authorizations:
Request Body schema: application/jsonrequired
Mappings to create.
required | Array of objects (Items) [ 1 .. 10 ] characters |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "my.known.id",
- "mapping": {
- "expression": "string"
}, - "input": {
- "type": "protobuf",
- "messageName": "string",
- "files": [
- {
- "fileName": "string",
- "content": "string"
}
]
}, - "published": true
}
]
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "mapping": {
- "expression": "string"
}, - "input": {
- "type": "protobuf",
- "messageName": "string",
- "files": [
- {
- "fileName": "string"
}
]
}, - "published": true,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Delete Mappings
Delete a list of mappings by their external ID. This operation will fail if any mapping in the request is associated with a job, unless the force query parameter is set to true.
Authorizations:
Request Body schema: application/jsonrequired
List of external IDs of mappings to delete.
required | Array of objects (Items) [ 1 .. 100 ] items |
| ignoreUnknownIds | boolean (IgnoreUnknownIds) Ignore IDs and external IDs that are not found. |
| force | boolean (Force) Delete any jobs associated with each item. |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "my.known.id"
}
], - "ignoreUnknownIds": true,
- "force": true
}Response samples
- 200
- 400
- 422
{ }List Mappings
List all mappings in a given project. If more than limit mappings exist, a cursor for pagination will be returned with the response.
Authorizations:
query Parameters
| limit | integer [ 1 .. 100 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 100 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Request samples
- Python SDK
mapping_list = client.hosted_extractors.mappings.list(limit=5) for mapping in client.hosted_extractors.mappings: mapping # do something with the mapping for mapping_list in client.hosted_extractors.mappings(chunk_size=25): mapping_list # do something with the mappings
Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "mapping": {
- "expression": "string"
}, - "input": {
- "type": "protobuf",
- "messageName": "string",
- "files": [
- {
- "fileName": "string"
}
]
}, - "published": true,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
], - "nextCursor": "string"
}Retrieve Mappings
Retrieve a list of up to 100 mappings by their external ID, optionally ignoring unknown IDs.
Authorizations:
header Parameters
| cdf-version | string (Cdf-Version) |
Request Body schema: application/jsonrequired
List of external IDs of mappings to retrieve.
required | Array of objects (Items) [ 1 .. 100 ] items |
| ignoreUnknownIds | boolean (IgnoreUnknownIds) Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "my.known.id"
}
], - "ignoreUnknownIds": true
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "mapping": {
- "expression": "string"
}, - "input": {
- "type": "protobuf",
- "messageName": "string",
- "files": [
- {
- "fileName": "string"
}
]
}, - "published": true,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Update Mappings
Update up to 100 mappings.
Authorizations:
Request Body schema: application/jsonrequired
Mappings to update.
required | Array of objects (Items) [ 1 .. 10 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "my.known.id",
- "update": {
- "mapping": {
- "set": {
- "expression": "string"
}
}, - "input": {
- "set": {
- "type": "protobuf",
- "messageName": "string",
- "files": [
- {
- "fileName": "string",
- "content": "string"
}
]
}
}, - "published": {
- "set": true
}
}
}
]
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "mapping": {
- "expression": "string"
}, - "input": {
- "type": "protobuf",
- "messageName": "string",
- "files": [
- {
- "fileName": "string"
}
]
}, - "published": true,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}A preview is a temporary job that runs until it times out, fails, or receives a single message, then stores the result. This is useful for development, as it allows you to easily inspect the output of a source.
Previews require a source, but not a mapping or a destination.
This API is in alpha. The endpoints listed here are available only when the cdf-version header with the value alpha is provided.
Create Preview
Create a preview job. Previews will run for up to 10 minutes, and return once they receive any data. Use the /result endpoint to check the status of the preview.
Authorizations:
Request Body schema: application/jsonrequired
Preview to create.
| externalId required | string (CogniteExternalId) <= 255 characters The external ID provided by the client. Must be unique for the resource type. |
| sourceId required | string (Source ID) <= 255 characters ID of the source this preview job should read from. |
required | MQTT (object) or Kafka (object) or Rest (object) (JobConfig) |
object (Format) Input format parameters. | |
ProtoBuf (object) or CSV (object) or XML (object) or JSON (object) (CreateInputConfig) |
Responses
Request samples
- Payload
{- "externalId": "my.known.id",
- "sourceId": "string",
- "config": {
- "topicFilter": "string"
}, - "format": {
- "encoding": "utf8",
- "compression": "gzip"
}, - "input": {
- "type": "protobuf",
- "messageName": "string",
- "files": [
- {
- "fileName": "string",
- "content": "string"
}
]
}
}Response samples
- 200
- 400
- 422
{- "externalId": "my.known.id",
- "sourceId": "string",
- "config": {
- "topicFilter": "string"
}, - "format": {
- "encoding": "utf8",
- "compression": "gzip"
}, - "input": {
- "type": "protobuf",
- "messageName": "string",
- "files": [
- {
- "fileName": "string"
}
]
}, - "createdTime": 1730204346000
}Download preview result
Download the raw, binary result of a preview job, before it is passed throguh any transformations. Note that this endpoint will return 404 if there is no raw data.
Authorizations:
Request Body schema: application/jsonrequired
External ID of preview job to get result for.
| externalId required | string (CogniteExternalId) <= 255 characters The external ID provided by the client. Must be unique for the resource type. |
Responses
Request samples
- Payload
{- "externalId": "my.known.id"
}Response samples
- 400
- 422
{- "error": {
- "code": 400,
- "message": "`null` values aren't allowed."
}
}Get preview result
Get the result of a preview job. Note that previews may be automatically deleted as soon as 1 hour after they are created.
Authorizations:
Request Body schema: application/jsonrequired
External ID of preview job to get result for.
| externalId required | string (CogniteExternalId) <= 255 characters The external ID provided by the client. Must be unique for the resource type. |
Responses
Request samples
- Payload
{- "externalId": "my.known.id"
}Response samples
- 200
- 400
- 422
{- "type": "error",
- "externalId": "my.known.id",
- "kind": "startup_error",
- "message": "string",
- "createdTime": 1730204346000
}Advanced list of limit values.
Retrieves limit values using a filter.
Only the prefix operator is supported.
Authorizations:
header Parameters
| cdf-version required | string Value: "20230101-beta" |
Request Body schema: application/json
object Filter to apply to the list operation. To retrieve all limits for a specific service,
use the "prefix" operator where the property is the limit's key, e.g.,
| |
| limit | integer <= 1000 Default: 1000 Maximum number of items to return. |
| cursor | string Cursor to use for paging through results. |
Responses
Request samples
- Payload
{- "filter": {
- "prefix": {
- "property": [
- "limitId"
], - "value": "atlas."
}
}, - "limit": 1000,
- "cursor": "string"
}Response samples
- 200
- 401
{- "items": [
- {
- "limitId": "atlas.monthly_ai_tokens",
- "value": 1000
}, - {
- "limitId": "atlas.monthly_ai_prompts",
- "value": 500
}
], - "nextCursor": "eyJjdXJzb3IiOiAiMTIzNDU2In0="
}List all limit values
Retrieves all limit values for a specific project.
Authorizations:
query Parameters
| cursor | string Cursor to use for paging through results. |
| limit | integer <int32> <= 1000 Default: 1000 Return up to this many results. |
header Parameters
| cdf-version required | string Value: "20230101-beta" |
Responses
Response samples
- 200
- 401
{- "items": [
- {
- "limitId": "atlas.monthly_ai_tokens",
- "value": 1000
}, - {
- "limitId": "files.storage_bytes",
- "value": 500
}, - {
- "limitId": "functions.concurrent_executions",
- "value": 50
}
], - "nextCursor": "string"
}Retrieve a limit value by its id
Retrieves a limit value by its limitId.
Authorizations:
path Parameters
| limitId required | string Limits are identified by an id containg the service name and a service-scoped limit name. For instance Service and limit names are always in |
header Parameters
| cdf-version required | string Value: "20230101-beta" |
Responses
Response samples
- 200
- 401
{- "limitId": "atlas.monthly_ai_tokens",
- "value": 1000
}A postgres gateway user (also a typical postgres user) owns the foreign tables (built in or custom).
The created postgres user only has access to use foreign tables and cannot directly create tables users. To create foreign tables use the Postgres Gateway Tables APIs
Create users
Create postgres users.
Authorizations:
Request Body schema: application/jsonrequired
List of postgres users to create
required | Array of objects (Items) = 1 items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "credentials": {
- "nonce": "string"
}
}
]
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "host": "fdw.<CLUSTER>.cogniteapp.com",
- "username": "string",
- "password": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "sessionId": 1
}
]
}Delete users
Delete postgres users
Authorizations:
Request Body schema: application/jsonrequired
Postgres users to delete
required | Array of objects (UsernameWrapper) = 1 items |
| ignoreUnknownIds | boolean Ignore usernames that are not found |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "username": "string"
}
], - "ignoreUnknownIds": true
}Response samples
- 200
- 400
- 422
{ }Filter users
List all postgres users for a given project. If more than limit users exist, a cursor for pagination will be returned with the response.
Authorizations:
Request Body schema: application/jsonrequired
| limit | integer <int32> [ 1 .. 10 ] |
| cursor | string (Cursor) Cursor for pagination |
Responses
Request samples
- Payload
- Python SDK
{- "limit": 1,
- "cursor": "string"
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "username": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "sessionId": 1
}
], - "nextCursor": "string"
}List users
List all users in a given project. If more than limit users exist, a cursor for pagination will be returned with the response.
Authorizations:
query Parameters
| limit | integer [ 1 .. 100 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 100 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Response samples
- 200
- 400
- 422
{- "items": [
- {
- "username": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "sessionId": 1
}
], - "nextCursor": "string"
}Retrieve users
Retreive a list of postgres users by their usernames, optionally ignoring unknown usernames
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (UsernameWrapper) [ 1 .. 10 ] items |
| ignoreUnknownIds | boolean Ignore usernames that are not found |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "username": "string"
}
], - "ignoreUnknownIds": true
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "username": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "sessionId": 1
}
]
}Update users
Update postgres users
Authorizations:
Request Body schema: application/jsonrequired
Users to update
required | Array of objects (Items) = 1 items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "username": "string",
- "update": {
- "credentials": {
- "set": {
- "nonce": "string"
}
}
}
}
]
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "username": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "sessionId": 1
}
], - "nextCursor": "string"
}Create tables
Create up to 10 tables.
Authorizations:
path Parameters
| username required | string (Username) The name of the username (a.k.a. database) to be managed from the API |
Request Body schema: application/jsonrequired
List of tables to create
required | Array of objects (Items) [ 1 .. 10 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "type": "raw_rows",
- "tablename": "string",
- "options": {
- "database": "string",
- "table": "string",
- "primaryKey": "string"
}, - "columns": {
- "property1": {
- "type": "TEXT"
}, - "property2": {
- "type": "TEXT"
}
}
}
]
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "columns": {
- "property1": {
- "type": "TEXT"
}, - "property2": {
- "type": "TEXT"
}
}, - "options": {
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "createdTime": 1730204346000,
- "type": "raw_rows",
- "tablename": "string"
}
]
}Delete tables
Delete up to 10 tables
Authorizations:
path Parameters
| username required | string (Username) The name of the username (a.k.a. database) to be managed from the API |
Request Body schema: application/jsonrequired
Tables to delete
required | Array of objects (Items) [ 1 .. 10 ] items |
| ignoreUnknownIds | boolean (IgnoreUnknown) Ignore table names not found |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "tablename": "string"
}
], - "ignoreUnknownIds": true
}Response samples
- 200
- 400
- 422
{ }List tables
List all tables in a given project. If more than limit tables exist, a cursor for pagination will be returned with the response.
Authorizations:
path Parameters
| username required | string (Username) The name of the username (a.k.a. database) to be managed from the API |
query Parameters
| limit | integer [ 1 .. 100 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 100 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
| includeBuiltIns | boolean Default: false Determines if API should return built-in tables or not |
Responses
Request samples
- Python SDK
custom_table_list = client.postgres_gateway.tables.list("myUserName", limit=5) for table in client.postgres_gateway.tables: table # do something with the custom table for table_list in client.postgres_gateway.tables(chunk_size=25): table_list # do something with the custom tables
Response samples
- 200
- 400
- 422
{- "items": [
- {
- "columns": {
- "property1": {
- "type": "TEXT"
}, - "property2": {
- "type": "TEXT"
}
}, - "options": {
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "type": "raw_rows",
- "tablename": "string"
}
], - "nextCursor": "string"
}Retrieve tables
Retreive a list of postgres tables for a user by their table names, optionally ignoring unknown table names
Authorizations:
path Parameters
| username required | string (Username) The name of the username (a.k.a. database) to be managed from the API |
Request Body schema: application/jsonrequired
required | Array of objects (Items) [ 1 .. 10 ] items |
| ignoreUnknownIds | boolean (IgnoreUnknown) Ignore table names not found |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "tablename": "string"
}
], - "ignoreUnknownIds": true
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "columns": {
- "property1": {
- "type": "TEXT"
}, - "property2": {
- "type": "TEXT"
}
}, - "options": {
- "space": "string",
- "externalId": "string",
- "version": "string"
}, - "type": "raw_rows",
- "tablename": "string"
}
]
}An SAP instance represents a configuration to an external SAP S/4HANA destination system. The instance resource contains all the information this API service needs to connect to an SAP S/4HANA destination.
Supported SAP S/4HANA versions:
- SAP S/4HANA OnPremise 2021 FPS01, and later
- SAP S/4HANA Cloud
Create SAP Instances
Create up to 100 SAP instances.
Authorizations:
Request Body schema: application/jsonrequired
Instance to create.
required | Array of objects (Items) [ 1 .. 100 ] characters |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id",
- "gatewayUrl": "string",
- "client": 0,
- "username": "string",
- "password": "string"
}
]
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "gatewayUrl": "string",
- "client": 0,
- "username": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Delete SAP Instances
Delete a list of SAP instance configurations by their external ID. This operation will fail if any destination in the request is associated with an SAP endpoint configuration, unless the force query parameter is set to true.
Authorizations:
Request Body schema: application/jsonrequired
List of SAP instance configuration external IDs to delete.
required | Array of objects (Items) [ 1 .. 100 ] items |
| ignoreUnknownIds | boolean (IgnoreUnknownIds) Ignore IDs and external IDs that are not found. |
| force | boolean (Force) Delete any jobs associated with each item. |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
], - "ignoreUnknownIds": true,
- "force": true
}Response samples
- 200
- 400
- 422
{ }List SAP Instances
List all SAP instances in a given CDF project. If more instances exist than what the limit specifies, a pagination cursor is returned in the response body.
Authorizations:
query Parameters
| limit | integer [ 1 .. 100 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 100 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "gatewayUrl": "string",
- "client": 0,
- "username": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
], - "nextCursor": "string"
}Retrieve SAP Instances
Retrieve a list of up to 100 SAP instances by their external ID, optionally ignoring unknown IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of external IDs of SAP instances to retrieve.
required | Array of objects (Items) [ 1 .. 100 ] items |
| ignoreUnknownIds | boolean (IgnoreUnknownIds) Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
], - "ignoreUnknownIds": true
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "gatewayUrl": "string",
- "client": 0,
- "username": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}An SAP endpoint represents a configuration to an SAP S/4HANA OData endpoint (and its related OData entity) the API will send the writeback requests. It defines which SAP Instance destination and which schema mapping should be used when processing a writeback request.
Supported SAP entities:
Create SAP Endpoints
Create up to 100 SAP endpoints.
Authorizations:
Request Body schema: application/jsonrequired
Endpoint to create.
required | Array of objects (Items) [ 1 .. 100 ] characters |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id",
- "endpointType": "notification",
- "instanceId": "string",
- "mappingId": "string"
}
]
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "endpointType": "notification",
- "instanceId": "string",
- "mappingId": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Delete SAP Endpoints
Delete a list of SAP endpoint configurations by their external ID. This operation will fail if any endpoint in the request is associated to a SAP instance configuration.
Authorizations:
Request Body schema: application/jsonrequired
A list of External IDs for SAP endpoint configurations to delete.
required | Array of objects (Items) [ 1 .. 100 ] items |
| ignoreUnknownIds | boolean (IgnoreUnknownIds) Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
], - "ignoreUnknownIds": true
}Response samples
- 200
- 400
- 422
{ }List SAP Endpoints
List all SAP endpoints in a given CDF project. If more instances exist than what the limit specifies, a pagination cursor is returned in the response body.
Authorizations:
query Parameters
| limit | integer [ 1 .. 100 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 100 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "endpointType": "notification",
- "instanceId": "string",
- "mappingId": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
], - "nextCursor": "string"
}Retrieve SAP Endpoints
Retrieve a list of up to 100 SAP endpoints by their external ID, optionally ignoring unknown IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of external IDs of SAP endpoint configurations to retrieve.
required | Array of objects (Items) [ 1 .. 100 ] items |
| ignoreUnknownIds | boolean (IgnoreUnknownIds) Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
], - "ignoreUnknownIds": true
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "endpointType": "notification",
- "instanceId": "string",
- "mappingId": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Verify SAP Endpoint
Verify the connectivity between the writeback API, and the SAP endpoint destination.
Authorizations:
Request Body schema: application/jsonrequired
SAP Endpoint external ID which the connection test should be verified.
| externalId required | string (CogniteExternalId) <= 255 characters The external ID provided by the client. Must be unique for the resource type. |
Responses
Request samples
- Payload
{- "externalId": "my.known.id"
}Response samples
- 200
- 400
- 422
{- "error": {
- "status": "success",
- "detail": "string"
}
}A mapping uses field and value mapping(s) to perform an in-flight transformation from source CDF entities to SAP S/4HANA entities. Mappings are written in the Cognite transformation language. For more details see the documentation.
Create Mappings
Create a maximum of 100 mappings.
Authorizations:
Request Body schema: application/jsonrequired
Mappings to create.
required | Array of objects (Items) [ 1 .. 100 ] characters |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id",
- "expression": "\n{\n \"SAPFieldA\": substring(input.CDFFieldA,0,40), \n \"SAPFieldB\": input.CDFFieldB, \n}\n"
}
]
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "expression": "\n{\n \"SAPFieldA\": substring(input.CDFFieldA,0,40), \n \"SAPFieldB\": input.CDFFieldB, \n}\n",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Delete Mappings
Delete a list of mappings by their external ID.
Authorizations:
Request Body schema: application/jsonrequired
List of external IDs of mappings to delete.
required | Array of objects (Items) [ 1 .. 100 ] items |
| ignoreUnknownIds | boolean (IgnoreUnknownIds) Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
], - "ignoreUnknownIds": true
}Response samples
- 200
- 400
- 422
{ }List Mappings
List all mappings in a given CDF project. If more instances exist than what the limit specifies, a pagination cursor is returned in the response body.
Authorizations:
query Parameters
| limit | integer [ 1 .. 100 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 100 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "expression": "\n{\n \"SAPFieldA\": substring(input.CDFFieldA,0,40), \n \"SAPFieldB\": input.CDFFieldB, \n}\n",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
], - "nextCursor": "string"
}Retrieve Mappings
Retrieve a list of up to 100 mappings by their external ID, optionally ignoring unknown IDs.
Authorizations:
header Parameters
| cdf-version | string (Cdf-Version) |
Request Body schema: application/jsonrequired
List of external IDs of mappings to retrieve.
required | Array of objects (Items) [ 1 .. 100 ] items |
| ignoreUnknownIds | boolean (IgnoreUnknownIds) Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
], - "ignoreUnknownIds": true
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "externalId": "my.known.id",
- "mapping": {
- "expression": "string"
}, - "input": {
- "type": "protobuf",
- "messageName": "string",
- "files": [
- {
- "fileName": "string"
}
]
}, - "published": true,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}A writeback request to the SAP S/4HANA destination. The request body contains the target SAP endpoint destination, and the payload to send.
Create Writeback Requests
Create a writeback request
Authorizations:
Request Body schema: application/jsonrequired
Request to create.
required | Array of objects (Items) = 1 items |
Responses
Request samples
- Payload
{- "items": [
- {
- "endpointId": "string",
- "request": [
- {
- "key": "string",
- "fileId": "string",
- "payload": { }
}
]
}
]
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "requestId": "string",
- "request": [
- {
- "payload": { }
}
], - "status": "pending",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}List Writeback Requests
List all writeback requests in a given CDF project. If more instances exist than what the limit specifies, a pagination cursor is returned in the response body.
Authorizations:
query Parameters
| limit | integer [ 1 .. 100 ] Default: 100 Limits the number of results to be returned. The maximum results returned by the server is 100 even if you specify a higher limit. |
| cursor | string Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor for paging through results. In general, if a response contains a Note that the cursor may or may not be encrypted, but either way, it is not intended to be decoded. Its internal structure is not a part of the public API, and may change without notice. You should treat it as an opaque string and not attempt to craft your own cursors. |
Responses
Response samples
- 202
- 400
- 422
{- "items": [
- {
- "requestId": "string",
- "request": [
- {
- "key": "string",
- "sapObjectId": "string"
}
], - "status": "pending",
- "createdTime": 1730204346000,
- "errorMessage": "string",
- "lastUpdatedTime": 1730204346000
}
], - "nextCursor": "string"
}Retrieve Writeback Requests
Retrieve a list of up to 100 writeback requests by their external ID, optionally ignoring unknown IDs.
Authorizations:
Request Body schema: application/jsonrequired
List of external IDs of writeback requests to retrieve.
required | Array of objects (Items) [ 1 .. 100 ] items |
| ignoreUnknownIds | boolean (IgnoreUnknownIds) Ignore IDs and external IDs that are not found |
Responses
Request samples
- Payload
{- "items": [
- {
- "requestId": "string"
}
], - "ignoreUnknownIds": true
}Response samples
- 200
- 400
- 422
{- "items": [
- {
- "requestId": "string",
- "request": [
- {
- "key": "string",
- "payload": { },
- "sapObjectId": "string"
}
], - "status": "pending",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "errorMessage": "string"
}
]
}Define and orchestrate data workflows consisting of CDF Transformations, Cognite Functions, and other processes. This service enables you to build data pipelines and business solutions leveraging the capabilities of CDF and external tools.
Create or update a workflow
Create or update a workflow. Limited to a single workflow per request.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects = 1 items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "string",
- "description": "string",
- "dataSetId": 1
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "string",
- "description": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "dataSetId": 1
}
]
}Delete workflows
Delete workflows, including all associated workflow versions.
Authorizations:
query Parameters
| ignoreUnknownIds | boolean Default: true If |
Request Body schema: application/jsonrequired
Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "string"
}
]
}Response samples
- 200
- 404
{ }List workflows
List workflows in the project.
Authorizations:
query Parameters
| limit | integer (limit) [ 1 .. 1000 ] Default: 100 The maximum number of results to return. |
| cursor | string (cursor) Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor to use for paging through results. This cursor is returned in the response of a previous request as |
Responses
Request samples
- Python SDK
res = client.workflows.list(limit=None)
Response samples
- 200
{- "items": [
- {
- "externalId": "string",
- "description": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "dataSetId": 1
}
], - "nextCursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo"
}Retrieve a workflow
Retrieve a workflow by its external id.
Authorizations:
path Parameters
| workflowExternalId required | string (WorkflowExternalId) <= 255 characters Identifier for a workflow. Must be unique for the project. No trailing or leading whitespace and no null characters allowed. |
Responses
Request samples
- Python SDK
workflow = client.workflows.retrieve("my_workflow") workflow_list = client.workflows.retrieve(["foo", "bar"])
Response samples
- 200
- 404
{- "externalId": "string",
- "description": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "dataSetId": 1
}Create or update a workflow version
Create or update a workflow version. Limited to a single workflow version per request.
Authorizations:
Request Body schema: application/jsonrequired
Array of objects = 1 items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "workflowExternalId": "string",
- "version": "string",
- "workflowDefinition": {
- "description": "string",
- "tasks": [
- {
- "externalId": "string",
- "type": "function",
- "name": "string",
- "description": "string",
- "parameters": {
- "function": {
- "externalId": "my.known.id",
- "data": {
- "key1": "value1",
- "key2": "value2"
}
}, - "isAsyncComplete": false
}, - "retries": 3,
- "timeout": 3600,
- "onFailure": "abortWorkflow",
- "dependsOn": [
- {
- "externalId": "my.known.id"
}
]
}
]
}
}
]
}Response samples
- 200
{- "items": [
- {
- "workflowExternalId": "string",
- "version": "string",
- "workflowDefinition": {
- "hash": "string",
- "description": "string",
- "tasks": [
- {
- "externalId": "string",
- "type": "function",
- "name": "string",
- "description": "string",
- "parameters": {
- "function": {
- "externalId": "my.known.id",
- "data": {
- "key1": "value1",
- "key2": "value2"
}
}, - "isAsyncComplete": false
}, - "retries": 3,
- "timeout": 3600,
- "onFailure": "abortWorkflow",
- "dependsOn": [
- {
- "externalId": "my.known.id"
}
]
}
]
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Delete workflow versions
Delete specific versions of one or more workflows.
Authorizations:
query Parameters
| ignoreUnknownIds | boolean Default: true If |
Request Body schema: application/jsonrequired
Array of objects [ 1 .. 100 ] items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "version": "string",
- "workflowExternalId": "string"
}
]
}Response samples
- 200
- 404
{ }Filter workflow versions
List workflow versions matching a given filter.
Authorizations:
Request Body schema: application/jsonrequired
object (ListVersionsFilter) | |
| limit | integer (limit) [ 1 .. 1000 ] The maximum number of results to return. |
| cursor | string (cursor) Cursor to use for paging through results. This cursor is returned in the response of a previous request as |
Responses
Request samples
- Payload
- Python SDK
{- "filter": {
- "workflowFilters": [
- {
- "externalId": "string",
- "version": "string"
}
]
}, - "limit": 100,
- "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo"
}Response samples
- 200
{- "items": [
- {
- "workflowExternalId": "string",
- "version": "string",
- "workflowDefinition": {
- "hash": "string",
- "description": "string",
- "tasks": [
- {
- "externalId": "string",
- "type": "function",
- "name": "string",
- "description": "string",
- "parameters": {
- "function": {
- "externalId": "my.known.id",
- "data": {
- "key1": "value1",
- "key2": "value2"
}
}, - "isAsyncComplete": false
}, - "retries": 3,
- "timeout": 3600,
- "onFailure": "abortWorkflow",
- "dependsOn": [
- {
- "externalId": "my.known.id"
}
]
}
]
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
], - "nextCursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo"
}Retrieve a workflow version
Retrieve a version of a given workflow.
Authorizations:
path Parameters
| workflowExternalId required | string (WorkflowExternalId) <= 255 characters Identifier for a workflow. Must be unique for the project. No trailing or leading whitespace and no null characters allowed. |
| version required | string (Version) <= 255 characters Identifier for a version. Must be unique for the workflow. No trailing or leading whitespace and no null characters allowed. |
Responses
Request samples
- Python SDK
from cognite.client.data_classes import WorkflowVersionId res = client.workflows.versions.retrieve(WorkflowVersionId("my_workflow", "v1")) res = client.workflows.versions.retrieve( [WorkflowVersionId("my_workflow", "v1"), WorkflowVersionId("other", "v3.2")], ignore_unknown_ids=True, ) res = client.workflows.versions.retrieve([("my_workflow", "v1"), ("other", "v3.2")]) res = client.workflows.versions.retrieve("my_workflow", "v1")
Response samples
- 200
- 404
{- "workflowExternalId": "string",
- "version": "string",
- "workflowDefinition": {
- "hash": "string",
- "description": "string",
- "tasks": [
- {
- "externalId": "string",
- "type": "function",
- "name": "string",
- "description": "string",
- "parameters": {
- "function": {
- "externalId": "my.known.id",
- "data": {
- "key1": "value1",
- "key2": "value2"
}
}, - "isAsyncComplete": false
}, - "retries": 3,
- "timeout": 3600,
- "onFailure": "abortWorkflow",
- "dependsOn": [
- {
- "externalId": "my.known.id"
}
]
}
]
}, - "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}Cancel a workflow execution
Stops the specified execution from starting new workflow tasks and sets the workflow execution status to TERMINATED. Already running tasks will be marked as CANCELED. Note that the actions taken by the canceled tasks won't be stopped, and these need to be canceled separately if desired. For example, to cancel a running transformation, use the /transformations/cancel endpoint.
Authorizations:
path Parameters
| executionId required | string (WorkflowExecutionId) = 36 characters Example: 059edaa4-a17a-4102-910e-2c3591500cce UUIDv4 identifier for a workflow execution. |
Request Body schema: application/jsonoptional
| reason | string <= 500 characters Default: "cancelled" Human-readable reason for the cancellation. |
Responses
Request samples
- Payload
- Python SDK
{- "reason": "cancelled"
}Response samples
- 200
- 404
{- "id": "059edaa4-a17a-4102-910e-2c3591500cce",
- "workflowExternalId": "string",
- "version": "string",
- "status": "RUNNING",
- "engineExecutionId": "stringstringstringstringstringstring",
- "createdTime": 1730204346000,
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "reasonForIncompletion": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}
}Filter workflow executions
List workflow executions matching a given filter.
Authorizations:
Request Body schema: application/jsonrequired
object (ListExecutionsFilter) | |
| limit | integer (limit) [ 1 .. 1000 ] The maximum number of results to return. |
| cursor | string (cursor) Cursor to use for paging through results. This cursor is returned in the response of a previous request as |
Responses
Request samples
- Payload
- Python SDK
{- "filter": {
- "workflowFilters": [
- {
- "externalId": "string",
- "version": "string"
}
], - "createdTimeStart": 0,
- "createdTimeEnd": 0,
- "status": [
- "RUNNING"
]
}, - "limit": 100,
- "cursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo"
}Response samples
- 200
{- "items": [
- {
- "id": "059edaa4-a17a-4102-910e-2c3591500cce",
- "workflowExternalId": "string",
- "version": "string",
- "status": "RUNNING",
- "engineExecutionId": "stringstringstringstringstringstring",
- "createdTime": 1730204346000,
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "reasonForIncompletion": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}
}
], - "nextCursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo"
}Retrieve workflow execution details
Retrieve detailed information about a specific workflow execution.
Authorizations:
path Parameters
| executionId required | string (WorkflowExecutionId) = 36 characters Example: 059edaa4-a17a-4102-910e-2c3591500cce UUIDv4 identifier for a workflow execution. |
Responses
Request samples
- Python SDK
res = client.workflows.executions.retrieve_detailed("000560bc-9080-4286-b242-a27bb4819253") res = client.workflows.executions.list() res = client.workflows.executions.retrieve_detailed(res[0].id)
Response samples
- 200
{- "id": "059edaa4-a17a-4102-910e-2c3591500cce",
- "workflowExternalId": "string",
- "workflowDefinition": {
- "hash": "string",
- "description": "string",
- "tasks": [
- {
- "externalId": "string",
- "type": "function",
- "name": "string",
- "description": "string",
- "parameters": {
- "function": {
- "externalId": "my.known.id",
- "data": {
- "key1": "value1",
- "key2": "value2"
}
}, - "isAsyncComplete": false
}, - "retries": 3,
- "timeout": 3600,
- "onFailure": "abortWorkflow",
- "dependsOn": [
- {
- "externalId": "my.known.id"
}
]
}
]
}, - "version": "string",
- "status": "RUNNING",
- "engineExecutionId": "stringstringstringstringstringstring",
- "executedTasks": [
- {
- "id": "stringstringstringstringstringstring",
- "externalId": "string",
- "status": "IN_PROGRESS",
- "taskType": "function",
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "input": {
- "function": {
- "externalId": "my.known.id",
- "data": {
- "key1": "value1",
- "key2": "value2"
}
}, - "isAsyncComplete": false
}, - "output": {
- "callId": 0,
- "functionId": 0,
- "response": { }
}, - "reasonForIncompletion": "string"
}
], - "input": {
- "key1": "value1",
- "key2": "value2"
}, - "metadata": {
- "property1": "string",
- "property2": "string"
}
}Retry workflow execution
This endpoint restarts a previously failed, timed out, or terminated workflow execution by retrying tasks that did not complete successfully. It aims to resume execution activity from the point(s) of failure.
Behavior of the retry operation:
- Targeted Task Retry: Only retries tasks that have stopped in a terminal state such as
CANCELED,FAILED,FAILED_WITH_TERMINAL_ERROR, andTIMED_OUT. Optional tasks are not retried. - Subworkflows and Dynamic Tasks: When a failure occurs within a subworkflow or as part of a dynamic task, only the individual nested tasks that failed are retried. The subworkflow or dynamic task container itself is not retried.
- Retry Limits: Tasks that have reached or exceeded their designated retry limits will not have their retry counts reset to zero. Instead, each retry request permits these tasks a single additional retry.
Authorizations:
path Parameters
| executionId required | string (WorkflowExecutionId) = 36 characters Example: 059edaa4-a17a-4102-910e-2c3591500cce UUIDv4 identifier for a workflow execution. |
Request Body schema: application/jsonrequired
required | object (Authentication) |
Responses
Request samples
- Payload
{- "authentication": {
- "nonce": "hOfy4Zop4N2SPRfl"
}
}Response samples
- 200
- 404
{- "id": "059edaa4-a17a-4102-910e-2c3591500cce",
- "workflowExternalId": "string",
- "version": "string",
- "status": "RUNNING",
- "engineExecutionId": "stringstringstringstringstringstring",
- "createdTime": 1730204346000,
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "reasonForIncompletion": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}
}Run a workflow
Start an execution of a specific version of a workflow.
Authorizations:
path Parameters
| workflowExternalId required | string (WorkflowExternalId) <= 255 characters Identifier for a workflow. Must be unique for the project. No trailing or leading whitespace and no null characters allowed. |
| version required | string (Version) <= 255 characters Identifier for a version. Must be unique for the workflow. No trailing or leading whitespace and no null characters allowed. |
Request Body schema: application/jsonrequired
required | object (Authentication) |
| input | object (ExecutionInput) Input data to the workflow. The content of the input data can be used as input to the workflow tasks using references. The input data should be in JSON format, and is limited to 100KB in size. |
object (metadata) <= 10 properties Custom, application-specific metadata. String key -> String value. Keys have a maximum length of 32 characters, values a maximum of 255, and there can be a maximum of 10 key-value pairs. |
Responses
Request samples
- Payload
- Python SDK
{- "authentication": {
- "nonce": "hOfy4Zop4N2SPRfl"
}, - "input": {
- "key1": "value1",
- "key2": "value2"
}, - "metadata": {
- "property1": "string",
- "property2": "string"
}
}Response samples
- 202
{- "id": "059edaa4-a17a-4102-910e-2c3591500cce",
- "workflowExternalId": "string",
- "version": "string",
- "status": "RUNNING",
- "engineExecutionId": "stringstringstringstringstringstring",
- "createdTime": 1730204346000,
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "reasonForIncompletion": "string",
- "metadata": {
- "property1": "string",
- "property2": "string"
}
}Triggers allow you to automate the execution of your data workflows based on specific conditions, such as scheduled times (defined by cron expressions).
Create or update triggers
Create or update a trigger.
Authorizations:
Request Body schema: application/jsonrequired
Array of objects = 1 items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "string",
- "triggerRule": {
- "triggerType": "schedule",
- "cronExpression": "string",
- "timezone": "Europe/Oslo"
}, - "input": {
- "key1": "value1",
- "key2": "value2"
}, - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "workflowExternalId": "string",
- "workflowVersion": "string",
- "authentication": {
- "nonce": "hOfy4Zop4N2SPRfl"
}
}
]
}Response samples
- 200
{- "items": [
- {
- "externalId": "string",
- "triggerRule": {
- "triggerType": "schedule",
- "cronExpression": "string",
- "timezone": "Europe/Oslo"
}, - "input": {
- "key1": "value1",
- "key2": "value2"
}, - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "workflowExternalId": "string",
- "workflowVersion": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Delete triggers
Delete a trigger.
Authorizations:
Request Body schema: application/jsonrequired
Array of objects = 1 items |
Responses
Request samples
- Payload
- Python SDK
{- "items": [
- {
- "externalId": "string"
}
]
}Response samples
- 200
{ }Get the run history of a trigger
Get information about every run of a trigger. This includes timing information and a reference to the started execution (or an explanation as to why it failed). The returned items are sorted by fireTime in descending order (newest first), followed by externalId in ascending order.
Authorizations:
path Parameters
| triggerExternalId required | string (TriggerExternalId) <= 255 characters Identifier for a trigger. Must be unique for the project. No trailing or leading whitespace and no null characters allowed. |
query Parameters
| limit | integer (limit) [ 1 .. 1000 ] Default: 100 The maximum number of results to return. |
| cursor | string (cursor) Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor to use for paging through results. This cursor is returned in the response of a previous request as |
Responses
Request samples
- Python SDK
res = client.workflows.triggers.list_runs("my_trigger", limit=None)
Response samples
- 200
- 404
{- "items": [
- {
- "fireTime": 0,
- "externalId": "string",
- "workflowExternalId": "string",
- "workflowVersion": "string",
- "workflowExecutionId": "059edaa4-a17a-4102-910e-2c3591500cce",
- "status": "success",
- "reasonForFailure": "string"
}
]
}List triggers
List all triggers. The results are sorted by externalId in ascending order.
Authorizations:
query Parameters
| limit | integer (limit) [ 1 .. 1000 ] Default: 100 The maximum number of results to return. |
| cursor | string (cursor) Example: cursor=4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo Cursor to use for paging through results. This cursor is returned in the response of a previous request as |
Responses
Response samples
- 200
{- "items": [
- {
- "externalId": "string",
- "triggerRule": {
- "triggerType": "schedule",
- "cronExpression": "string",
- "timezone": "Europe/Oslo"
}, - "input": {
- "key1": "value1",
- "key2": "value2"
}, - "metadata": {
- "property1": "string",
- "property2": "string"
}, - "workflowExternalId": "string",
- "workflowVersion": "string",
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
], - "nextCursor": "4zj0Vy2fo0NtNMb229mI9r1V3YG5NBL752kQz1cKtwo"
}Update task status
Update the status of a task that is defined to be completed asynchronously (i.e. task parameter isAsyncComplete is set to true). The status can be set to COMPLETED, FAILED, or FAILED_WITH_TERMINAL_ERROR.
COMPLETED: the workflow execution will continue according to the workflow definition.\FAILED: the task will be retried according to theretriesparameter for the task in the workflow definition.\FAILED_WITH_TERMINAL_ERROR: the task won't be retried.
If anoutputis provided, it'll be merged with the original output of the task.
Authorizations:
path Parameters
| taskId required | string (TaskExecutionId) = 36 characters UUIDv4 identifier for the execution of a workflow task. |
Request Body schema: application/jsonrequired
| status required | string Enum: "COMPLETED" "FAILED" "FAILED_WITH_TERMINAL_ERROR" |
| output | object Custom output data of the task, which will be merged with the original output of the task. The output data should be in JSON format, and is limited to 100KB in size. |
Responses
Request samples
- Payload
- Python SDK
{- "status": "COMPLETED",
- "output": {
- "key1": "value1",
- "key2": "value2"
}
}Response samples
- 200
{- "id": "stringstringstringstringstringstring",
- "externalId": "string",
- "status": "IN_PROGRESS",
- "taskType": "function",
- "startTime": 1730204346000,
- "endTime": 1730204346000,
- "input": {
- "function": {
- "externalId": "my.known.id",
- "data": {
- "key1": "value1",
- "key2": "value2"
}
}, - "isAsyncComplete": false
}, - "output": {
- "callId": 0,
- "functionId": 0,
- "response": { }
}, - "reasonForIncompletion": "string"
}Extend task lease
Extend the lease of a polled task to prevent it from being made available for polling by other workers. Each call extends the lease by 120 seconds. To maintain control of the task, it is recommended to call this endpoint every 60 seconds.
Authorizations:
Request Body schema: application/jsonrequired
Extend the lease of a polled task.
| taskId required | string <uuid> The id of the task to update |
Responses
Request samples
- Payload
{- "taskId": "e6e9d88a-9b63-468a-aec3-b7a11de27af8"
}Response samples
- 200
- 401
- 403
{- "responseTimeoutSeconds": 0
}Poll for tasks
Poll for tasks to be executed by a worker.
Authorizations:
Request Body schema: application/jsonrequired
Poll for tasks to be executed by a worker.
| limit required | integer [ 1 .. 100 ] Default: 1 The maximum number of tasks to return |
| taskType required | string Type of task to poll for. The type is left as a string to allow for any future task types without requiring an update of the API. The list of supported task types is defined in ...<TODO: add link to the list of supported task types in jazz-api in github>... |
Responses
Request samples
- Payload
{- "limit": 1,
- "taskType": "string"
}Response samples
- 200
- 401
- 403
{- "items": [
- {
- "taskId": "e6e9d88a-9b63-468a-aec3-b7a11de27af8",
- "taskType": "string",
- "status": "PENDING",
- "input": { },
- "output": { },
- "token": "string",
- "retryCount": 0,
- "projectId": 0,
- "pollCount": 0,
- "engineExecutionId": "string",
- "responseTimeoutSeconds": 0
}
]
}Update a polled task
Update a polled task with the state of the task execution.
Authorizations:
Request Body schema: application/jsonrequired
Update a polled task with the state of the task execution.
| taskId required | string <uuid> The id of the task to update |
| status required | string Enum: "IN_PROGRESS" "FAILED" "FAILED_WITH_TERMINAL_ERROR" "COMPLETED" The status of the task execution |
| output required | object The output of the task execution. Limited to 100KB in size. For more information about workflows limits, see here. |
| callbackAfterSeconds | integer <int64> The number of seconds to wait before being able to poll the task again. Only required if the task is IN_PROGRESS. |
| reasonForIncompletion | string The reason for the task being in a failed state. This is only used for tasks that are in a failed state. |
Responses
Request samples
- Payload
{- "taskId": "e6e9d88a-9b63-468a-aec3-b7a11de27af8",
- "status": "IN_PROGRESS",
- "output": { },
- "callbackAfterSeconds": 0,
- "reasonForIncompletion": "string"
}Response samples
- 200
- 401
- 403
{ }The simulator resource contains the definitions necessary for Cognite Data Fusion (CDF) to interact with a given simulator. It serves as a central contract that allows APIs, UIs, and integrations (connectors) to utilize the same definitions when dealing with a specific simulator.
Each simulator is uniquely identified and can be associated with various file extension types, model types, step fields, and unit quantities. Simulators are essential for managing data flows between CDF and external simulation tools, ensuring consistency and reliability in data handling.
Limitations:
- A project can have a maximum of 100 simulators
Create Simulators
Create a simulator. Used only by a simulator connector.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "string",
- "name": "PROSPER",
- "fileExtensionTypes": [
- "string"
], - "modelDependencies": [
- {
- "fileExtensionTypes": [
- "string"
], - "fields": [
- {
- "name": "string",
- "label": "string",
- "info": "string"
}
]
}
], - "modelTypes": [
- {
- "name": "string",
- "key": "string"
}
], - "stepFields": [
- {
- "stepType": "string",
- "fields": [
- {
- "name": "string",
- "label": "string",
- "info": "string",
- "options": [
- {
- "label": "Solve Flowsheet",
- "value": "Solve"
}
]
}
]
}
], - "unitQuantities": [
- {
- "name": "Mass",
- "label": "Mass",
- "units": [
- {
- "label": "kg",
- "name": "kg"
}
]
}
]
}
]
}Response samples
- 201
- 403
- 500
{- "items": [
- {
- "id": 0,
- "externalId": "string",
- "name": "string",
- "fileExtensionTypes": [
- "string"
], - "modelDependencies": [
- {
- "fileExtensionTypes": [
- "string"
], - "fields": [
- {
- "name": "string",
- "label": "string",
- "info": "string"
}
]
}
], - "modelTypes": [
- {
- "name": "string",
- "key": "string"
}
], - "stepFields": [
- {
- "stepType": "string",
- "fields": [
- {
- "name": "string",
- "label": "string",
- "info": "string",
- "options": [
- {
- "label": "Solve Flowsheet",
- "value": "Solve"
}
]
}
]
}
], - "unitQuantities": [
- {
- "name": "Mass",
- "label": "Mass",
- "units": [
- {
- "label": "kg",
- "name": "kg"
}
]
}
], - "createdTime": 0,
- "lastUpdatedTime": 0
}
]
}Delete Simulators
Delete a simulator. This will also delete all associated simulator resources (e.g. integrations, models, routines, runs).
Authorizations:
Request Body schema: application/jsonrequired
required | Array of IdRef (object) or ExternalIdRef (object) (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 5559452808603919
}
]
}Response samples
- 200
- 403
- 500
{ }Filter Simulators
List simulators.
Authorizations:
Request Body schema: application/jsonrequired
ListSimulatorsFilters (object) or null | |
| limit | integer (Limit) [ 1 .. 1000 ] Default: 1000 |
Responses
Request samples
- Payload
{- "filter": { },
- "limit": 1000
}Response samples
- 200
- 403
- 500
{- "items": [
- {
- "id": 0,
- "externalId": "string",
- "name": "string",
- "fileExtensionTypes": [
- "string"
], - "modelDependencies": [
- {
- "fileExtensionTypes": [
- "string"
], - "fields": [
- {
- "name": "string",
- "label": "string",
- "info": "string"
}
]
}
], - "modelTypes": [
- {
- "name": "string",
- "key": "string"
}
], - "stepFields": [
- {
- "stepType": "string",
- "fields": [
- {
- "name": "string",
- "label": "string",
- "info": "string",
- "options": [
- {
- "label": "Solve Flowsheet",
- "value": "Solve"
}
]
}
]
}
], - "unitQuantities": [
- {
- "name": "Mass",
- "label": "Mass",
- "units": [
- {
- "label": "kg",
- "name": "kg"
}
]
}
], - "createdTime": 0,
- "lastUpdatedTime": 0
}
]
}Update Simulators
Update a simulator. Used only by a simulator connector.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 0,
- "update": {
- "name": {
- "set": "PROSPER"
}, - "fileExtensionTypes": {
- "set": [
- "string"
]
}, - "modelDependencies": {
- "set": [
- {
- "fileExtensionTypes": [
- "string"
], - "fields": [
- {
- "name": "string",
- "label": "string",
- "info": "string"
}
]
}
]
}, - "modelTypes": {
- "set": [
- {
- "name": "string",
- "key": "string"
}
]
}, - "stepFields": {
- "set": [
- {
- "stepType": "string",
- "fields": [
- {
- "name": "string",
- "label": "string",
- "info": "string",
- "options": [
- null
]
}
]
}
]
}, - "unitQuantities": {
- "set": [
- {
- "name": "Mass",
- "label": "Mass",
- "units": [
- {
- "label": "kg",
- "name": "kg"
}
]
}
]
}
}
}
]
}Response samples
- 200
- 403
- 500
{- "items": [
- {
- "id": 0,
- "externalId": "string",
- "name": "string",
- "fileExtensionTypes": [
- "string"
], - "modelDependencies": [
- {
- "fileExtensionTypes": [
- "string"
], - "fields": [
- {
- "name": "string",
- "label": "string",
- "info": "string"
}
]
}
], - "modelTypes": [
- {
- "name": "string",
- "key": "string"
}
], - "stepFields": [
- {
- "stepType": "string",
- "fields": [
- {
- "name": "string",
- "label": "string",
- "info": "string",
- "options": [
- {
- "label": "Solve Flowsheet",
- "value": "Solve"
}
]
}
]
}
], - "unitQuantities": [
- {
- "name": "Mass",
- "label": "Mass",
- "units": [
- {
- "label": "kg",
- "name": "kg"
}
]
}
], - "createdTime": 0,
- "lastUpdatedTime": 0
}
]
}The simulator integration resource represents a simulator connector in Cognite Data Fusion (CDF). It provides information about the configured connectors for a given simulator, including their status and additional details such as dataset, name, license status, connector version, simulator version, and more. This resource is essential for monitoring and managing the interactions between CDF and external simulators, ensuring proper data flow and integration.
Limitations:
- A project can have a maximum of 20 simulator integrations
Create Simulator Integrations
Create a simulator integration. Used only by a simulator connector.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "string",
- "simulatorExternalId": "string",
- "heartbeat": 0,
- "dataSetId": 0,
- "connectorVersion": "string",
- "simulatorVersion": "string",
- "licenseStatus": "AVAILABLE",
- "licenseLastCheckedTime": 0,
- "connectorStatus": "IDLE",
- "connectorStatusUpdatedTime": 0
}
]
}Response samples
- 201
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "externalId": "string",
- "simulatorExternalId": "string",
- "heartbeat": 0,
- "connectorVersion": "string",
- "licenseStatus": "AVAILABLE",
- "simulatorVersion": "string",
- "licenseLastCheckedTime": 0,
- "connectorStatus": "IDLE",
- "connectorStatusUpdatedTime": 0,
- "active": true,
- "logId": 0,
- "createdTime": 0,
- "lastUpdatedTime": 0
}
]
}Delete Simulator Integrations
Delete a simulator integration. This will also delete all associated simulator resources (e.g. routines, runs).
Authorizations:
Request Body schema: application/jsonrequired
required | Array of IdRef (object) or ExternalIdRef (object) (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 5559452808603919
}
]
}Response samples
- 200
- 403
- 500
{ }Filter Simulator Integrations
Retrieves a list of simulator integrations that match the given criteria.
Authorizations:
Request Body schema: application/jsonrequired
ListSimulatorIntegrationsFilters (object) or null | |
| limit | integer (Limit) [ 1 .. 1000 ] Default: 1000 |
Responses
Request samples
- Payload
{- "filter": {
- "simulatorExternalIds": [
- "PROSPER"
], - "active": true
}, - "limit": 1000
}Response samples
- 200
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "externalId": "string",
- "simulatorExternalId": "string",
- "heartbeat": 0,
- "connectorVersion": "string",
- "licenseStatus": "AVAILABLE",
- "simulatorVersion": "string",
- "licenseLastCheckedTime": 0,
- "connectorStatus": "IDLE",
- "connectorStatusUpdatedTime": 0,
- "active": true,
- "logId": 0,
- "createdTime": 0,
- "lastUpdatedTime": 0
}
]
}Simulation Integration Update
Update a simulator integration. Used only by a simulator connector.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 0,
- "update": {
- "heartbeat": {
- "set": 0
}, - "dataSetId": {
- "set": 0
}, - "connectorVersion": {
- "set": "string"
}, - "simulatorVersion": {
- "set": "string"
}, - "licenseStatus": {
- "set": "AVAILABLE"
}, - "licenseLastCheckedTime": {
- "set": 0
}, - "connectorStatus": {
- "set": "IDLE"
}, - "connectorStatusUpdatedTime": {
- "set": 0
}
}
}
]
}Response samples
- 200
- 400
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "externalId": "string",
- "simulatorExternalId": "string",
- "heartbeat": 0,
- "connectorVersion": "string",
- "licenseStatus": "AVAILABLE",
- "simulatorVersion": "string",
- "licenseLastCheckedTime": 0,
- "connectorStatus": "IDLE",
- "connectorStatusUpdatedTime": 0,
- "active": true,
- "logId": 0,
- "createdTime": 0,
- "lastUpdatedTime": 0
}
]
}The simulator model resource represents an asset modeled in a simulator. This asset could range from a pump or well to a complete processing facility or refinery. The simulator model is the root of its associated revisions, routines, runs, and results. The dataset assigned to a model is inherited by its children. Deleting a model also deletes all its children, thereby maintaining the integrity and hierarchy of the simulation data.
Simulator model revisions track changes and updates to a simulator model over time. Each revision ensures that modifications to models are traceable and allows users to understand the evolution of a given model.
Limitations:
- A project can have a maximum of 1000 simulator models.
- Each simulator model can have a maximum of 200 revisions.
Aggregate Simulator Models
Calculate aggregates for simulator models, considering the optional filter specification.
Authorizations:
Request Body schema: application/jsonrequired
ListSimulatorModelsFilters (object) or null | |
| aggregate required | string (Aggregate) Value: "count" Aggregate type Value: "count" |
Responses
Request samples
- Payload
{- "filter": {
- "simulatorExternalIds": [
- "PROSPER"
], - "externalIdPrefix": "string"
}, - "aggregate": "count"
}Response samples
- 200
- 400
- 403
- 500
{- "items": [
- {
- "count": 0
}
]
}Create Simulator Model
Create a simulator model.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "string",
- "simulatorExternalId": "string",
- "name": "string",
- "description": "string",
- "dataSetId": 0,
- "type": "string"
}
]
}Response samples
- 201
- 400
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "externalId": "string",
- "simulatorExternalId": "string",
- "name": "string",
- "description": "string",
- "type": "string",
- "createdTime": 0,
- "lastUpdatedTime": 0
}
]
}Create Simulator Model Revision
Create a simulator model revision.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "string",
- "modelExternalId": "string",
- "description": "string",
- "fileId": 0,
- "externalDependencies": [
- {
- "file": {
- "id": 0
}, - "arguments": {
- "property1": "string",
- "property2": "string"
}
}
]
}
]
}Response samples
- 201
- 400
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "externalId": "string",
- "simulatorExternalId": "string",
- "modelExternalId": "string",
- "description": "string",
- "fileId": 0,
- "createdByUserId": "string",
- "status": "unknown",
- "statusMessage": "string",
- "versionNumber": 0,
- "logId": 0,
- "createdTime": 0,
- "lastUpdatedTime": 0,
- "externalDependencies": [
- {
- "file": {
- "id": 0
}, - "arguments": {
- "property1": "string",
- "property2": "string"
}
}
]
}
]
}Delete Simulator Model
Delete a simulator model. This will also delete all associated simulator resources (e.g. revisions, routines, runs).
Authorizations:
Request Body schema: application/jsonrequired
required | Array of IdRef (object) or ExternalIdRef (object) (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 5559452808603919
}
]
}Response samples
- 200
- 403
- 500
{ }Filter Simulator Model Revisions
Retrieves a list of simulator model revisions that match the given criteria.
Authorizations:
Request Body schema: application/jsonrequired
ListSimulatorModelRevisionsFilters (object) or null | |
| limit | integer (Limit) [ 1 .. 1000 ] Default: 1000 |
Cursor (string) or Cursor (null) (Cursor) Cursor for pagination | |
Array of Sort (objects) or Sort (null) (Sort) Only supports sorting by one property at a time |
Responses
Request samples
- Payload
{- "filter": {
- "modelExternalIds": [
- "model_1",
- "model_2"
], - "allVersions": false,
- "createdTime": {
- "max": 0,
- "min": 0
}, - "lastUpdatedTime": {
- "max": 0,
- "min": 0
}
}, - "limit": 1000,
- "cursor": "string",
- "sort": [
- {
- "order": "asc",
- "property": "createdTime"
}
]
}Response samples
- 200
- 400
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "externalId": "string",
- "simulatorExternalId": "string",
- "modelExternalId": "string",
- "description": "string",
- "fileId": 0,
- "createdByUserId": "string",
- "status": "unknown",
- "statusMessage": "string",
- "versionNumber": 0,
- "logId": 0,
- "createdTime": 0,
- "lastUpdatedTime": 0
}
], - "nextCursor": "string"
}Filter Simulator Models
Retrieves a list of simulator models that match the given criteria.
Authorizations:
Request Body schema: application/jsonrequired
ListSimulatorModelsFilters (object) or null | |
| limit | integer (Limit) [ 1 .. 1000 ] Default: 1000 |
Cursor (string) or Cursor (null) (Cursor) Cursor for pagination | |
Array of Sort (objects) or Sort (null) (Sort) Only supports sorting by one property at a time |
Responses
Request samples
- Payload
{- "filter": {
- "simulatorExternalIds": [
- "PROSPER"
], - "externalIdPrefix": "string"
}, - "limit": 1000,
- "cursor": "string",
- "sort": [
- {
- "order": "asc",
- "property": "createdTime"
}
]
}Response samples
- 200
- 400
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "externalId": "string",
- "simulatorExternalId": "string",
- "name": "string",
- "description": "string",
- "type": "string",
- "createdTime": 0,
- "lastUpdatedTime": 0
}
], - "nextCursor": "string"
}Retrieve Simulator Model
Retrieve a simulator model by ID or external ID.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of IdRef (object) or ExternalIdRef (object) (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 5559452808603919
}
]
}Response samples
- 200
- 400
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "externalId": "string",
- "simulatorExternalId": "string",
- "name": "string",
- "description": "string",
- "type": "string",
- "createdTime": 0,
- "lastUpdatedTime": 0
}
]
}Retrieve Simulator Model Revision Data
Retrieves a list of simulator model revisions data that match the given criteria.
Authorizations:
header Parameters
| cdf-version | string (Cdf-Version) Examples: alpha beta |
Request Body schema: application/jsonrequired
required | Array of objects (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "modelRevisionExternalId": "string"
}
]
}Response samples
- 200
- 400
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "modelRevisionExternalId": "string",
- "flowsheets": [
- {
- "simulatorObjectNodes": [
- {
- "id": "string",
- "name": "string",
- "type": "string",
- "graphicalObject": {
- "position": {
- "x": 0,
- "y": 0
}, - "height": 0,
- "width": 0,
- "scaleX": 0,
- "scaleY": 0,
- "angle": 0,
- "active": true
}, - "properties": [
- {
- "name": "string",
- "referenceObject": {
- "property1": null,
- "property2": null
}, - "valueType": "STRING",
- "value": "string",
- "unit": {
- "name": null,
- "externalId": null,
- "quantity": null
}, - "readOnly": true
}
]
}
], - "simulatorObjectEdges": [
- {
- "id": "string",
- "name": "string",
- "sourceId": "string",
- "targetId": "string",
- "connectionType": "Material"
}
], - "thermodynamics": {
- "propertyPackages": [
- "string"
], - "components": [
- "string"
]
}
}
], - "info": {
- "property1": "string",
- "property2": "string"
}, - "createdTime": 0,
- "lastUpdatedTime": 0
}
]
}Retrieve Simulator Model Revisions
Retrieve one or more simulator model revisions by IDs or external IDs.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of IdRef (object) or ExternalIdRef (object) (Items) [ 1 .. 100 ] items A list of items |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 5559452808603919
}
]
}Response samples
- 200
- 400
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "externalId": "string",
- "simulatorExternalId": "string",
- "modelExternalId": "string",
- "description": "string",
- "fileId": 0,
- "createdByUserId": "string",
- "status": "unknown",
- "statusMessage": "string",
- "versionNumber": 0,
- "logId": 0,
- "createdTime": 0,
- "lastUpdatedTime": 0,
- "externalDependencies": [
- {
- "file": {
- "id": 0
}, - "arguments": {
- "property1": "string",
- "property2": "string"
}
}
]
}
]
}Update Simulator Model
Update a simulator model.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 0,
- "update": {
- "name": {
- "set": "Model for PROSPER"
}, - "description": {
- "set": "string"
}
}
}
]
}Response samples
- 200
- 400
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "externalId": "string",
- "simulatorExternalId": "string",
- "name": "string",
- "description": "string",
- "type": "string",
- "createdTime": 0,
- "lastUpdatedTime": 0
}
]
}Update Simulator Model Revision
Update a simulator model revision. Used only by a simulator connector.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 0,
- "update": {
- "status": {
- "set": "unknown"
}, - "statusMessage": {
- "set": "string"
}
}
}
]
}Response samples
- 200
- 400
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "externalId": "string",
- "simulatorExternalId": "string",
- "modelExternalId": "string",
- "description": "string",
- "fileId": 0,
- "createdByUserId": "string",
- "status": "unknown",
- "statusMessage": "string",
- "versionNumber": 0,
- "logId": 0,
- "createdTime": 0,
- "lastUpdatedTime": 0,
- "externalDependencies": [
- {
- "file": {
- "id": 0
}, - "arguments": {
- "property1": "string",
- "property2": "string"
}
}
]
}
]
}Update Simulator Model Revision Data
Updates simulator model revision data.
Authorizations:
header Parameters
| cdf-version | string (Cdf-Version) Examples: alpha beta |
Request Body schema: application/jsonrequired
required | Array of objects (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "modelRevisionExternalId": "string",
- "update": {
- "flowsheets": {
- "set": [
- {
- "simulatorObjectNodes": [
- {
- "id": "string",
- "name": "string",
- "type": "string",
- "graphicalObject": {
- "position": null,
- "height": null,
- "width": null,
- "scaleX": null,
- "scaleY": null,
- "angle": null,
- "active": null
}, - "properties": [
- null
]
}
], - "simulatorObjectEdges": [
- {
- "id": "string",
- "name": "string",
- "sourceId": "string",
- "targetId": "string",
- "connectionType": "Material"
}
], - "thermodynamics": {
- "propertyPackages": [
- "string"
], - "components": [
- "string"
]
}
}
]
}, - "info": {
- "set": {
- "property1": "string",
- "property2": "string"
}
}
}
}
]
}Response samples
- 200
- 400
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "modelRevisionExternalId": "string",
- "flowsheets": [
- {
- "simulatorObjectNodes": [
- {
- "id": "string",
- "name": "string",
- "type": "string",
- "graphicalObject": {
- "position": {
- "x": 0,
- "y": 0
}, - "height": 0,
- "width": 0,
- "scaleX": 0,
- "scaleY": 0,
- "angle": 0,
- "active": true
}, - "properties": [
- {
- "name": "string",
- "referenceObject": {
- "property1": null,
- "property2": null
}, - "valueType": "STRING",
- "value": "string",
- "unit": {
- "name": null,
- "externalId": null,
- "quantity": null
}, - "readOnly": true
}
]
}
], - "simulatorObjectEdges": [
- {
- "id": "string",
- "name": "string",
- "sourceId": "string",
- "targetId": "string",
- "connectionType": "Material"
}
], - "thermodynamics": {
- "propertyPackages": [
- "string"
], - "components": [
- "string"
]
}
}
], - "info": {
- "property1": "string",
- "property2": "string"
}, - "createdTime": 0,
- "lastUpdatedTime": 0
}
]
}The simulator routine resource defines instructions on interacting with a simulator model. A simulator routine includes:
- Inputs (values set into the simulator model)
- Commands (actions to be performed by the simulator)
- Outputs (values read from the simulator model)
Simulator routines can have multiple revisions, enabling users to track changes and evolve the routine over time. Each model can have multiple routines, each performing different objectives such as calculating optimal operation setpoints, forecasting production, benchmarking asset performance, and more.
Limitations:
- Each simulator model can have a maximum of 10 simulator routines.
- Each simulator routine can have a maximum of 10 revisions.
- The total size of each routine revision can be a maximum of 50.00 KB.
Create Simulator Routine
Create a simulator routine.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "string",
- "modelExternalId": "string",
- "simulatorIntegrationExternalId": "string",
- "name": "Fluid Sloshing in Tank",
- "description": "string"
}
]
}Response samples
- 201
- 400
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "externalId": "string",
- "simulatorExternalId": "string",
- "modelExternalId": "string",
- "simulatorIntegrationExternalId": "string",
- "name": "string",
- "description": "string",
- "createdTime": 0,
- "lastUpdatedTime": 0
}
]
}Create Simulator Routine Revision
The total size of the request body can be a maximum of 50.00 KB.
When creating a simulator routine revision, be mindful of the following:
- The amount and size of the inputs you provide to the simulator routine.
- The size of the outputs you expect from the simulator routine.
The total size of the data sent by a simulator connector cannot exceed 100.00 KB per simulation run.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "string",
- "routineExternalId": "fluid_sloshing",
- "configuration": {
- "schedule": {
- "enabled": false
}, - "dataSampling": {
- "enabled": false
}, - "logicalCheck": [
- {
- "enabled": true,
- "timeseriesExternalId": "string",
- "aggregate": "average",
- "operator": "eq",
- "value": 0
}
], - "steadyStateDetection": [
- {
- "enabled": true,
- "timeseriesExternalId": "string",
- "aggregate": "average",
- "minSectionSize": 0,
- "varThreshold": 0,
- "slopeThreshold": 0
}
], - "inputs": [ ],
- "outputs": [ ]
}, - "script": [
- {
- "order": 1,
- "description": "string",
- "steps": [
- {
- "order": 1,
- "description": "string",
- "stepType": "Get",
- "arguments": {
- "referenceId": "string"
}
}
]
}
]
}
]
}Response samples
- 201
- 400
- 403
- 413
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "externalId": "fluid_sloshing",
- "simulatorExternalId": "string",
- "routineExternalId": "string",
- "simulatorIntegrationExternalId": "string",
- "modelExternalId": "string",
- "createdByUserId": "string",
- "versionNumber": 0,
- "createdTime": 0,
- "configuration": {
- "schedule": {
- "enabled": false
}, - "dataSampling": {
- "enabled": false
}, - "logicalCheck": [
- {
- "enabled": true,
- "timeseriesExternalId": "string",
- "aggregate": "average",
- "operator": "eq",
- "value": 0
}
], - "steadyStateDetection": [
- {
- "enabled": true,
- "timeseriesExternalId": "string",
- "aggregate": "average",
- "minSectionSize": 0,
- "varThreshold": 0,
- "slopeThreshold": 0
}
], - "inputs": [ ],
- "outputs": [ ]
}, - "script": [
- {
- "order": 1,
- "description": "string",
- "steps": [
- {
- "order": 1,
- "description": "string",
- "stepType": "Get",
- "arguments": {
- "referenceId": "string"
}
}
]
}
]
}
]
}Delete Simulator Routine
Delete a simulator routine. This will also delete all associated simulator resources (e.g. revisions, runs, data).
Authorizations:
Request Body schema: application/jsonrequired
required | Array of IdRef (object) or ExternalIdRef (object) (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 5559452808603919
}
]
}Response samples
- 200
- 403
- 500
{ }Filter Simulator Routine Revisions
Retrieves a list of simulator routine revisions that match the given criteria.
Authorizations:
Request Body schema: application/jsonrequired
ListSimulatorRoutineRevisionsFilters (object) or null | |
| limit | integer (Limit) [ 1 .. 20 ] Default: 10 |
Cursor (string) or Cursor (null) (Cursor) Cursor for pagination | |
Array of Sort (objects) or Sort (null) (Sort) Only supports sorting by one property at a time | |
IncludeAllFields (boolean) or IncludeAllFields (null) (IncludeAllFields) Default: false If all fields should be included in the response. Defaults to false which does not include script, configuration.inputs and configuration.outputs in the response. If true - all fields are included. |
Responses
Request samples
- Payload
{- "filter": {
- "routineExternalIds": [
- "routine_1",
- "routine_2"
], - "allVersions": false,
- "modelExternalIds": [
- "model_1",
- "model_2"
], - "simulatorIntegrationExternalIds": [
- "simulator_integration_1",
- "simulator_integration_2"
], - "simulatorExternalIds": [
- "PROSPER",
- "PetroSIM"
], - "createdTime": {
- "max": 0,
- "min": 0
}
}, - "limit": 10,
- "cursor": "string",
- "sort": [
- {
- "order": "asc",
- "property": "createdTime"
}
], - "includeAllFields": false
}Response samples
- 200
- 400
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "externalId": "fluid_sloshing",
- "simulatorExternalId": "string",
- "routineExternalId": "string",
- "simulatorIntegrationExternalId": "string",
- "modelExternalId": "string",
- "createdByUserId": "string",
- "versionNumber": 0,
- "createdTime": 0,
- "configuration": {
- "schedule": {
- "enabled": false
}, - "dataSampling": {
- "enabled": false
}, - "logicalCheck": [
- {
- "enabled": true,
- "timeseriesExternalId": "string",
- "aggregate": "average",
- "operator": "eq",
- "value": 0
}
], - "steadyStateDetection": [
- {
- "enabled": true,
- "timeseriesExternalId": "string",
- "aggregate": "average",
- "minSectionSize": 0,
- "varThreshold": 0,
- "slopeThreshold": 0
}
], - "inputs": [ ],
- "outputs": [ ]
}, - "script": [
- {
- "order": 1,
- "description": "string",
- "steps": [
- {
- "order": 1,
- "description": "string",
- "stepType": "Get",
- "arguments": {
- "referenceId": "string"
}
}
]
}
]
}
], - "nextCursor": "string"
}Filter Simulator Routines
Retrieves a list of simulator routines that match the given criteria.
Authorizations:
Request Body schema: application/jsonrequired
ListSimulatorRoutinesFilters (object) or null | |
| limit | integer (Limit) [ 1 .. 1000 ] Default: 1000 |
Cursor (string) or Cursor (null) (Cursor) Cursor for pagination | |
Array of Sort (objects) or Sort (null) (Sort) Only supports sorting by one property at a time |
Responses
Request samples
- Payload
{- "filter": {
- "modelExternalIds": [
- "model_1",
- "model_2"
], - "simulatorIntegrationExternalIds": [
- "simulator_integration_1",
- "simulator_integration_2"
]
}, - "limit": 1000,
- "cursor": "string",
- "sort": [
- {
- "order": "asc",
- "property": "createdTime"
}
]
}Response samples
- 200
- 400
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "externalId": "string",
- "simulatorExternalId": "string",
- "modelExternalId": "string",
- "simulatorIntegrationExternalId": "string",
- "name": "string",
- "description": "string",
- "createdTime": 0,
- "lastUpdatedTime": 0
}
], - "nextCursor": "string"
}Retrieve Simulator Routine Revisions
Retrieve one or more simulator routine revisions by IDs or external IDs.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of IdRef (object) or ExternalIdRef (object) (Items) [ 1 .. 20 ] items A list of items |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 5559452808603919
}
]
}Response samples
- 200
- 400
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "externalId": "fluid_sloshing",
- "simulatorExternalId": "string",
- "routineExternalId": "string",
- "simulatorIntegrationExternalId": "string",
- "modelExternalId": "string",
- "createdByUserId": "string",
- "versionNumber": 0,
- "createdTime": 0,
- "configuration": {
- "schedule": {
- "enabled": false
}, - "dataSampling": {
- "enabled": false
}, - "logicalCheck": [
- {
- "enabled": true,
- "timeseriesExternalId": "string",
- "aggregate": "average",
- "operator": "eq",
- "value": 0
}
], - "steadyStateDetection": [
- {
- "enabled": true,
- "timeseriesExternalId": "string",
- "aggregate": "average",
- "minSectionSize": 0,
- "varThreshold": 0,
- "slopeThreshold": 0
}
], - "inputs": [ ],
- "outputs": [ ]
}, - "script": [
- {
- "order": 1,
- "description": "string",
- "steps": [
- {
- "order": 1,
- "description": "string",
- "stepType": "Get",
- "arguments": {
- "referenceId": "string"
}
}
]
}
]
}
]
}Every time a simulation routine executes, a simulation run object is created. This object ensures that each execution of a routine is documented and traceable. Each run has an associated simulation data resource, which stores the inputs and outputs of a simulation run, capturing the values set into and read from the simulator model to ensure the traceability and integrity of the simulation data.
Simulation runs provide a historical record of the simulations performed, allowing users to analyze and compare different runs, track changes over time, and make informed decisions based on the simulation results.
Limitations:
- A retention policy is in place for simulation runs, allowing up to 100000 entries. When this limit is reached, the oldest runs are deleted to make room for new ones.
- The total size of all inputs for a simulation run can be a maximum of 50.00 KB.
- The total size of simulation run data sent by the connector can be a maximum of 100.00 KB.
Filter Simulation Runs
Retrieves a list of simulation runs that match the given criteria.
Authorizations:
Request Body schema: application/jsonrequired
ListSimulationRunsFilters (object) or null | |
| limit | integer (Limit) [ 1 .. 1000 ] Default: 1000 |
Cursor (string) or Cursor (null) (Cursor) Cursor for pagination | |
(Array of Sort (SortByCreatedTime (object) or SortBySimulationTime (object))) or Sort (null) (Sort) Only supports sorting by one property at a time |
Responses
Request samples
- Payload
{- "filter": {
- "status": "ready",
- "runType": "external",
- "simulatorIntegrationExternalIds": [
- "PROSPER_connector",
- "DWSIM_connector"
], - "simulatorExternalIds": [
- "PROSPER",
- "PetroSIM"
], - "modelExternalIds": [
- "PROSPER_model",
- "PetroSIM_model"
], - "routineExternalIds": [
- "PROSPER_routine",
- "PetroSIM_routine"
], - "routineRevisionExternalIds": [
- "routineRevisionForModel"
], - "modelRevisionExternalIds": [
- "wellModel"
], - "createdTime": {
- "max": 0,
- "min": 0
}, - "simulationTime": {
- "max": 0,
- "min": 0
}
}, - "limit": 1000,
- "cursor": "string",
- "sort": [
- {
- "order": "asc",
- "property": "createdTime"
}
]
}Response samples
- 200
- 400
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "simulatorExternalId": "string",
- "simulatorIntegrationExternalId": "string",
- "modelExternalId": "string",
- "modelRevisionExternalId": "string",
- "routineExternalId": "string",
- "routineRevisionExternalId": "string",
- "runTime": 0,
- "simulationTime": 0,
- "status": "ready",
- "statusMessage": "string",
- "runType": "external",
- "userId": "string",
- "logId": 0,
- "createdTime": 0,
- "lastUpdatedTime": 0
}
], - "nextCursor": "string"
}Retrieve Simulation
Retrieve a simulation run by ID.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 5559452808603919
}
]
}Response samples
- 200
- 400
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "simulatorExternalId": "string",
- "simulatorIntegrationExternalId": "string",
- "modelExternalId": "string",
- "modelRevisionExternalId": "string",
- "routineExternalId": "string",
- "routineRevisionExternalId": "string",
- "runTime": 0,
- "simulationTime": 0,
- "status": "ready",
- "statusMessage": "string",
- "runType": "external",
- "userId": "string",
- "logId": 0,
- "createdTime": 0,
- "lastUpdatedTime": 0
}
]
}Retrieve Simulation Data
Retrieve data associated with a simulation run by ID.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "runId": 5559452808603919
}
]
}Response samples
- 200
- 400
- 403
- 500
{- "items": [
- {
- "runId": 0,
- "inputs": [
- {
- "referenceId": "string",
- "value": "string",
- "valueType": "STRING",
- "unit": {
- "name": "kg",
- "externalId": "mass:kilogm"
}, - "simulatorObjectReference": { },
- "timeseriesExternalId": "string",
- "overridden": true
}
], - "outputs": [
- {
- "referenceId": "string",
- "value": "string",
- "valueType": "STRING",
- "unit": {
- "name": "kg",
- "externalId": "mass:kilogm"
}, - "simulatorObjectReference": { },
- "timeseriesExternalId": "string"
}
]
}
]
}Run Simulation
Request to run a simulator routine asynchronously.
The total size of the request body can be a maximum of 50.00 KB.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of SimulationRunCommandByRoutine (object) or SimulationRunCommandByRoutineRevision (object) (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "runType": "external",
- "runTime": 0,
- "queue": false,
- "logSeverity": "Debug",
- "inputs": [
- {
- "referenceId": "string",
- "value": "string",
- "unit": {
- "name": "kg"
}
}
], - "routineExternalId": "calculation_1"
}
]
}Response samples
- 201
- 400
- 403
- 413
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "simulatorExternalId": "string",
- "simulatorIntegrationExternalId": "string",
- "modelExternalId": "string",
- "modelRevisionExternalId": "string",
- "routineExternalId": "string",
- "routineRevisionExternalId": "string",
- "runTime": 0,
- "simulationTime": 0,
- "status": "ready",
- "statusMessage": "string",
- "runType": "external",
- "userId": "string",
- "logId": 0,
- "createdTime": 0,
- "lastUpdatedTime": 0
}
]
}Simulation Callback
Callback to report a simulation run status. Used only by a simulator connector.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 0,
- "status": "ready",
- "statusMessage": "string",
- "simulationTime": 0,
- "inputs": [ ],
- "outputs": [ ]
}
]
}Response samples
- 200
- 400
- 403
- 413
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "simulatorExternalId": "string",
- "simulatorIntegrationExternalId": "string",
- "modelExternalId": "string",
- "modelRevisionExternalId": "string",
- "routineExternalId": "string",
- "routineRevisionExternalId": "string",
- "runTime": 0,
- "simulationTime": 0,
- "status": "ready",
- "statusMessage": "string",
- "runType": "external",
- "userId": "string",
- "logId": 0,
- "createdTime": 0,
- "lastUpdatedTime": 0
}
]
}Simulator logs track what happens during simulation runs, model parsing, and generic connector logic. They provide valuable information for monitoring, debugging, and auditing.
Simulator logs capture important events, messages, and exceptions that occur during the execution of simulations, model parsing, and connector operations. They help users identify issues, diagnose problems, and gain insights into the behavior of the simulator integrations.
Limitations:
- A retention policy allows up to 10000 log entries per logId. When this limit is reached, the oldest logs are deleted to make room for new ones.
Retrieve Simulator Logs
Retrieve one or more simulator logs by IDs.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (Items) [ 1 .. 100 ] items A list of items |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 5559452808603919
}
]
}Response samples
- 200
- 400
- 403
- 500
{- "items": [
- {
- "dataSetId": 5559452808603919,
- "id": 0,
- "data": [
- {
- "timestamp": 0,
- "message": "string",
- "severity": "Debug"
}
], - "severity": "Debug",
- "createdTime": 0,
- "lastUpdatedTime": 0
}
]
}Update Simulator Log
Update a simulator log. Used only by a simulator connector.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (Items) A list with a single item |
Responses
Request samples
- Payload
{- "items": [
- {
- "id": 0,
- "update": {
- "data": {
- "add": [
- {
- "timestamp": 0,
- "message": "string",
- "severity": "Debug"
}
]
}
}
}
]
}Response samples
- 200
- 400
- 403
- 500
{ }Units Catalog API provides a standardized list of units that can be used in Cognite Data Fusion. The content this API serves is based on the CDF Units Catalog
List all units
List all units.
Authorizations:
Responses
Request samples
- JavaScript SDK
- Python SDK
const units = await client.units.list();
Response samples
- 200
{- "items": [
- {
- "externalId": "temperature:deg_c",
- "name": "DEG_C",
- "longName": "degree Celsius",
- "symbol": "°C",
- "aliasNames": [
- "°C",
- "C",
- "deg C",
- "degC",
- "DegC"
], - "quantity": "Temperature",
- "conversion": {
- "multiplier": 1,
- "offset": 273.15
}, - "source": "qudt.org",
}
]
}Retrieve unit by external ID
Retrieve a single unit by its external ID.
Authorizations:
path Parameters
| externalId required | string (Externalid) External ID of the unit |
Responses
Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "temperature:deg_c",
- "name": "DEG_C",
- "longName": "degree Celsius",
- "symbol": "°C",
- "aliasNames": [
- "°C",
- "C",
- "deg C",
- "degC",
- "DegC"
], - "quantity": "Temperature",
- "conversion": {
- "multiplier": 1,
- "offset": 273.15
}, - "source": "qudt.org",
}
]
}Retrieve units by external IDs
Retrieves one or more units by external ID. The response returns the units in the same order as in the request.
Authorizations:
Request Body schema: application/jsonrequired
required | Array of objects (Items) |
| ignoreUnknownIds | boolean or null (IgnoreUnknownIds) Default: false Ignore external IDs that are not found. If set to true, no error will be thrown if an external ID is not found. |
Responses
Request samples
- Payload
- JavaScript SDK
- Python SDK
{- "items": [
- {
- "externalId": "string"
}
], - "ignoreUnknownIds": false
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "temperature:deg_c",
- "name": "DEG_C",
- "longName": "degree Celsius",
- "symbol": "°C",
- "aliasNames": [
- "°C",
- "C",
- "deg C",
- "degC",
- "DegC"
], - "quantity": "Temperature",
- "conversion": {
- "multiplier": 1,
- "offset": 273.15
}, - "source": "qudt.org",
}
]
}Unit system is a collection of default units for different quantities. This API provides a list of supported unit systems and their associated quantities and respective unit.
List all unit systems
List all unit systems.
Authorizations:
Responses
Request samples
- JavaScript SDK
- Python SDK
const units = await client.units.listUnitSystems();
Response samples
- 200
{- "items": [
- {
- "name": "SI",
- "quantities": [
- {
- "name": "Temperature",
- "unitExternalId": "temperature:deg_c"
}
]
}
]
}Create application entities
Create application entities
Authorizations:
path Parameters
| dataNamespace required | string dataNamespace |
| entitySet required | string entitySet |
Request Body schema: application/json
A request containing the information needed to create entities.
Array of objects (Entity) [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id",
- "visibility": "PUBLIC",
- "data": { }
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "visibility": "PUBLIC",
- "data": { },
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Delete application entities
Delete application entities by external Ids
Authorizations:
path Parameters
| dataNamespace required | string dataNamespace |
| entitySet required | string entitySet |
Request Body schema: application/json
A request containing the list of objects containing external Ids to delete app entities
required | Array of objects [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
]
}Response samples
- 200
- 400
{ }List application entities
Authorizations:
path Parameters
| dataNamespace required | string dataNamespace |
| entitySet required | string entitySet |
Request Body schema: application/jsonrequired
List entities
object (EntityListFilter) | |
| limit | integer <int32> [ 1 .. 1000 ] Default: 100 Maximum number of items that the client want to get back. |
Responses
Request samples
- Payload
{- "filter": {
- "visibility": "PUBLIC",
- "isOwned": true
}, - "limit": 100
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "visibility": "PUBLIC",
- "data": { },
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Retrieve application entities
Retrieves one or more application entities by external ID. The response returns the entities in the same order as in the request.
Authorizations:
path Parameters
| dataNamespace required | string dataNamespace |
| entitySet required | string entitySet |
Request Body schema: application/json
List of objects containing externalIds to retrieve app entities
required | Array of objects [ 1 .. 1000 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "externalId": "my.known.id"
}
]
}Response samples
- 200
- 400
{- "items": [
- {
- "externalId": "my.known.id",
- "visibility": "PUBLIC",
- "data": { },
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000
}
]
}Create location filter
Create location filter
Authorizations:
Request Body schema: application/json
| externalId required | string (CogniteExternalId) <= 255 characters The external ID provided by the client. Must be unique for the resource type. |
| name required | string <= 255 characters The name of the location filter |
| parentId | integer <int64> [ 1 .. 9007199254740991 ] The ID of the parent location filter |
| description | string <= 255 characters The description of the location filter |
Array of objects (LocationFilterDataModel) The data models in the location filter | |
| instanceSpaces | Array of strings The list of spaces that instances are in |
object (LocationFilterScene) The scene config for the location filter | |
object (LocationFilterAssetCentric) The filter definition for asset centric resource types | |
Array of objects (LocationFilterView) The list of view mappings |
Responses
Request samples
- Payload
{- "externalId": "my.known.id",
- "name": "string",
- "parentId": 1,
- "description": "string",
- "dataModels": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string"
}
], - "instanceSpaces": [
- "string"
], - "scene": {
- "externalId": "string",
- "space": "string"
}, - "assetCentric": {
- "assets": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "events": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "files": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "timeseries": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "sequences": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "views": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string",
- "representsEntity": "MAINTENANCE_ORDER"
}
]
}Response samples
- 200
- 400
- 429
{- "id": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "externalId": "my.known.id",
- "name": "string",
- "parentId": 1,
- "description": "string",
- "dataModels": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string"
}
], - "instanceSpaces": [
- "string"
], - "scene": {
- "externalId": "string",
- "space": "string"
}, - "assetCentric": {
- "assets": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "events": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "files": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "timeseries": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "sequences": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "views": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string",
- "representsEntity": "MAINTENANCE_ORDER"
}
]
}Delete a location filter by its ID
Delete a location filter by its ID
Authorizations:
path Parameters
| id required | integer <int64> (CogniteInternalId) [ 1 .. 9007199254740991 ] A server-generated ID for the object. |
Responses
Response samples
- 200
- 400
- 429
{- "id": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "externalId": "my.known.id",
- "name": "string",
- "parentId": 1,
- "description": "string",
- "dataModels": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string"
}
], - "instanceSpaces": [
- "string"
], - "scene": {
- "externalId": "string",
- "space": "string"
}, - "assetCentric": {
- "assets": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "events": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "files": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "timeseries": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "sequences": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "views": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string",
- "representsEntity": "MAINTENANCE_ORDER"
}
]
}List location filters
List location filters
Authorizations:
Request Body schema: application/json
| flat | boolean Default: false Determines whether to return location filters in a flat list or in a hierarchical format |
Responses
Request samples
- Payload
{- "flat": false
}Response samples
- 200
- 400
- 429
{- "items": [
- {
- "id": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "externalId": "my.known.id",
- "name": "string",
- "parentId": 1,
- "description": "string",
- "dataModels": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string"
}
], - "instanceSpaces": [
- "string"
], - "scene": {
- "externalId": "string",
- "space": "string"
}, - "assetCentric": {
- "assets": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "events": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "files": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "timeseries": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "sequences": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "views": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string",
- "representsEntity": "MAINTENANCE_ORDER"
}
]
}
]
}Retrieve a location filter by its ID
Retrieve a location filter by its ID
Authorizations:
path Parameters
| id required | integer <int64> (CogniteInternalId) [ 1 .. 9007199254740991 ] A server-generated ID for the object. |
Responses
Response samples
- 200
- 400
- 429
{- "id": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "externalId": "my.known.id",
- "name": "string",
- "parentId": 1,
- "description": "string",
- "dataModels": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string"
}
], - "instanceSpaces": [
- "string"
], - "scene": {
- "externalId": "string",
- "space": "string"
}, - "assetCentric": {
- "assets": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "events": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "files": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "timeseries": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "sequences": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "views": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string",
- "representsEntity": "MAINTENANCE_ORDER"
}
]
}Retrieve location filters by IDs
Retrieve location filters by IDs
Authorizations:
Request Body schema: application/json
| ids required | Array of numbers The array of location filter ids to retrieve |
Responses
Request samples
- Payload
{- "ids": [
- 0
]
}Response samples
- 200
- 400
- 429
{- "items": [
- {
- "id": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "externalId": "my.known.id",
- "name": "string",
- "parentId": 1,
- "description": "string",
- "dataModels": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string"
}
], - "instanceSpaces": [
- "string"
], - "scene": {
- "externalId": "string",
- "space": "string"
}, - "assetCentric": {
- "assets": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "events": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "files": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "timeseries": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "sequences": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "views": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string",
- "representsEntity": "MAINTENANCE_ORDER"
}
]
}
]
}Update location filter
Update location filter. This operation doesn't support partial updates so you need to pass the whole location filter object.
Authorizations:
path Parameters
| id required | integer <int64> (CogniteInternalId) [ 1 .. 9007199254740991 ] A server-generated ID for the object. |
Request Body schema: application/json
| externalId required | string (CogniteExternalId) <= 255 characters The external ID provided by the client. Must be unique for the resource type. |
| name required | string <= 255 characters The name of the location filter |
| parentId | integer <int64> [ 1 .. 9007199254740991 ] The ID of the parent location filter |
| description | string <= 255 characters The description of the location filter |
Array of objects (LocationFilterDataModel) The data models in the location filter | |
| instanceSpaces | Array of strings The list of spaces that instances are in |
object (LocationFilterScene) The scene config for the location filter | |
object (LocationFilterAssetCentric) The filter definition for asset centric resource types | |
Array of objects (LocationFilterView) The list of view mappings |
Responses
Request samples
- Payload
{- "externalId": "my.known.id",
- "name": "string",
- "parentId": 1,
- "description": "string",
- "dataModels": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string"
}
], - "instanceSpaces": [
- "string"
], - "scene": {
- "externalId": "string",
- "space": "string"
}, - "assetCentric": {
- "assets": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "events": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "files": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "timeseries": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "sequences": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "views": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string",
- "representsEntity": "MAINTENANCE_ORDER"
}
]
}Response samples
- 200
- 400
- 429
{- "id": 1,
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "externalId": "my.known.id",
- "name": "string",
- "parentId": 1,
- "description": "string",
- "dataModels": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string"
}
], - "instanceSpaces": [
- "string"
], - "scene": {
- "externalId": "string",
- "space": "string"
}, - "assetCentric": {
- "assets": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "events": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "files": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "timeseries": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "sequences": {
- "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "dataSetIds": [
- 0
], - "assetSubtreeIds": [
- {
- "externalId": "my.known.id"
}
], - "externalIdPrefix": "string"
}, - "views": [
- {
- "externalId": "string",
- "space": "string",
- "version": "string",
- "representsEntity": "MAINTENANCE_ORDER"
}
]
}Get User Preferences
Get persistent user preferences such as language, timezone and dateFormat etc. for a CDF user.
Authorizations:
Responses
Response samples
- 200
- 400
- 429
{- "general": {
- "language": "de",
- "timezone": "GMT+02:00",
- "dateFormat": "YYYY/MM/DD",
- "timeFormat": "H:mm"
}
}Update User Preferences
Update persistent user preferences such as language, timezone and dateFormat etc. for a CDF user.
Authorizations:
Request Body schema: application/json
object |
Responses
Request samples
- Payload
{- "general": {
- "update": {
- "language": {
- "set": "de"
}, - "timezone": {
- "set": "GMT+02:00"
}, - "dateFormat": {
- "set": "YYYY/MM/DD"
}, - "timeFormat": {
- "set": "H:mm"
}
}
}
}Response samples
- 200
- 400
- 429
{- "general": {
- "language": "de",
- "timezone": "GMT+02:00",
- "dateFormat": "YYYY/MM/DD",
- "timeFormat": "H:mm"
}
}Create or update user history app items
Creates or updates user history app items. If an app already exists, its timestamp will be updated. Maximum of 100 items allowed.
Authorizations:
Request Body schema: application/json
required | Array of objects (UserHistoryAppItem) [ 1 .. 100 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "app": "string"
}
]
}Response samples
- 200
- 400
- 429
{- "items": [
- {
- "app": "string",
- "timestamp": 1730204346000
}
]
}Create or update user history resource items
Create or update resource history items. If a resource already exists, its timestamp will be updated. Maximum of 30 items allowed.
Authorizations:
Request Body schema: application/json
required | Array of objects (UserHistoryResourceItem) [ 1 .. 30 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "resourceId": "my.known.id",
- "app": "string",
- "action": "read",
- "name": "string",
- "path": "string"
}
]
}Response samples
- 200
- 400
- 429
{- "items": [
- {
- "resourceId": "my.known.id",
- "app": "string",
- "action": "read",
- "name": "string",
- "path": "string",
- "timestamp": 1730204346000
}
]
}Delete user history resource items
Delete resource history items based on the provided list of resource IDs.
Authorizations:
Request Body schema: application/json
required | Array of objects [ 1 .. 30 ] items |
Responses
Request samples
- Payload
{- "items": [
- {
- "resourceId": "my.known.id"
}
]
}Response samples
- 200
- 400
- 429
{ }Get user history app items
Gets recent apps for quick access. Returns up to 100 most recent apps sorted by timestamp in descending order.
Authorizations:
Responses
Response samples
- 200
- 400
- 429
{- "items": [
- {
- "app": "string",
- "timestamp": 1730204346000
}
]
}Get user history resource items
Get recent activity resources. Returns up to 30 most recent resources sorted by timestamp in descending order.
Authorizations:
Responses
Response samples
- 200
- 400
- 429
{- "items": [
- {
- "resourceId": "my.known.id",
- "app": "string",
- "action": "read",
- "name": "string",
- "path": "string",
- "timestamp": 1730204346000
}
]
}List view configurations
Authorizations:
Request Body schema: application/json
Responses
Request samples
- Payload
{ }Response samples
- 200
- 400
- 429
{- "items": [
- {
- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "id": 1,
- "view": {
- "externalId": "string",
- "space": "string"
}, - "useAsName": "string",
- "useAsDescription": "string",
- "columnsLayout": [
- {
- "property": "string",
- "disabled": true,
- "selected": true,
- "hidden": true
}
], - "filterLayout": [
- {
- "property": "string",
- "disabled": true,
- "selected": true,
- "hidden": true
}
], - "propertiesLayout": [
- {
- "property": "string",
- "disabled": true,
- "selected": true,
- "hidden": true
}
]
}
]
}Upsert view configurations
Authorizations:
Request Body schema: application/json
| id | integer <int64> [ 1 .. 9007199254740991 ] A server-generated ID for the object. When updating, this property needs to be provided. Optional when creating a new object. |
required | object (SearchConfigView) The configuration for one specific view |
| useAsName | string The name of property to use for the name column in the UI. |
| useAsDescription | string The name of property to use for the description column in the UI. |
Array of objects (SearchConfigViewProperty) Array of configurations per property | |
Array of objects (SearchConfigViewProperty) Array of configurations per property | |
Array of objects (SearchConfigViewProperty) Array of configurations per property |
Responses
Request samples
- Payload
{- "id": 1,
- "view": {
- "externalId": "string",
- "space": "string"
}, - "useAsName": "string",
- "useAsDescription": "string",
- "columnsLayout": [
- {
- "property": "string",
- "disabled": true,
- "selected": true,
- "hidden": true
}
], - "filterLayout": [
- {
- "property": "string",
- "disabled": true,
- "selected": true,
- "hidden": true
}
], - "propertiesLayout": [
- {
- "property": "string",
- "disabled": true,
- "selected": true,
- "hidden": true
}
]
}Response samples
- 200
- 400
- 429
{- "createdTime": 1730204346000,
- "lastUpdatedTime": 1730204346000,
- "id": 1,
- "view": {
- "externalId": "string",
- "space": "string"
}, - "useAsName": "string",
- "useAsDescription": "string",
- "columnsLayout": [
- {
- "property": "string",
- "disabled": true,
- "selected": true,
- "hidden": true
}
], - "filterLayout": [
- {
- "property": "string",
- "disabled": true,
- "selected": true,
- "hidden": true
}
], - "propertiesLayout": [
- {
- "property": "string",
- "disabled": true,
- "selected": true,
- "hidden": true
}
]
}